数据分析丨SPSS准备篇
啦啦啦,萜妹的论文问卷终于达到了基础数量,撒花~所以,最近萜妹开始研究数据分析。
依旧秉承着共同学习共同进步的观点(其实是因为要教学妹,哈哈),萜妹决定做一个新手入门级的示例,希望也可以给小可爱们帮助呀~
Step 1 将原始数据导入、合并、整理
1、转化原始数据
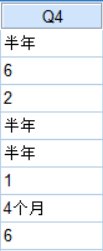
用问卷星导出的SPSS文件中,其中的部分题项,如:年龄和任职年限,有可能出现汉字,这时先要将它们全部统一成阿拉伯数字。


2、处理缺失数据
答卷中有缺失数据,可以用999或者其他特定数字表示,也可以根据其他答卷数据对缺失值进行估计。(第二种方法,萜妹还没试过,所以萜妹也不清楚怎么处理信度最高)


Step 2 命名变量
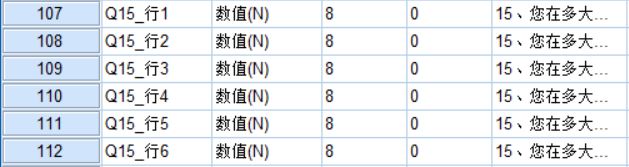
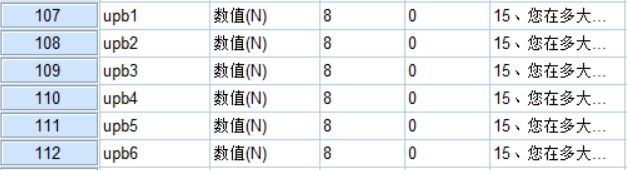
每一个题项对应一个变量。
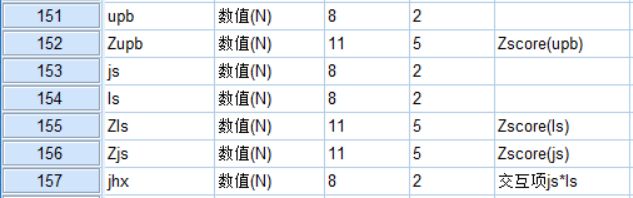
比如: 亲组织非伦理行为有6个题项,这样就可以命名为upb1-6,当然其他命名方式也可以,自己能看懂就行~
Step 3 处理变量,产生新变量
1、由观测变量得潜变量
将变量的各个子项进行处理合并,即由观测变量得潜变量。
例:计算upb1-6均值,得upb的最终得分。
①【转化(T)】-【计算变量(C)】
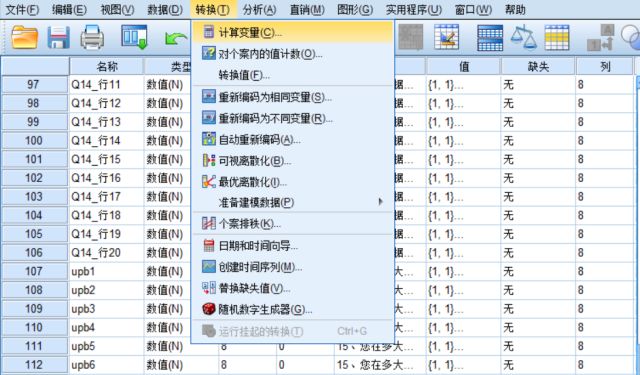
②目标变量,输入:upb;
③函数组(G),选择【统计量】-【Mean】;
④数字表达式(E),选择右侧upb1-6;
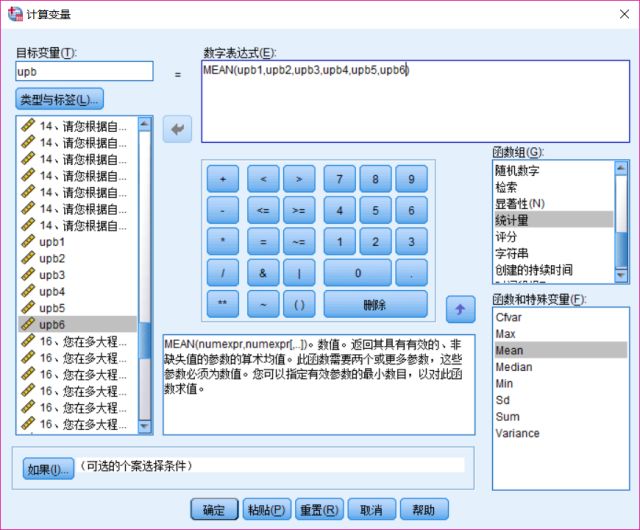
⑤确定,得新变量upb。

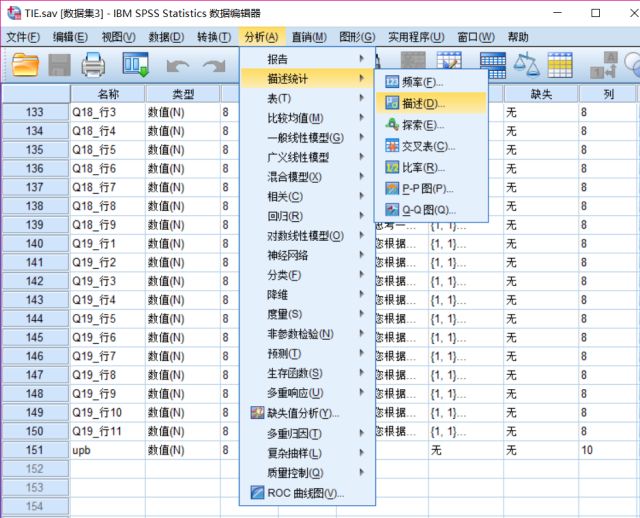
2、将变量标准化
对各个潜变量进行标准化,形成新变量。
例:对upb标准化,得Zupb。
①【分析(A)】-【描述统计】-【描述(D)】;
②从左侧选取upb至右侧,并勾选左下角;
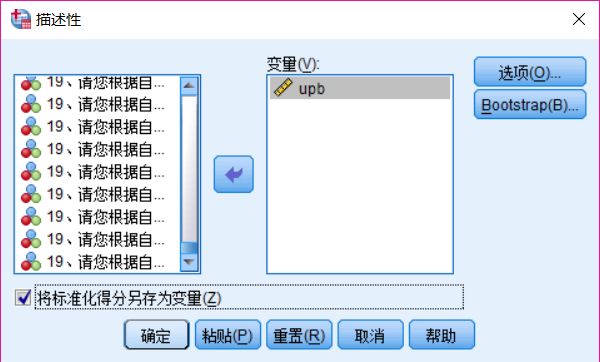
③确定,得新变量Zupb。

3、建立交互项变量
为检验调节效应做准备,建立新变量。
例:检验工作满意度(js)对自我损耗(ls)和亲社会非伦理行为的关系的调节作用,建立工作满意度和自我损耗的交互项。
①【转化(T)】-【计算变量(C)】
②目标变量,输入:jhx;
③点击类型与标签,填上便于识别的标签;
④数字表达式,输入Zjs*Zls;
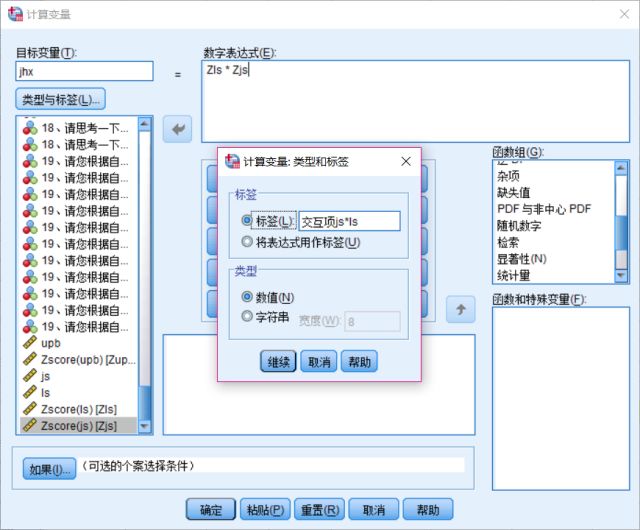
⑤确定,得新变量jhx。
大概做到第三步,准备工作就可以告一段落。接下来就是数据分析的部分了。
数据分析部分的操作,萜妹也只掌握了一丢丢的皮毛,要说吃透那还远远不够。有的数据跑出来的结果,萜妹还没办法去解释,所以这几天的萜妹正努力的回忆以及消化重庆学习时的理论。
萜妹想传播出来的干货都是客观且正确的,萜妹希望知其然并知其所以然。因此呀,小可爱们可能要多给萜妹一些时间,让萜妹给你们一份更有依据的干货。那么,结论是,今天的干货就到这里了哟~
小可爱们,下次见~
原文链接: