Mplus丨基础使用指南
撸毕业论文的空隙,让自己休息下~
所以,萜妹开始着手写之前答应小可爱们的Mplus推送啦~
以下内容主要分为三个部分:基础知识、语句说明和结果解读~
基础知识
文件格式
Mplus主要涉及的文件格式有三种,其中input是输入文件,在编写语句时保存后才可以运行;output是输出文件,这个就没什么好说的了;dat是数据文件,最好和input文件放在同一个文件夹,原因后面说~
格式转换
由于Mplus只能打开ASCII格式的文件(.dat和.txt),所以SPSS常用的.sav格式的文件无法被读取,我们要先将数据进行转化。
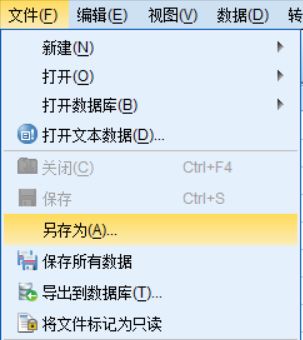
①打开SPSS软件,选择:文件-另存为;
②一般情况下,可选择“以制表符分隔”,数据量较大时,可选择“固定ASCII格式”;
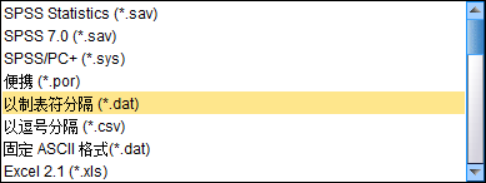
③注意不要勾选“将变量名写入表格”这一项;
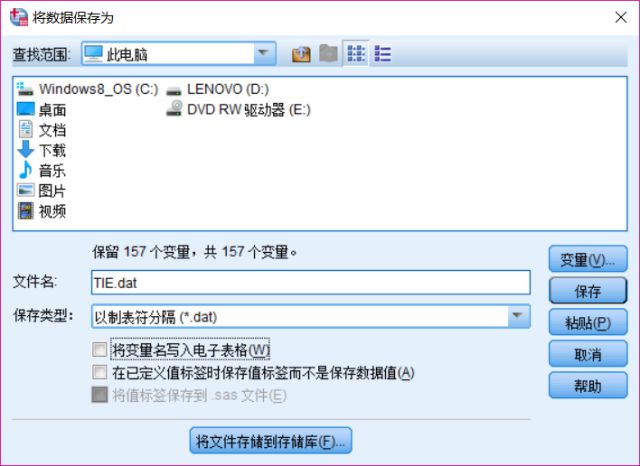
④点击保存即可。
语句说明
加粗部分为固定格式。
! 后内容为注释,软件不会读入。
标题
TITLE: example
自己给当前数据分析程序取个名称。
数据
DATA:File is c:/mplus/example.dat;
用于指定数据文件存放的位置。
如果.dat和.inp在同一个文件夹,可以直接输入文件名字;如果不在同一个文件夹中,就只能输入储存路径。
变量
Names are ID X1 X2 X3 Y1 Y2 Y3 Z1 Z2 Z3;
定义数据文件中的变量。数据文件中所有变量,一个个给它命名。
Usevariables are ID X1 X2 X3 Y1 Y2 Y3;
选择稍后分析时,需要使用的变量。
Missing are all (*9999*);
所有的缺失值都用9999来表示。
Within: X1 X2 X3;
用于两水平模型中定义组内水平变量。
BETWEEN: Y1 Y2 Y3;
用于两水平模型中定义组间水平变量。
CLUSTER is ID
按ID进行分组。
Define: x=mean(X1 X2 X3);
y=mean(Y1 Y2 Y3);
Define命令可以生成新的变量。
分析
Analysis:
Type = general; !默认分析类型:一般
= twolevel; ! 两层模型
= mixture;!混合模型
= efa;探索性因素分析
Type为分析类型。
Estimator = ML;! 默认参数估计方法
= MLM;!适用于非正态数据
= MLMV;!适用于非正态数据
= MLR;!适用于非正态、非独立数据
= WLS;
Estimator为参数估计方法。
ML:极大似然估计(Maximum Likelihood),当因变量为连续变量时,为Mplus默认参数估计方法;
MLM:极大似然估计伴标准误和均值矫正的卡方检验;
MLMV:极大似然估计伴标准误和均值-方差矫正的卡方检验;
MLR:稳健极大似然估计,适用于复杂数据结构,与Type=complex合用;
WLS:加权最小二乘法估计。
模型
Model:
常用的字符(红字)及其代表关系如下:
BY:定义潜变量,如:f1 BY x1-x3;即因子f1由x1、x2、x3三个显变量测量;
ON:定义回归关系,如:f1 ON x1-x3;即可用x1、x2、x3三个变量预测f1;
PON:定义配对回归关系,如:f1 f2 PON f3 f4;等价于f1 ON f3; f2 ON f4;
WITH:定义相关关系,如:f1 WITH f2;即因子f1与f2相关;
PWITH:定义配对相关关系,类似PON;
List of Variables:定义变量方差和残差方差,如:X Y M;当变量为自变量时表示方差,当变量为因变量时便是残差方差;
[List of Variables]:定义均值、截距,如:[X Y M];估计X Y M的截距;
:将默认设置改为自由估计,设置初始值,如:[f1];自由估计因子f1的均值,f1 BY x1*1;自由估计变量x1的载荷,初始值为1;
@:固定参数,如:f1@1;即固定因子f1方差为1;
(number):限定参数相等,如:x1(1);x2(1);即x1、x2方差相等,f1 BY x1-x3(1);即x1-x3的因子载荷固定为相等;
(name):命名某参数,如:M ON X(a);即X对M的回归系数命名为a;
丨:定义随机效应变量,与ANALYSIS中的TYPE=RANDOM连用分析随机系数模型,如:s丨y1 ON x1;即s代表随机回归系数;
MODEL INDIRECT:描述间接效应;
IND:定义间接效应,ind左边为因变量,右边最后一个为自变量,右边其他变量为中介变量,如:Y IND M X;表示自变量X通过中间变量M对因变量Y的间接效应;
VIA:描述一组包含特定中介变量的间接效应,与ind相似,左边为因变量,右边最后一个为自变量,右边其他变量为中介变量,VIA指定的是所有经过中介变量由自变量到因变量的间接效应;
MODEL CONSTRAINT:模型设定命令;
NEW:对设定命令中需要使用的新变量命名,生成数据文件中并未出现过的变量,如:NEW(c);c=a*b;即c为a、b的交互项。
输出
Output:
常用的Output命令(红字)如下:
SAMPSTAT:连续变量时要求报告均值、方差、协方差和相关系数;
**CROSSTABS:**报告类别变量间交叉频率表;
STANDARDIZED:报告标准化结果,常见的三种标准化结果分别为:STDYX、STDY、STD;
RESIDUAL:报告观察变量的残差值;
MODINDICES:报告模型修正指数和期望参数变化指数;
CINTERVAL:报告参数置信区间;
Mplus还有14个技术报告分别是TECH1-14,有兴趣的小可爱们可以自行查阅。
结果解读
以检验中介作用为例。
原始语句

首先,输出的结果部分会把input输入的语句显示出来。
分析概况


数据概况
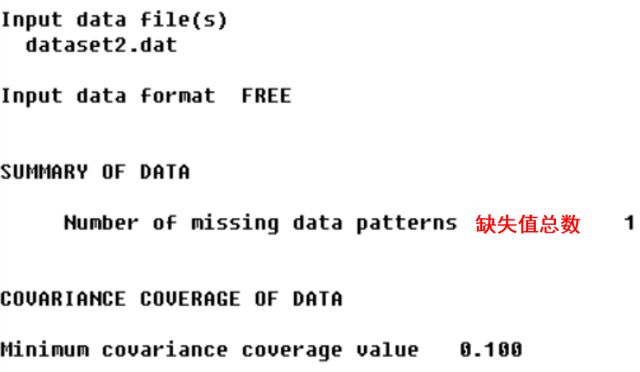

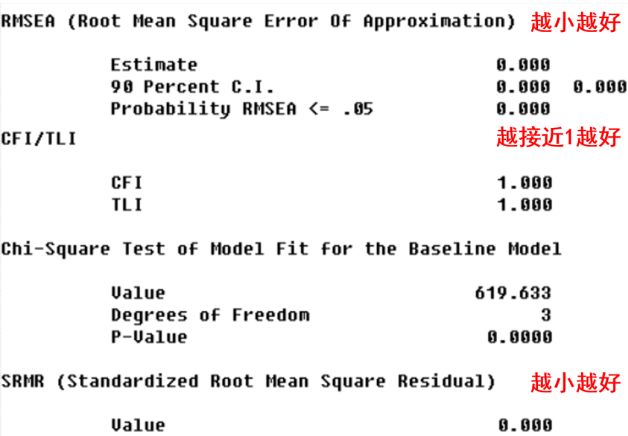
模型拟合

卡方值/自由度要自己手动算。
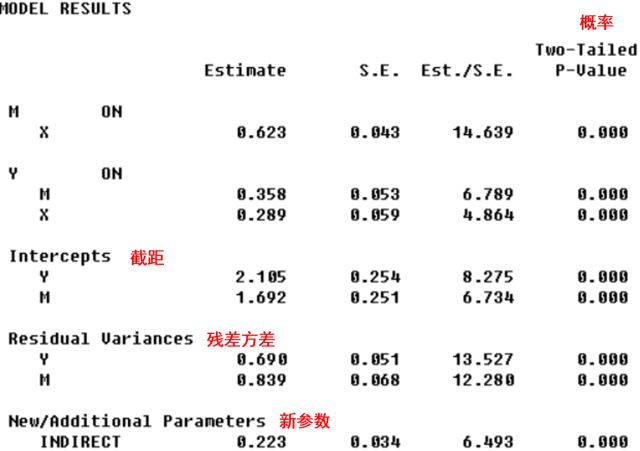
模型结果

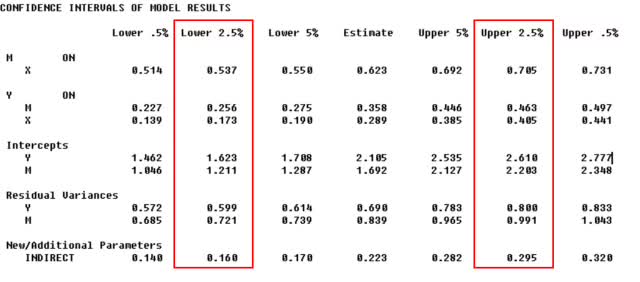
95%的置信区间不包含0,则存在效应。
说好两天内更新的推送,最后又被我拖到了周更,好险萜妹还是写完了它。
写这篇的灵感就是上篇的多层线性模型实践,当时花了好长时间才搞懂要看哪些数据、要怎么看数据,所以想把这些自己磕磕绊绊的经验总结起来分享给大家(这意味着笔记系列四月前肯定更不完了,哭)~
总的来说,萜妹觉得这篇推送应该可以让大家对于Mplus有个大致的了解,当然有任何问题都欢迎跟萜妹交流哇~
最后想说的一点题外话是,这一个月以来萜妹几乎所有的推送都是数据分析,一方面因为通过数据分析,越来越多的陌生人知道萜妹,所以想给这些人回馈;另一方面是自己说好的四月FLAG,虽然从数量上看起来和我之前周更没差,但是每篇耗时耗力跟以前比真是成倍数增加,再加上毕业论文的大山,所以萜妹很难抽出时间精力来写其他内容的推送。
但是还是想告诉那些一直陪伴我的小可爱们(虽然我觉得这类小可爱不太可能点开这篇推送,更不可能耐心看到这里,捂脸哭),萜妹还是以前的那个萜妹,还是那个灵魂灰常有趣的少女呀,所以下期,我们可能就会来一点轻松又愉悦的话题啦。
小可爱们,下周见~
原文链接: