Meta丨元分析基础介绍
啦啦啦,这是一个新的笔记系列。不过它没办法跟2017重庆系列相提并论,这次呢大概就只会有2-3篇的内容,所以希望萜妹能及时更完哟。
定义
元分析是对来自多个实证研究的信息进行定量组合,以估计关系的总体规模或干预的影响。
提供原始数据的研究被我们称为初级研究(primary studies)
特点
元分析需要满足以下几个特点:
- 明确的(Explicit);
- 系统的(Systematic);
- 透明的(Transparent);
- 可重复的(Reproducible);
- 无偏见的(Unbiased);
其中,萜妹认为最为特殊的特点是无偏见性。它要求研究者无视期刊等级,将所有的数据一视同仁。
而其实以上的特点都是为了保证参考文献的全面及合理,因为引用文献不完整是元分析被拒稿的一个重要原因,因此在引用时,大家一定要详细标明引用的时间、数量等相关信息。
具体的写作要求,小可爱们可以看看APA style manual: Meta-Analysis Reporting Standards (MARS),该内容可自动回复获得。
条件
元分析适用于以下这些初级研究的合集。
-
是经验性的,而非理论性的;
(所以定性分析的结果不能被整合分析)
-
在结构和关系方面是可比的;
(完了,萜妹的笔记里也没写可比性的含义,所以这个的解释暂且存疑哈~)
-
进行元分析的数量是足够的
(一般引用量为30-80,有时候也会出现个别类别下无文献的情况,目前已发表的元分析文件中,最少的是19篇)
类型
目前有关元分析的研究主要分为两类。
小可爱们可以通过阅读LePine et al. (2005)和Judge et al. (2001),这两篇文章来感受一下,这两类的不同。
| 文献 | LePine (2005)AMJ | Judge(2001)Jap |
|---|---|---|
| 分析策略 | 将Meta作为工具解决问题 | 单纯的梳理过往逻辑 |
| 例子 | 将压力类型分为两类,用以往数据验证自己构建的模型。 | 收集以往研究人格的完备文献,总结现有研究成果。 |
| 难点 | 寻找核心科学问题较难;有一好的题目后,相对好发。 | 找他人没做过又有意义的问主题其实并不简单。而且因为容易和他人撞车,所以讲求速度。 |
右侧代表的是最常见的元分析类型。这种元数据的典型研究问题是“xxx与其前因缘/结果之间的关系是什么?”它也经常被称为“系统审查”。
左侧代表的类型使用元分析作为测试研究问题的工具。从这个意义上说,我们并不是在做元分析,但是却在用元分析技术测试你的假设。
关键概念
有关元分析的关键概念主要有3组,分别是效应量、抽样误差和固定误差与随机误差。
一、效应量:它是元分析中的项目单位。
效应量大致可分为三组:r组、d组和OR组。
| R | d | OR |
|---|---|---|
| 相关系数 | 标准平均数 | 概率比/风险比 |
| 用于问卷调查 | 用于实验法 | 用于二分法的数据 |
| 例子:工作满意度与工作绩效之间的相关性系数 | 例子:一个人的领导效能在一个特定的领导计划前后的差异 | 例子:使用烟草组和不使用烟草组生存(与死亡)的几率 |
以上三组效应量可以由下面的网站中计算转换。
http://cebcp.org/practical-meta-analysis-effect-size-calculator/
不使用其他的指标是因为:①t检验、z分数、卡方值,因为与样本量有关,所以被污染了;②B值,因为与其他的自变量有关,所以也被污染了。
二、抽样误差:抽样统计量与相应的总体参数之间的差值。
抽样误差是一种随机误差,但是在元分析中,它可以被预测。
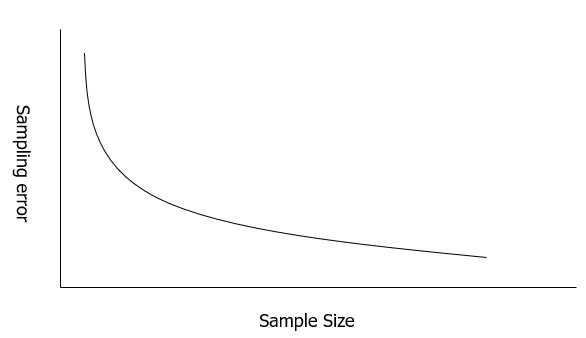
抽样误差的决定因素有两个,分别是样本量大小与总体估计(翻译过来有点奇怪,萜妹把它理解成是真相的显著性)。
- 当样本量无限大时,抽样误差为零,其抽样估计实际就可被看作是总体参数。所以数据量大的样本所占权重应更高,因为其越接近真相。
- 而如果真相越显著,抽样误差也会很小。比如:打喷嚏时头会移动这种现象,这只需要调查几个人就能得到结果。
但是除了以上原因外,还有一些人工的因素可能会影响误差结果,如:测量误差,范围限制,不完善的结构效度,转录误差等。
- 转录错误包括原始数据可能在数据输入中输入错误、在处理和分析数据时可能会出现错误、作者在记录结果时可能会出现印刷错误……
除了人工的方差,我们还对系统的方差感兴趣,又称为moderator。
注意:这里的moderator和我们日常说的调节不是一个意思,只是一个单词啊。
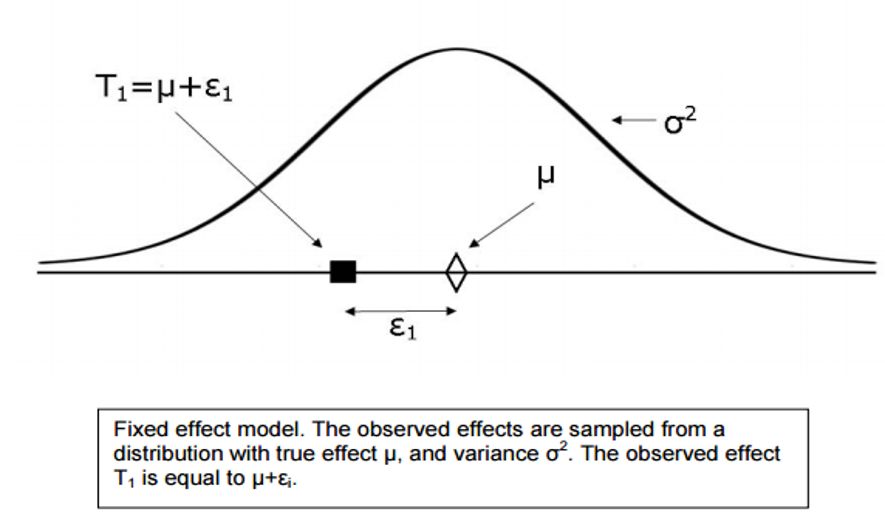
三、固定效应模型会和随机效应模型
固定效应模型假设所有效应大小之间的变化都是由于抽样误差造成的,换句话说,效果大小的不稳定性仅仅是由于主题级别的“噪声”造成的。
随机效应模型假设效应大小之间的变异性是由于抽样误差加上效应总体的变异性。换句话说,影响大小的不稳定性是由于受试者级别的“噪声”和不同研究之间真正的未测量的差异(也就是说,每个研究都在估计一个略微不同的人群影响大小)。
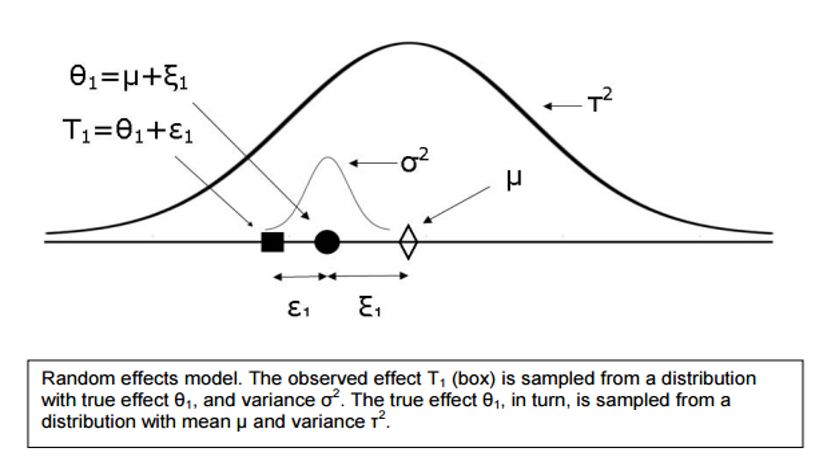
通俗的说,当真相只有一个时,比如一个人的身高具体是多少,就用固定效应模型;反之则使用随机效应模型。实际上,在管理学的研究中较多使用的都是随机效应模型。
啦啦啦,元分析基础理论介绍到这里就先告一段落了。接下来,萜妹的初步打算是会写一篇分析原理与一篇示例。希望可以按时完成哇~
最近的学业压力莫名巨大,所以,结尾的话我们就不多说了,小可爱们,我们下周见吧~
原文链接: