量表开发基础指南
啦啦啦,由于好多小可爱们都用不到QCA,以及最近萜妹身边的学弟学妹们正面对着毕业的压力,所以萜妹准备插更几周的数据处理(虽然好像有点晚了,哈哈哈)。
其实更这个呢,是因为萜妹前阵子在做量表开发,最近刚弄完,就趁着还记得的时候写下来好了。
以下整个示范会以我的量表为例,但是由于涉及萜妹的研究,所以具体数据就不跟小可爱们分享啦~
那我们开始吧。
原始题项构建
量表原始题项的获取,一般主要是这三种方式:
- 深度访谈
- 开放式问卷
- 现有研究量表
每个的具体操作要根据研究的具体问题来设计,所以这里萜妹也没有太多的建议给到小可爱们。
最后我主要是采用的开放式问卷以及参考现有量表的方法,构建了46道原始题目。
ps:题目这么多是因为我有7个小类,而且问卷发放的时候还会加入效标变量,以及其他相关的变量的测量,所以想要把所有的问题控制在100题以内。这46就真的不算多了。小可爱们自己的数量设定看大家自己的研究吼~
初始题项检验
设计好整个问卷后,要先做一次预调研,之后对结果分析,再删减题目,下面是删题目的步骤。
计算CITC
项目总体相关( CITC )是用来净化垃圾测量条款的常用方法。
项目净化标准有两条 :
- 第一,剔除该项目可能显著增加总体Cronbach ’ s α 系数,以提高测量量表的总体信度 ;
- 第二,项目总体相关系数小于 0 . 35。 有的学者认为临界值应该是0.4,也有认为0.3的,所以也是小可爱们自己取舍吧。
具体操作:(SPSS)
(1)测量内部一致性的操作:
①【分析】-【度量】-【可靠性分析】;
② 将需要的变量选入右侧目标区域;
(2)点击右侧【统计量】按钮;
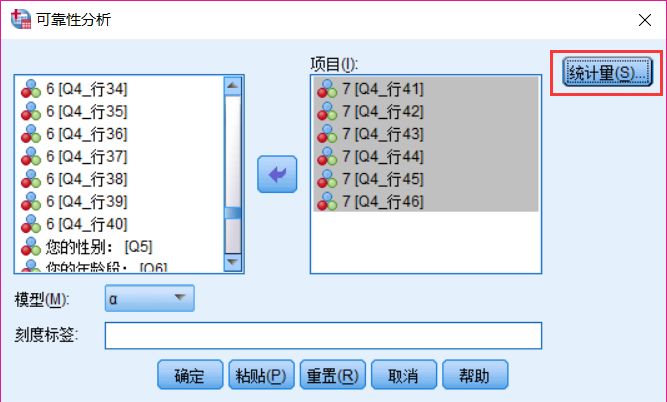
(3)勾选【如果项已删除则进行度量】,并点击【继续】;
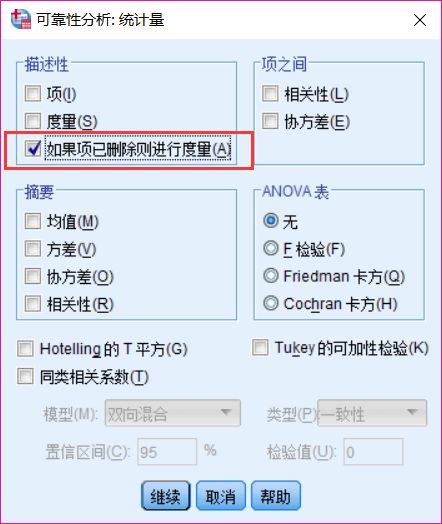
(4)结果:看红框内是否有数值小于临界值,如果有则删除题项;反复操作直到稳定。
ps:由于萜妹我自己的量表结果还不错,所以我又找了一个没那么好的,让小可爱们看看反面例子。
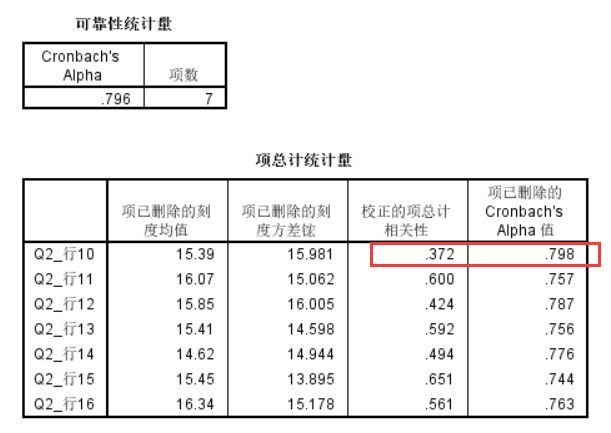
这里明显第十题的结果不好,所以需要删除。
计算项目区分度
项目区分度反映了测验项目对被试特质水平的鉴别力,是对项目进行评价和筛选的主要指标,。常用的项目区分度的检验指标包括:极端分组的决断值(Critical Ratio值)和鉴别力指数值(D值)。
具体操作:(SPSS)
(1)对原始题项求和或取平均,得量表最终得分值;
(2)找出量表得分最高的27%与最低的27%的标准线,并以此为依据划分出高分组与低分组。
①【转换】-【个案排秩】;
② 将量表得分选入右侧,点击【秩的类型】,左下角将秩1设定为最大值或最小值看个人喜好,萜妹喜欢最大值为1,所以我改了,小可爱们也可以不改。
③ 选择【%分数秩】,点击继续和确定,将会生成一个新变量。
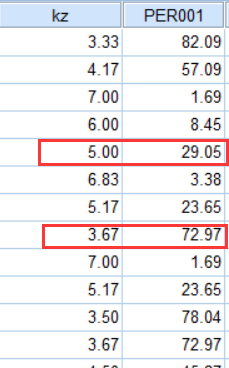
④ 对应新变量就可以确定高、低27%的分界线。
(3)根据标准线对量表得分重新编码:
①【转换】-【重新编码为不同变量】
② 给新变量命名,并点击【更改】;
③ 点击【旧值和新值】
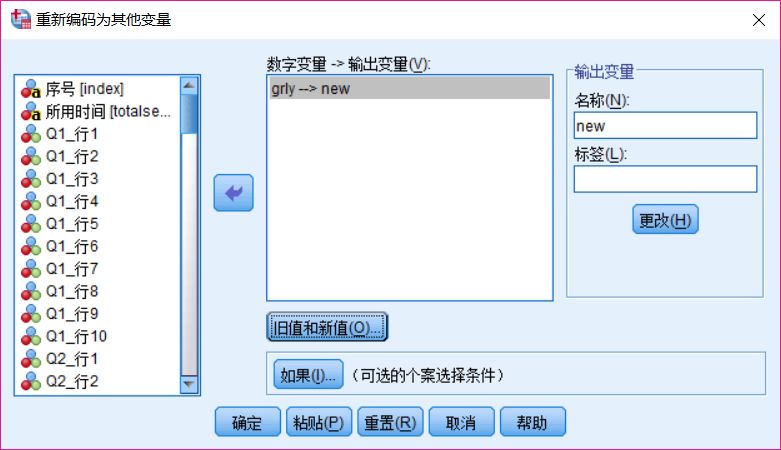
④ 旧值选择【范围,从值到最高】,填入5,新值填入1,点击【添加】;
⑤ 旧值选择【范围,从最低到值】,填入3.67,新值填入2,点击【添加】;
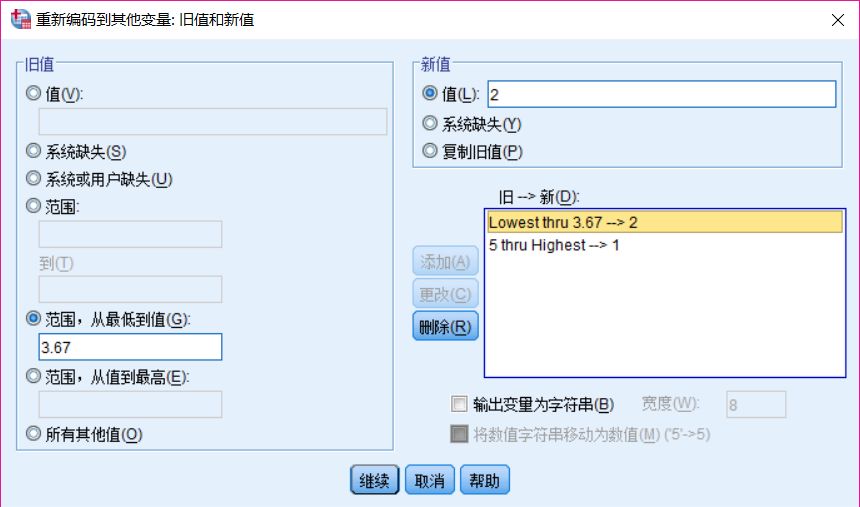
⑥ 点击【继续】,回上一界面,点击【确定】,可得新变量。

(4)计算CR值:对以新变量为分组标准对该量表各原始题项进行【独立样本T检验】:(干货丨论文写作常用数据分析里面的第二部分中有具体介绍)
检验标准:CR值即为两者均数差异检验的t值。当值达到显著水平时,表明该项目对不同被试的特质水平能有效鉴别如CR值达不到显著水平,则表示该项目鉴别度较差,应考虑予以删除。
(5)计算D值:以新变量分组,计算两组被试的项目得分率,用高分组的项目得分率减去低分组的项目得分率即为鉴别力指数值。D值越大,表示项目的鉴别力越大,质量越好。
检验标准:0.40以上,区分度很好;介于0.30和0.40之间,区分度较好;介于0.20和0.30之间,区分度尚可;小于0.20,区分度差。
ps:量表的得分率怎么算,萜妹还没搞懂啊,所以这个部分只有原理没有操作,尴尬。
探索性因子分析
这个部分其实萜妹之前有讲过的,不记得的小可爱们可以去干货丨论文写作常用数据分析里面的第三部分查看(点红字跳转哟~)
萜妹自认为那篇里头的这个部分已经写的很详细了,所以这个部分不再说了。
反正重点的部分就是看【旋转成分矩阵】,如果存在一道题在多个因子上负荷超过0.4,就可以说存在交叉载荷的现象,该题项就需要被删除。
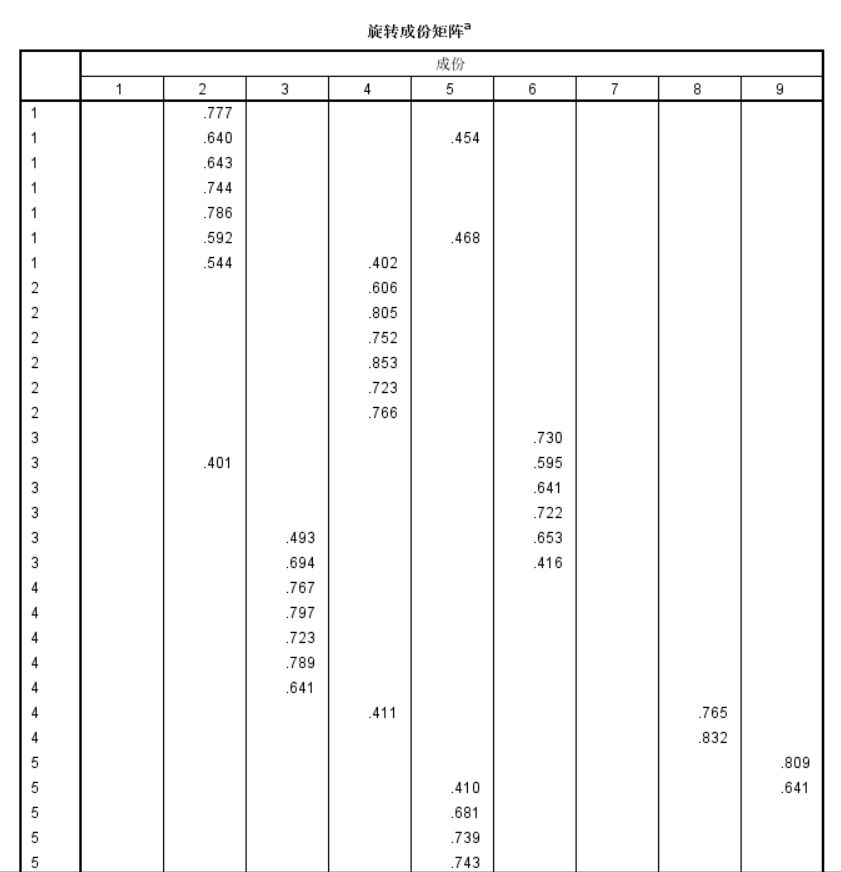
啊,我题目截不全,小可爱们就象征性的看一下,大概是这样。之后就把跨载荷的题项慢慢删除,直到不会出现跨载荷的情况为止。
ps:这里要提醒小可爱们的是,慢慢删啊,尤其是不要一步到位,因为一步到位的删法很有可能最后题目骤降。而且在删的过程中,可能之前跨载荷的题目突然就不跨了,这样就不用删了,所以我们还是一个个删比较好,这样节约题目。
最后萜妹考虑到问卷数量的均衡性还有题目太多会很磨人,于是最后形成了4*7共28题的最终量表。
最终题项检验
因为萜妹的论文并不是专门为了开发量表而写的,量表开发是辅助手段,最终还是要证明我的其他假设,所以我确定了最终28个题目,再正式调研后的数据分析和往常并没有什么不同,这里就不再详细说明了。
大部分的小可爱应该跟萜妹一样,并不是专门靠开发量表就写一篇文章,所以按照我这篇的整个步骤还是可以勉强搞定啦,但是如果有真的很想专门就做量表开发的小可爱的话,萜妹在文末推荐几篇我看过的觉得很不错的有关量表开发的文章给小可爱们自行学习啦~
啦啦啦,文章写到这里就差不多结束啦,以前介绍过的内容,萜妹这里就都跳过了,毕竟重复的内容不想说太多次啊,嘤嘤嘤。
之后想说的是,其实这篇推送是非常入门的量表开发说明,萜妹在准备推送的过程中又专门看了几篇论文,然后觉得量表开发其实还是十分有难度的啊。
另外就是看的两篇英文文章范式不一样,但是都觉得有值得学习的地方,想分享给小可爱们,然而英语能力有限,我还在纠结要不要作这个死,所以有可能下周会是与量表开发有关的阅读笔记。(画重点,只是有可能!)
还有就是最近萜妹意识到一件事情:因为现在推送越来越多,新来的小可爱们可能找不到我之前写过的内容,所以萜妹有时间的时候可能会把以前的推送做一个整理合集(当然,前提是有时间!)
所以到最后我也还没想好下周更新什么,不过我总会想好的,哈哈哈~
那小可爱们,下周见~
推送中主要参考及推荐的文献有:
赵书松. (2013). 中国文化背景下员工知识共享的动机模型研究. 南开管理评论, 16(5), 26-37.
郑显亮(2010). 大学生网络利他行为:量表编制与多层线性分析. (Doctoral dissertation, 上海师范大学).
Djurdjevic, E. , Stoverink, A. C. ,& Klotz, A. C. , et al.(2017). Workplace status: the development and validation of a scale. Journal of Applied Psychology, 102(7), 1124-1147.
Strauss, K. , Griffin, M. A. , & Parker, S. K. . (2012). Future work selves: how salient hoped-for identities motivate proactive career behaviors. Journal of Applied Psychology, 97(3), 580-598.
小可爱如果有兴趣,可以自己下载查看~
原文链接: