QCA丨模糊集
啦啦啦,终于要开始介绍模糊集啦~
首先,萜妹怕基础篇过去太久小可爱们忘了这三类的区别,所以我先带小可爱们回顾一下。
| 类型 | 名称 | 变量范围 | 变量值格式 |
|---|---|---|---|
| csQCA | Crisp-set | 清晰集 | 二元的present(1)和absent(0) |
| mvQCA | Multi-value | 多值集 | 多元的离散的数字:0,1,2,3,4 |
| fsQCA | Fuzzy-set | 模糊集 | 连续的0~1之间精细的刻度值 |
之后呢,因为我们前面的所有示范都是清晰集的,所以相信小可爱们对清晰集已经有了比较深刻的理解,这里就不再赘述了。萜妹接下来主要介绍多值集和模糊集。
多值集(mvQCA)
清晰集的弊端
多值集的出现是因为清晰集存在弊端,比如:
- 之前的民主生存案例,最后的处理超越了 Lipset的理论的简单测试, 加入了一个该理论范围之外的条件;
- 纳入了大量的受人质疑的“逻辑余项”;
- 难以获得足够简约的最小公式,可能因为条件必须从一开始就被二分。
此外,有些情况并不适合使用清晰集。Eg:交通灯(红黄绿)不会同时出现111和000的状态,所以用二分并不恰当。
多值集的弊端
目前软件尚未开发完善,所以多值集的一致性需要手动算,而且还难算。
解决方式:可将多值集转换为模糊集。
模糊集(fsQCA)
模糊值是指多大程度属于xx条件,如:多大程度觉得自己属于高收入群体,所以取值在于0~1之间。
这里就会涉及一个概念,即交叉点。
交叉点:
定义:交叉点0.5 是属于或者不属于一个集合时的最大模糊点(fuzziness),即取0.5时不知道该将其归类为属于或不属于。
问题:如果有大量的0.5,机器无法判断,那么将无法代入进入。
Eg:100数据里头有60个0.5,那么只有40个数据在被计算。
解决方式:所以针对上述容易出现的问题,小可爱们在设定交叉点的时候可以参考以下技巧。
- 问卷数据:李克特5点量表转换的时候,不要用3转0.5,用2.9或者3.1,这样可以避免0.5。
- 具体数据:交叉点设置的时候,要在平均数或者中位数上下浮动一点,这样避免产生太多交叉点。
校准:
因为模糊集的特殊属性,模糊集相比于清晰集最大的不同在于多了校准的步骤。
校准的核心是利用Calibrate函数以及找出三个定性的锚点。
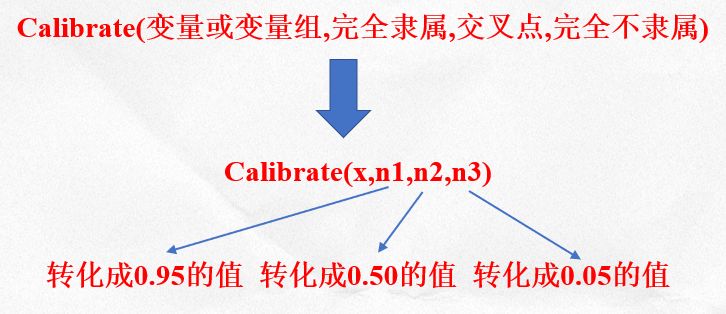
注意:在设置这三个点的时候,研究者需要给出理由。
三个点的设置与原始数据有关,比如看平均值、标准差、中位数……,
软件操作:
模糊集的求解是在原始数据录入后,多了一步校准步骤,具体fsQCA的操作如下:
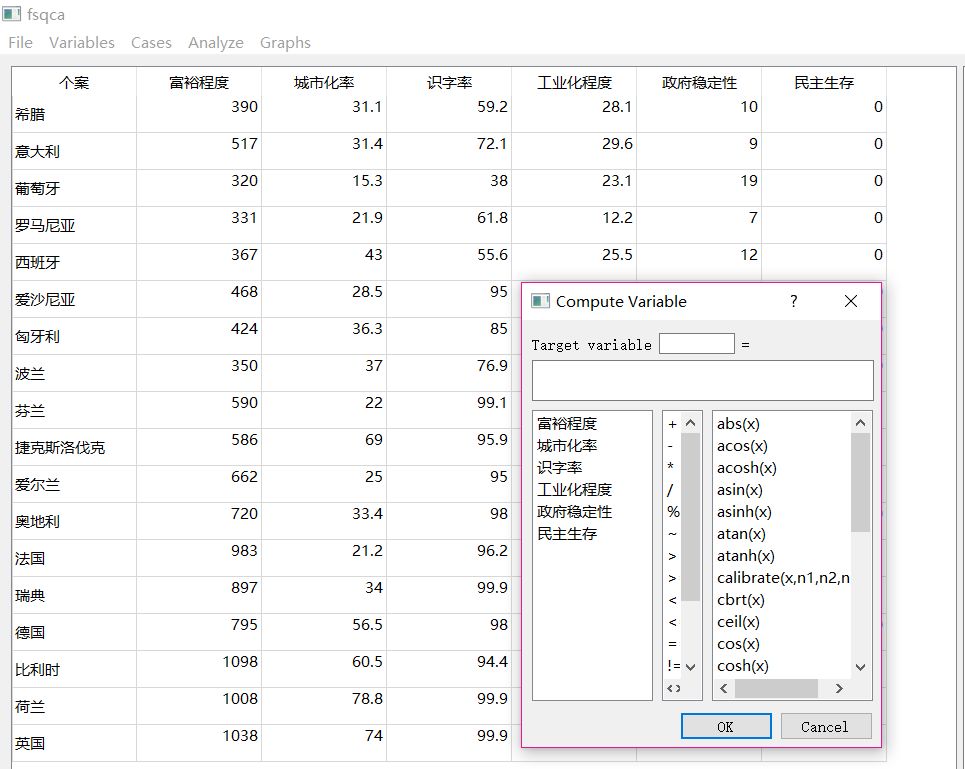
①导入原始数据后,点击【Variables】-【Compute】,如图。
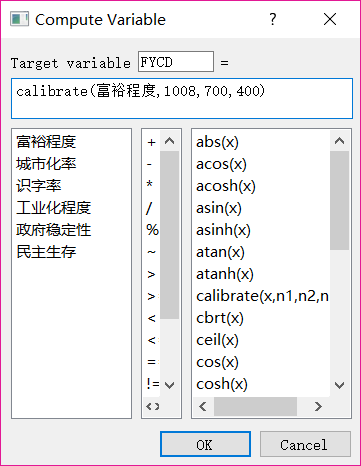
②第一个小空填写的是计算变量后生成的名字;第二个大空是写表达式:这里先在右侧选定Calibrate函数,并将各个部分对应填写。
③点击【OK】后,可以从数据视图中发现被校准过的变量。
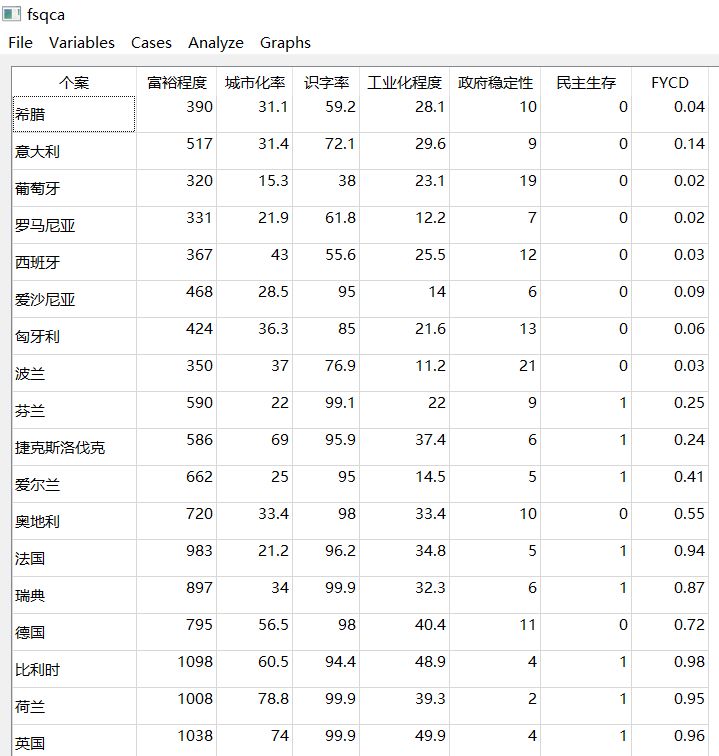
④后续把所有的变量处理完毕,再像之前一样求解就好。
啦啦啦,模糊集其实和清晰集的差别真的没有那么大,所以这次就不再重复已经说过的问题了。另外QCA这个系列可能还有一两次就会结束啦,剩下的内容不是非常的有体系,所以萜妹还在考虑后面的怎么呈现。
另外就是前两天萜妹又出去听了一个数据分析的培训,内容大概是跨层次分析和高级中介、调节。这个内容吧,其实萜妹之前的推送有写过,再写可能只是补充而已;另外,也有考虑介绍一些理论,毕竟技术和理论都是写文章必备的能力啊,所以就在纠结,是继续写操作还是去试试写理论,想看看小可爱们有没有什么建议呀~
不过下周还是QCA的介绍啦,嘻嘻嘻,那小可爱们,我们下周见吧~
原文链接: