被调节的中介
在开始写这个系列的推送之前,要先跟小可爱们解释一些问题:比如,明明已经介绍过了为什么又写一次?为什么两次介绍用的方法甚至是原理都有不同?实际操作时到底应该用哪种方式进行验证?
上一次的2017重庆系列介绍主要是基于温忠麟教授团队的研究成果,而这一次2019武汉的讲座主讲人是罗胜强教授。两边对中介与调节的理解可能存在细微差异,所以进行验证的方式有所不同。至于实际操作时,小可爱们应该用哪种,萜妹没办法给出建议,我觉得两种都有道理,小可爱们还是自行选择吧。萜妹这里的介绍只是给小可爱们一个多的选择。
还有就是当时培训的内容有跨层次分析、高级中介与调节、元分析,但是由于一些主客观因素,萜妹这次只会把高级中介与调节这个部分的笔记进行整理。
先告诉大家,这个系列应该不会很长,那我们现在开始吧~
注:以下内容属于我个人笔记,已加入主观理解,如在阅读中存在疑问,可后台回复“2019武汉”获得原始资料。
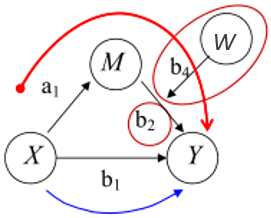
模型介绍
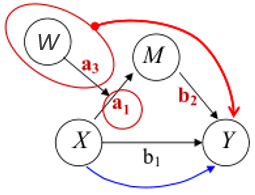
下图模型为被调节的中介。两条斜向黑线分别表示被调节的中介为前半段或/和后半段。
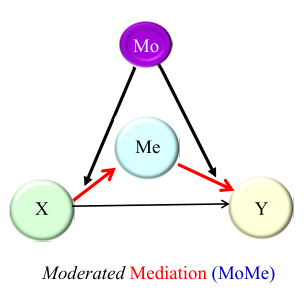
类型
上文已经提过被调节的部分可能为前半段、后半段或者两阶段。用模型图表示的对应关系如下:
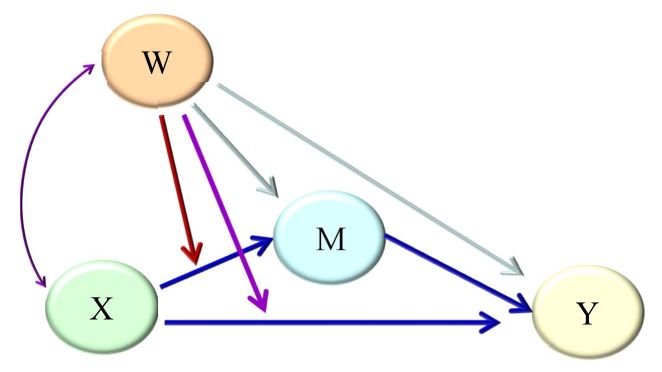
第一阶段的被调节的中介
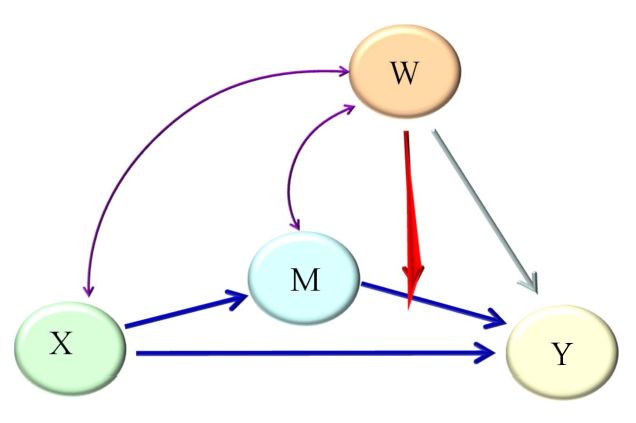
第二阶段的被调节的中介
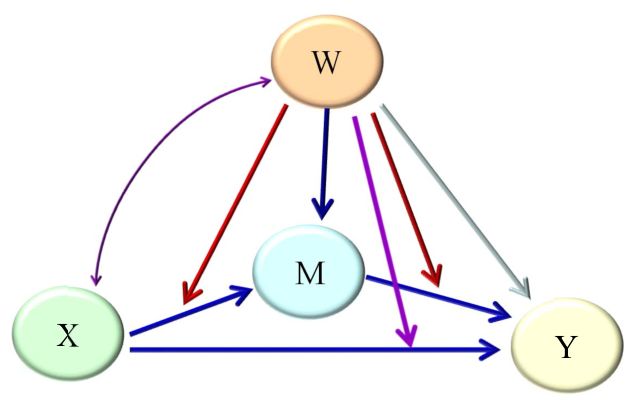
两阶段的被调节的中介
第一阶段被调节的中介
模型公式
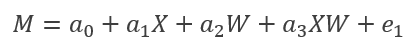
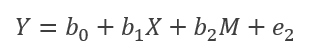
合并后:(标红部分为间接效应)
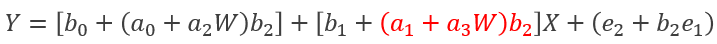
成立条件
由公式可得,间接效应量的大小取决于调节变量W的取值。
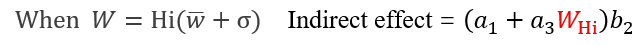
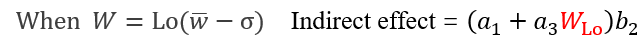
被调节的中介成立条件为间接效应量[(a1+a3W)*b2]随着*W*的取值将有显著差异。
Mplus操作程序
TITLE: mono-level first stage moderated mediation
DEFINE:
xw=(x - 3.1163)*(w - 3.2809);
! 这里减去的值为均值,需根据自己数据修改。
CENTER x m w (GRANDMEAN);
DATA:FILE IS example 1.dat;
VARIABLE:NAMES ARE x w m y;
USEVARIABLES ARE x m w y xw;
ANALYSIS:BOOTSTRAP=2000;
MODEL:
m on x (a1)
w
xw (a3);
y on m (b2)
x w xw;
MODEL CONSTRAINT:
new (ind_h ind_l ind_d);
ind_h=(a1+a3*0.8552)*b2;
ind_l=(a1+a3*(-0.8552))*b2;
! 这里的数值为W的标准差,需根据自己数据修改。
ind_d=ind_h-ind_l;
! ind_d为间接效应量。
OUTPUT: cinterval (bcbootstrap);
Mplus结果解读
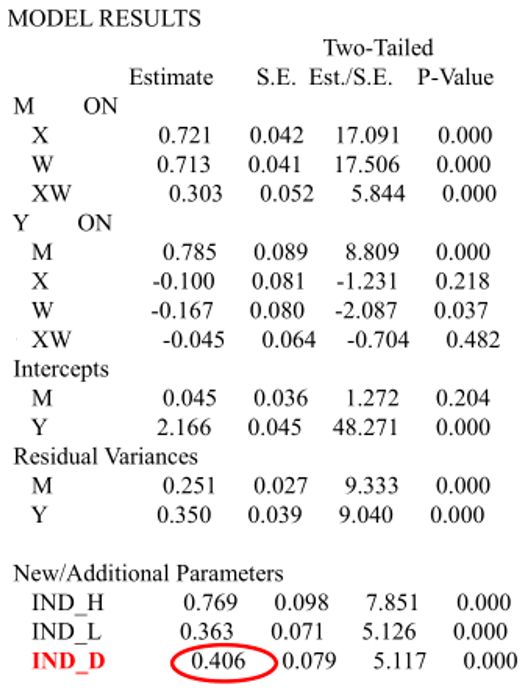
第二阶段被调节的中介
模型公式
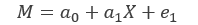
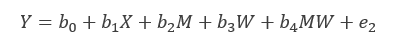
合并后:(标红部分为间接效应)
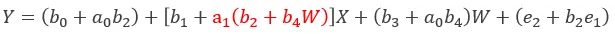
成立条件
由公式可得,间接效应量的大小取决于调节变量W的取值。
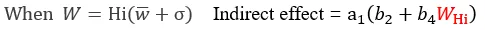
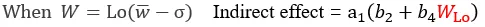
被调节的中介成立条件为间接效应量[a1(b2+b4W)]随着*W*的取值将有显著差异。
Mplus操作程序
TITLE: mono-level second stage moderated mediation
DEFINE:
mw=(m - 2.7560)*(w - 3.1505);
! 这里减去的值为均值,需根据自己数据修改。
CENTER x m w (GRANDMEAN);
DATA:FILE IS example 1.dat;
VARIABLE:NAMES ARE x w m y;
USEVARIABLES ARE x m w y mw;
ANALYSIS:BOOTSTRAP=2000;
MODEL:
m on x (a1);
y on m (b2)
mw (b4)
x w;
MODEL CONSTRAINT:
new (ind_h ind_l ind_d);
ind_h=a1*(b2+b4*0.8819);
ind_l=a1*(b2+b4*(-0.8819));
! 这里的数值为W的标准差,需根据自己数据修改。
ind_d=ind_h-ind_l;
! ind_d为间接效应量。
OUTPUT: cinterval (bcbootstrap);
Mplus结果解读
结果解读同上,这里就不再复述啦~
两阶段被调节的中介
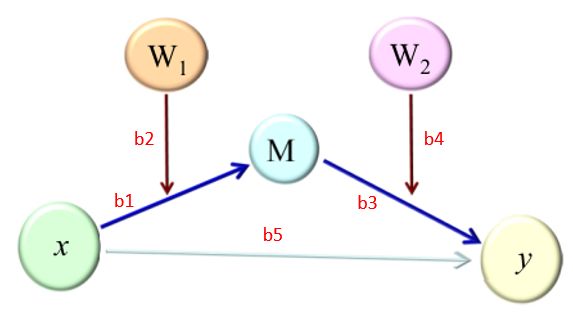
模型公式
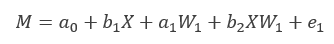
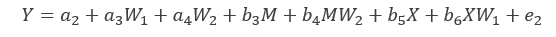
合并后:(标红部分为间接效应)
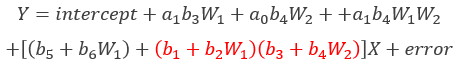
这里感兴趣的小可爱可以自己合并一下,不想算的小可爱记住这个结论也可以~
成立条件
同上,间接效应量的大小取决于调节变量W的取值。
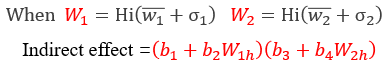
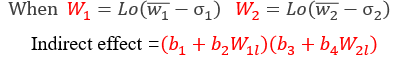
被调节的中介成立条件为间接效应量(b1+b2W1)(b3+b4W2)随着*W*的取值将有显著差异。
Mplus操作程序
TITLE: mono-level two stages moderated mediation
DEFINE:
xw1=(x - 3.1163)*(w1 - 3.2809);
mw2=(m - 2.7560)*(w2 - 3.1505);
! 这里减去的值为均值,需根据自己数据修改。
CENTER x m w1 w2 (GRANDMEAN);
DATA:FILE IS example 1.dat;
VARIABLE:NAMES ARE x w1 m w2 y;
USEVARIABLES ARE x m w1 w2 y xw1 mw2;
ANALYSIS:BOOTSTRAP=2000;
MODEL:
m on x (b1)
xw1(b2)
w1;
y on m (b3)
mw2(b4)
x w1 xw1 w2;
MODEL CONSTRAINT:
NEW(ind_hh ind_ll ind_d);
ind_hh=(b1+b2*0.8552)*(b3+b4*0.8819);
ind_ll=(b1+b2*(-0.8552))*(b3+b4*(-0.8819));
! 这里的数值为W的标准差,需根据自己数据修改。
ind_d=ind_hh - ind_ll;
! ind_d为间接效应量。
OUTPUT: cinterval (bcbootstrap);
Mplus结果解读
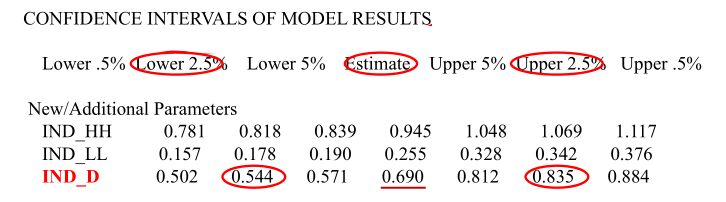
这是另一种解读方式,看Bootstrap法的置信区间是否包含0,不包含即可。
终于写完了这个部分了,虽然原定还要介绍Bootstrap法的原理,但是这篇真的写的萜妹超级累(就这么点内容竟然写了我五个小时!)于是我决定其他内容下次再写好了。
值得一提的是,这篇推送的所有公式都是萜妹重新手打的,合并的过程萜妹也检查过一遍。我感觉自己合并一下会更有助于理论原理,所以推荐小可爱们也自己动动手。
题外话:下周周末对萜妹来说是个纪念日,所以有可能写日常,也有可能写笔记,目前没想好,先知会小可爱们~那小可爱们,我们下周再见哟~
原文链接: