QCA丨模糊集校准步骤
啦啦啦,萜妹前段时间做了次模糊集QCA的数据分析,在实操过程中发现了一些讲座中没有提及的问题,也更深入的总结一些技巧。
所以萜妹想着结合自己的体验跟小可爱们分享下,要是有其他小可爱也做过模糊集QCA的话,也欢迎跟萜妹交流啊~
赋值校准
量表校准
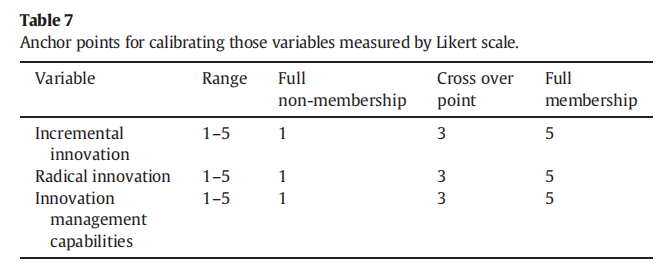
量表的校准通常是采用直接校准法,取最高值、平均值、最低值为完全隶属点、交叉项和完全不隶属点。例如likert 5点评分表的校准点就是5、3、1。
这里萜妹的参考文献是:Poorkavoos, M., Duan, Y., Edwards, J. S., & Ramanathan, R. (2016). Identifying the configurational paths to innovation in SMEs: A fuzzy-set qualitative comparative analysis. Journal of Business Research, 69(12), 5843-5854.

数值校准
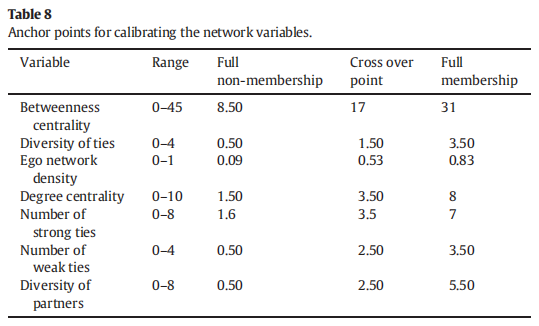
虽然理想的校准应该采用外部标准,即理论和实际知识,而非案例本身的数据。但是有时外部标准不明,所以有研究还是采取样本数据的百分位数决定的。
谭海波, 范梓腾, & 杜运周. (2019). 技术管理能力、注意力分配与地方政府网站建设——一项基于toe框架的组态分析. 管理世界, (9), 33-46.

所以目前找不到外部标准的时候应该还是可以这样处理的,毕竟顶刊都这样发了,对吧。
标准点计算
Excel算分位数
萜妹算95%和5%分位数会使用EXCEL软件,当然其他的软件也可。
EXCEL计算分位数的公式:=PERCENTILE(array, k) ,如:=PERCENTILE(H2:H33,0.05)。
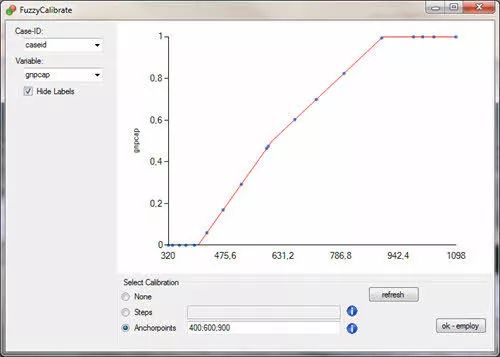
Tosmana算交叉点
很多文章里都有说是参考tosmana给出的建议值选取交叉点的。
具体的软件操作为:导入数据后点击【fsQCA】-【Calibrate】,再按对应选择即可。
听起来是不是很容易,但是萜妹换了好几组数据,以及重新去下了最新版本的tosmana也没做出来。心痛,不知道哪里出了问题。
不过,如果一切顺利应该就会得到美美的图和软件建议的数值啦。比如这样:
交叉点处理
这个部分萜妹之前也有说过,有时候为了避免交叉值被忽略会对交叉点进行处理。部分研究者通常在0.5的基础上增加或者减少一个微小数字以避免交叉点的出现。
当然,萜妹认为是加是减,是加0.01还是0.001要根据自己的原始数据。要看怎么样处理才能避免交叉项,不能处理完没有改变,那就没意义了。
至于这样处理的依据,萜妹参考的是:
Greckhamer, T. (2016). CEO compensation in relation to worker compensation across countries: The configurational impact of country‐level institutions. Strategic Management Journal, 37(4), 793-815.

小可爱们也可以去看原始的文章。
虽然这一方法从技术上能够轻而易举地解决案例归类问题,但是却显得过于主观和武断。操作后可能会使案例归属为不同的真值表行,解决办法是重新调整校准阈值(张明&杜运周,2019)
啦啦啦,这篇推送就结束啦。如果不是我下了快两个小时的最新软件,它应该能出现的更早。尤其是最后萜妹依旧没做出那个图就真的好气啊!
关于QCA,萜妹其实也还是刚入门的小垃圾。如果不是帮别人跑数据,萜妹也没有想过会有这些新问题。所以我也是在不断遇到问题、解决问题的自学道路上艰难前进。要是有小可爱有这方面的经验或者同样也这么艰难着,萜妹超欢迎大家跟我交流的,能解决我的问题就更好了!hhh
之后其实模糊集QCA方面,萜妹还有问题没解决,所以如果后续可以解决会再有这方面更新的。如果我一时半会解决不了,那下周就会更新一些mplus的语句范例。
那我们下周见啦~
原文推送: