前期准备丨多时点数据配对
上周我们完成了数据录入,这周要继续在Excel中完成剩余的准备工作,比如:配对。
多时点的数据匹配,最容易想到的方法是使用查找功能,一个一个的寻找,但是这样工作量很大。
萜妹则习惯利用Excel中的公式来进行整体的快速匹配。所以萜妹这篇推送主要分享一些配对过程中会使用到的Excel技巧~
另外则是会教小可爱们制作出《匹配模板》,以后如果再要用到就直接套模板,不用愁啦~
那我们开始吧~
(注:处理方式并非唯一,萜妹只是分享个人经验~)
来源:萜妹自制
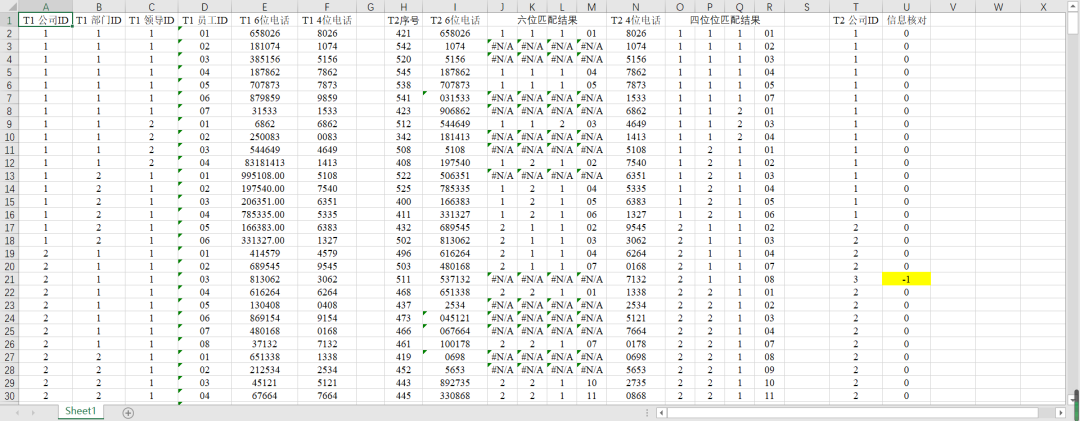
以下以500份多时点、多来源的数据为例。
核心公式
=INDEX(*A$1:A$500*,MATCH($I2,$E$1:$E$500**,0))**(注:加粗部分为固定部分,另外使用$是为了在公式填充时不变形)
- A1:A500:T1的ID集
- E1:E500:T1的电话号码集
- I2:T2的电话号码
所以该公式的意义是:先由Match公式定位到与目标电话号码相匹配的行数,再由INDEX公式根据行数找到对应的ID,最后将其输入在目标单元格中。
具体操作
其实整个配对过程都是基于上述公式。之所以还要写具体的演示,是因为在实际过程中我们会遇到很多有误差的情况,比如要求六位只填四位,或者某一项数字误填,等等。
所以在这里跟小可爱们分享萜妹的处理方式,也教大家如何制作Excel的配对模板,尽量利用公式不放过任何一个可能有用的数据。
具体步骤:
(1)新建一个Excel文档,为《匹配模板》;
(2)将T1的ID复制至《匹配模板》的A-D列;
- A列:公司ID
- B列:部门ID
- C列:领导ID
- D列:员工ID
这里也可以按照小可爱们自己的编号来。如果为单一来源的数据,可更改为T1的ID+人口统计学信息(注:需要两个时点都收集了的信息),比如:
- A列:员工ID
- B列:员工年龄
- C列:员工性别
- D列:员工教育程度
(3)将T1的电话号码复制至《匹配模板》的E列;
注意:复制的时候,改为数字格式。电话号码不要以文本的形式进行匹配,这可能会造成无法匹配。
(4)将T2的序号和电话号码复制至《匹配模板》的H、I列;(这里的序号是电子问卷自然生成的,如果是纸质问卷则手动编一下,就从1-500);
(5)用六位的电话号码进行匹配;
①在J2中输入:
【=INDEX(A$1:A$500,MATCH($I2,$E$1:$E$500,0))】
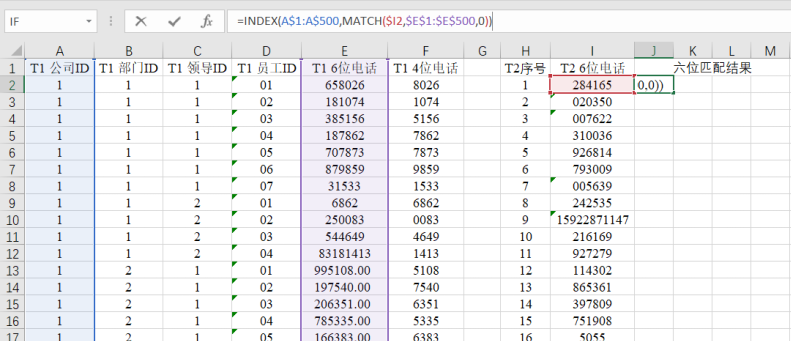
②将J2的公式填充至L501;
J2:L501的区域即为六位电话的匹配结果。
(6)用后四位电话号码进行匹配;
①利用公式提取电话号码后四位:
- 在F2中输入:【=RIGHT(E2,4)】
- 在N2中输入:【=RIGHT(I2,4)】
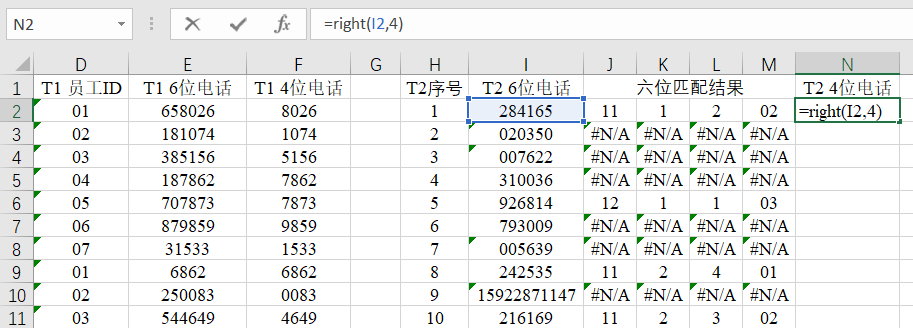
再将公式填充至第501行。
注:即使小可爱本身搜集的是四位电话,萜妹也建议大家做这一步。因为有特别实诚的被试会填完整的电话或者是6~8位电话,这种情况由于位数不一样,按第(5)步是匹配不出来的。所以进行这种操作有利于我们确保位数一样。
②类似于(5)步利用公式进行匹配;
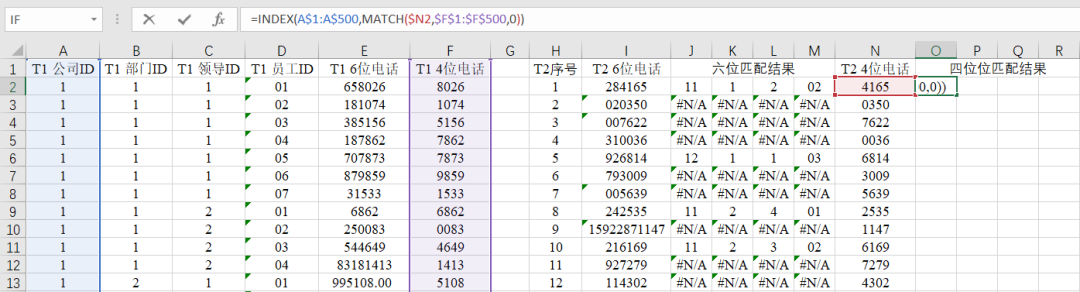
O2:R501的区域为四位电话的匹配结果。
(7)核对匹配结果;
将两次时点填写的公司/部门ID进行匹配;如果是单时点则将两次的人口统计学变量进行匹配。
①将T2填写的公司ID和部门ID复制至《匹配模板》的T、U列;
②在V2中输入:【=O2-T2】,并填充至V501;
③选中H~V列,按后四位匹配结果进行升序;
④筛选出V列≠0的个案;
此步可利用条件格式让结果更显著。
⑤手动核对两次填写的电话号码、人口统计学信息等,判断是否应该匹配。
有时候≠0是因为电话号码一模一样,但是第二次的信息乱填,这还是同一个人;也有时候是因为电话号码仅后四位一样,六位时则不同,这则不是同一个人。
注,利用公司/部门ID只是一种筛选的形式,也可以利用其他信息。萜妹这里主要是介绍这种可以快速识别的方法,小可爱们可以自行开发其他变种。
(8)将T1与T2的数据按公司/部门排序,手动核对未匹配的数据(这可以检查出漏网之鱼,不过应该只有个位数的误差)。
【重要提醒】:上述的(1)~(7)步就是制作模板的过程,当我们把模板制作好后再碰到配对,就只需替换对应的信息,公式什么的都不用修改啦~
补充说明
这个部分主要是针对有三个时点的调研,由于前两个时点的匹配肯定会造成问卷的流失,所以在时点三时,我会在(8)步前,加一个小步骤:用公式筛选出T2未被匹配的个案,再用T2的数据去找T3的数据,这样工作量小一些。
不过在T2和T1配对的时候,两次数据量差距不大的话,工作量则没什么差。
具体步骤:
(1)将所有ID合成一个ID
①在G2输入:【=A2&B2&C2&D2】,填充整列;
②在S2输入:【=O2&P2&Q2&R2】,填充整列;
(2)利用条件格式筛选未匹配的变量;
①选择G列和S列;
②利用条件格式,突出显示两列的唯一值;
突出显示的就是T2中没有被匹配上的,之后再针对这些在T3的填写结果中手动匹配。
啦啦啦,今天主要介绍关于匹配的内容啦。算是萜妹在实际操作过程中的一些小经验吧,希望可以帮到小可爱们。有需要的小可爱们,萜妹还是建议对照着推送自己做一下,这样才更能掌握。
之后,中卷不像上卷是主观上的写不完,而是萜妹写着写着,发现内容有这么多了。如果把剩下的内容一起写完就太长了,所以还是分开吧。
不过因为要指导学弟学妹跑数据了,所以要么会增加更新频率,要么就是提前更后续的内容啦(其实具体的操作,在初级入门的分类里都有,就是没有视频指导而已)。
另外,如果小可爱有什么萜妹尚未提及的关于毕业论文的操作问题,可以考古萜妹以前的推送(干货-初级入门,这个分类)。毕竟萜妹写本科毕业论文的经验都在那里啦~
最后小可爱们,我们下周见吧~
往期推送
原文链接: