前期准备丨变量计算
这周我们终于要进入数据准备的收尾部分,要完成反向、变化量、标准化等等操作,让数据成为待分析的状态~
虽然这些操作在SPSS中也可以完成,但是SPSS的语句是即时的。在小可爱们后续补充被试数量时,还需要把那些操作重复一遍。所以萜妹会选择在Excel中完成这些操作,毕竟在Excel中只需要完成公式填充,补充多少次都不愁。
那萜妹开始跟小可爱们分享公式和技巧吧~
(注:处理方式并非唯一,萜妹只是分享个人经验~
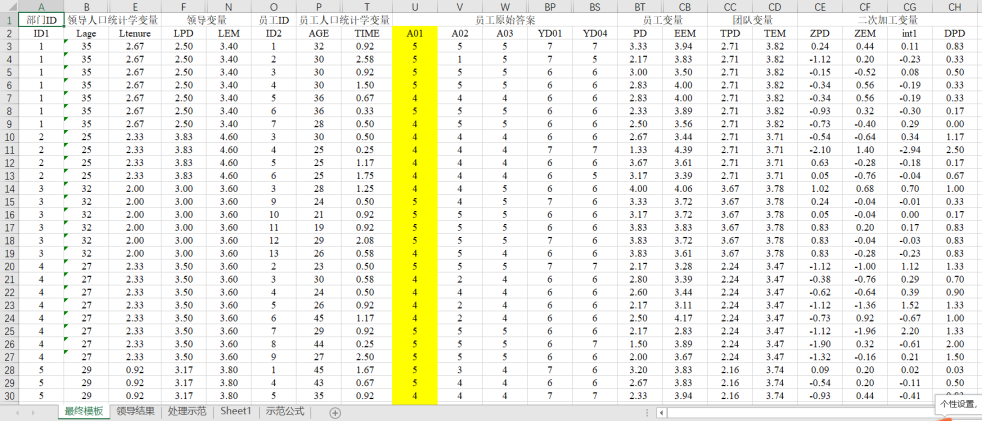
来源:萜妹自制
在介绍具体技巧之前,要先针对这个模板对小可爱们做一个说明(怕文字讲的不够清楚,萜妹还录了个小视频)。
第一,这里没有领导原始数据。用这里的数据来分析领导量表的信度会产生误差。因为各组人数不同,会导致权重不同,进而影响到结果。所以想分析领导量表的信度需要额外建立一个Excel。
第二,团队变量是指员工变量的均值。SPSS中无法快速处理,推荐用Excel中的公式。
第三,二次加工变量则是标准化、交互项、差值等变量。SPSS和Excel的操作难度都不大,SPSS可能更简单,Excel则是能实时更新。
为了让小可爱们理解上面这个表格,所以萜妹多加了一行,当做注释。实际操作过程中,除去第一行,就是可以直接导入SPSS或者Mplus中分析的数据啦~(为了页面美观,萜妹隐藏了很多列,实际操作时看起来不会这么简单。)
另外,上面的模板是萜妹做的一个比较详细的版本。在具体操作过程中,可能不涉及部分变量(比如团队变量),小可爱们可以自行取舍。
介绍完模板,接下来会介绍具体的公式和作用,包括:题项反向、变量化、领导数据填充、部门编号汇总、计算团队平均值、变量标准化、计算交互项、计算差值。
题目反向
假设需要反向的题目为A列,那么可以新建B列,在B2输入如下公式,再填充至整列即可。
- 七点量表:**=8-**A2;
- 五点量表:=6-A2;
变量化
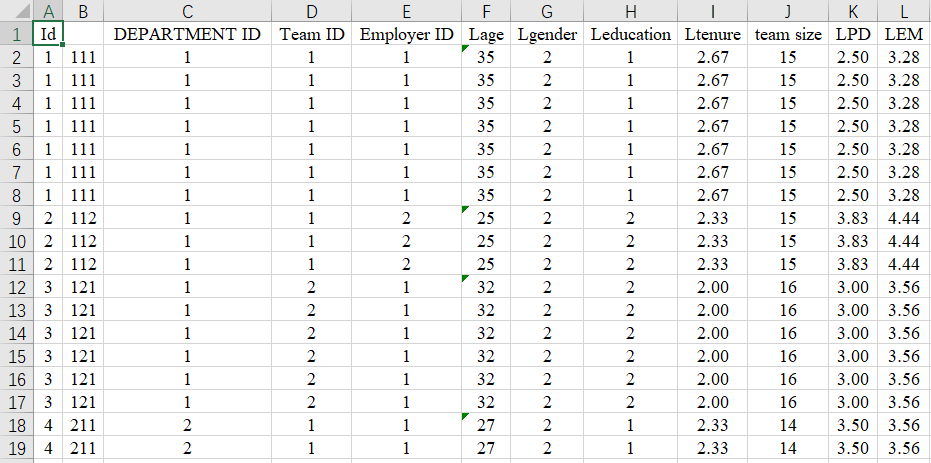
假设需要变量化的题目原始状态为下图所示:
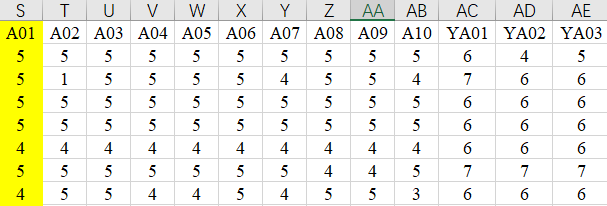
方法一:利用Average公式;
- AF2=Average(S2,:AB2)
- AG2=Average(AC2:AE2)
方法二:利用Averageif公式;
- AF2=AVERAGEIF($S$1:$AE$1,"=a*",$S2:$AE2)
- AG2=AVERAGEIF($S$1:$AE$1,"=ya*",$S2:$AE2)
两种方式看似差不多,都得自己针对每个变量写公式,甚至方法一写起来还更简单一点。但是面对变量比较多的时候,萜妹还是更推荐方法二的。
首先,介绍一下Averageif函数,可以把这个函数通俗的理解为:averagif(if判断的区域,if的判定依据,数据的计算区域)。
其次,在使用时有一个要注意的点是:=和"“要一起用,不用"“会报错的。
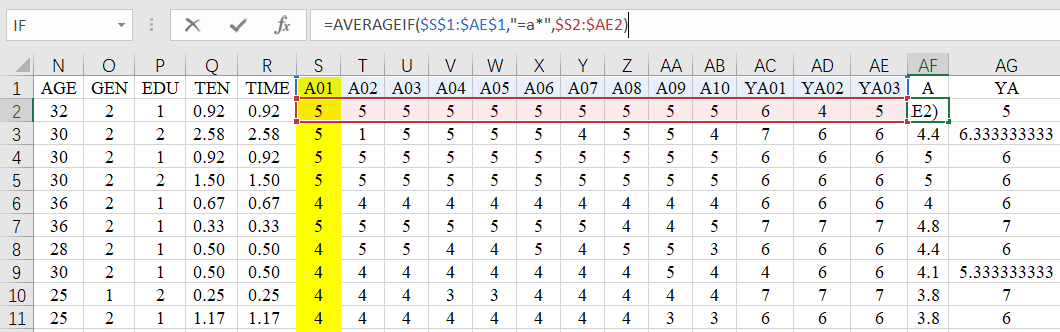
那么最后,萜妹再来介绍我们的方法二。不难看出,方法二的每个变量公式都是基于:
【=AVERAGEIF(完全固定的语句标题,"=语句编码字母*",仅固定列的原始数据)】的变形。

每个变量不同的地方仅在于,对应的语句编码字母。
我们完全可以使用公式填充完所有的变量,再针对不同的编码字母进行修改,这样可以做到快速填充(而且也不那么费眼睛)。
这样就算有20个变量,也可以在半分钟内都计算出结果啦(10秒复制公式,20秒改每个的字母)~
领导数据填充
萜妹之前不是在(上)卷的时候说过,我录领导和员工匹配的问卷,通常喜欢这样录,看起来一目了然一点。
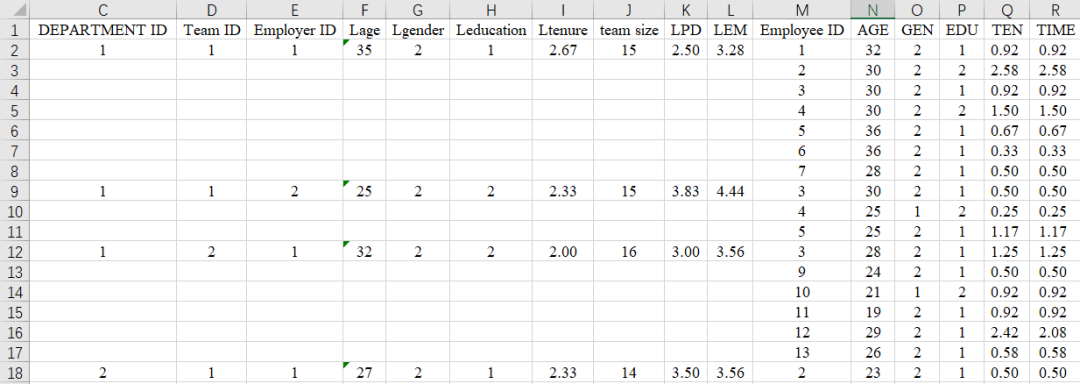
所以,在真正要分析的时候,我们还要先把空白的数据填充好。
具体步骤:
①选中领导数据,行数与员工数据相同。假设有500份员工数据,就选中C2:M501;
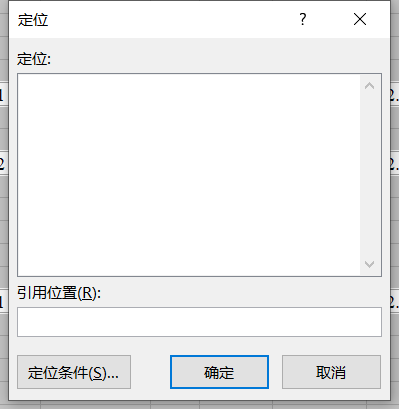
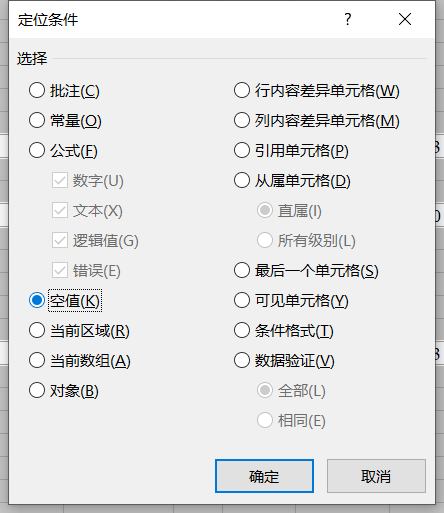
②按【F5】➔点击【定位条件】➔选中【空值】➔点击【确认】;
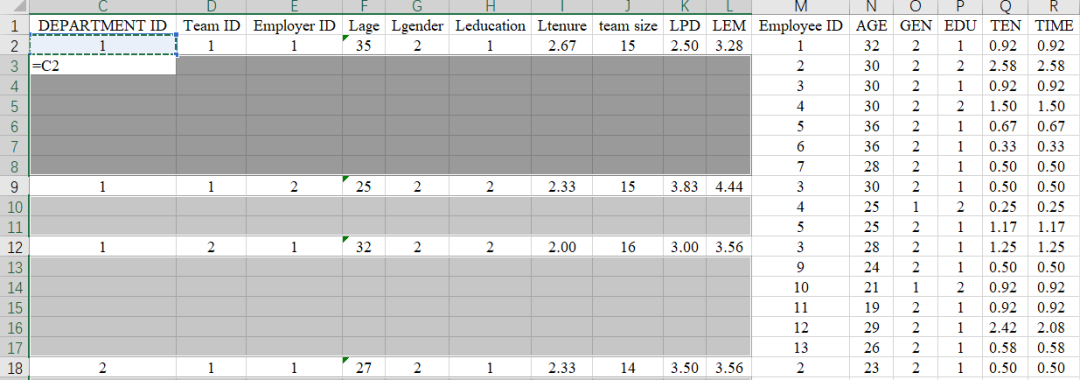
③在C3输入【=C2】,按住【ctrl】再按下【Enter】(这样能让被选择的空值全部填充完好)。
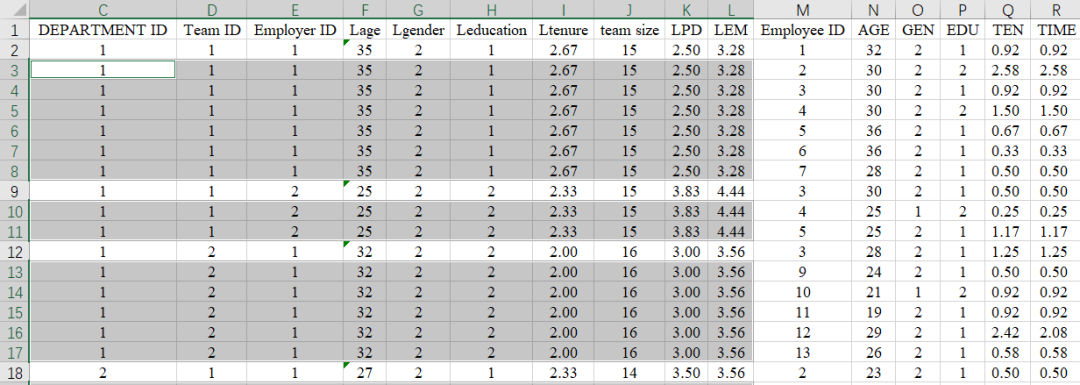
部门编号汇总
之前,萜妹的数据是有多个ID的。我们要导入其他软件分析时,也需要合成一个部门ID。
最简单的方法是使用&符号。

如图,在B2输入【=C2&D2&E2】,再向下填充即可。
其实这个时候的ID已经可以代表不同部门了,但是我也知道有的朋友喜欢从1开始,就喜欢正正常常的那种序号。

那么这时就需要利用IF函数解决。首先在A2输入1,再在A3输入【=IF(B3=B2,A2,A2+1)】,最后向下填充即可。
计算团队平均值
团队变量的计算也是利用Averageif公式。
在目标单位格中输入以下公式,再向右向下填充:
【=AVERAGEIF($A$2:$A$36,$A2,AF$2:AF$36)】
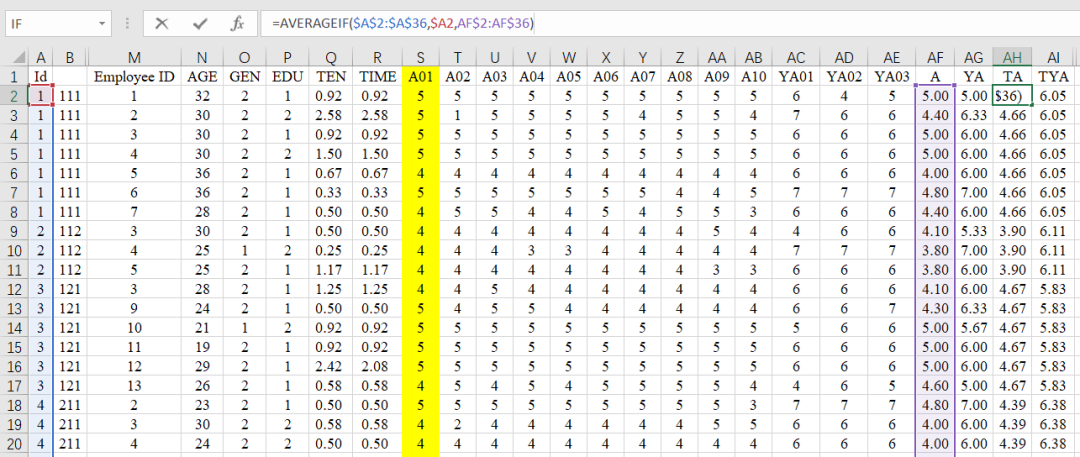
要注意以下的各数据的固定情况不可以改变,不然在公式填充的时候会发生变形,导致错误。
- IF的判断区域($A$2:$A$36,),需要完全固定,即选中后,按一次【F4】;
- IF的判断依据($A2),则需要固定列,即选中后,按三次【F4】;
- 数据的计算区域(AF$2:AF$36),则需要固定行,即选中后,按两次【F4】。
变量标准化
变量标准化则是要利用standardize公式、求平均的average函数与求标准差的Stdev.p函数。
在目标单位格中输入以下公式,再向右向下填充:
【=STANDARDIZE(AF2,AVERAGE(AF$2:AF$36),STDEV.P(AF$2:AF$36))】
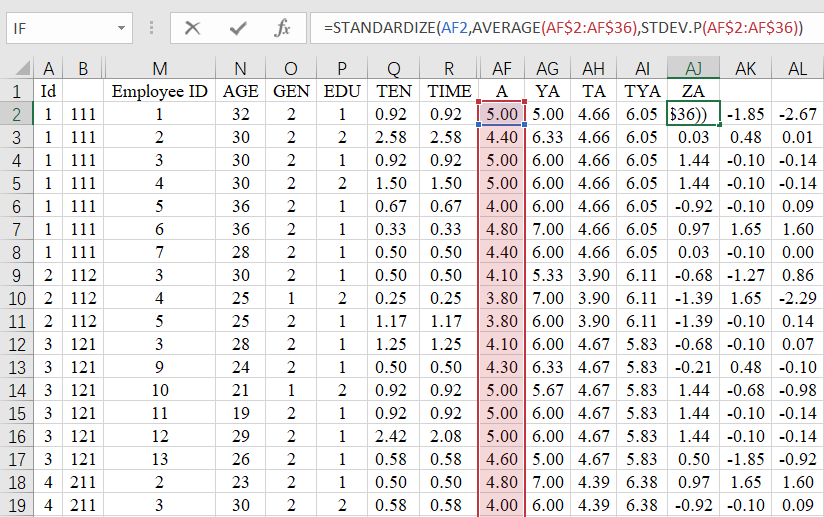
这里萜妹我再提醒一句,可向右向下填充,意味着,无论你有多少个变量,都只用写一个公式,就可以完成所有变量中所有数据的计算!!!是不是无敌方便!
计算交互项和差值
最后是计算交互项、乘积、差值等。
- 乘积:=A2*B2;
- 差值:=A2-B2;
讲道理,这也太简单了对吧,而且也是调整好位置,向右向下一顿填充就完事了。
这不比SPSS一个个算要香多了吗!
啦啦啦,数据准备终于结束了。关于数据的前期处理一不小心就写了这么多了。其实有的小可爱可能会有疑问,觉得数据准备可能没必要写这么详细或者是处理成这样。但是对于萜妹我来说,我不爱走回头路,所以一般来说,我希望我处理完的东西,我不需要再回头去重新算它、调它,又浪费很多心力。
而且萜妹这个无敌大懒鬼,会为了节约自己的时间,而去想一些公式。当我把上面这些公式真正设计出来,并用于实践时,其实我的时间并没有花费的更多。大部分的公式都只需要无脑填充,大规模的变量也可以批量处理,这为我后续的分析也奠定了坚实的基础。所以我认为这样是好的,就想也分享给小可爱这些技巧~
还有关于Excel和数据处理想说的是,比起公式的运用,可能更重要的是,小可爱们要知道自己要完成什么。Excel的公式教学,百度真的轻轻松松。所以当我们知道我想要什么,如何利用公式解决其实就已经近在眼前了~
以上就是萜妹关于数据准备的Excel分享啦,本篇推送涉及的全部公式,都是萜妹自己想的。小可爱们如果也有其他公式,或是其他经验欢迎跟萜妹交流哦~
最后,关于数据可能就只剩筛选啦,考虑到进度,筛选的介绍应该会推后,毕竟它的重要性没有数据分析高~下周就会结合视频开始介绍数据分析啦~
另外,我电脑有点bug,录视频的收音不太好。而且,录到最后录的我嗓子有点哑了,我也是真的尽力了。还是有点委屈小可爱们,萜妹之后会想办法努力解决哒~
那小可爱们,五一假期快乐,我们下周见吧~
往期推送
原文链接: