数据分析丨有效性分析
等了这么久,我们终于要开始对数据进行分析啦!
写这篇推送前,萜妹回顾了自己本科毕业那段时间的推送。我感觉,该写的,其实我都写过了。可是为什么萜妹自认为已经对数据操作示范的很详细了,数据小白来看我的推送还是一头雾水。
认真反思后,我觉得最大的原因是,小白根本不知道自己要做什么,以及最终要做成什么样。所以我的示范好像是告诉他们1+1=2,但是实际上,他们都不理解1是什么,以及为什么要算1+1=2。
所以这一次,萜妹想用通俗的话,来帮小可爱们搭建个框架,并且告诉小可爱们要做成什么样,为什么要这么做,以及怎么做~
接下来萜妹会具体的介绍每个要做的步骤。萜妹把它们分为了三个大类,分别是:数据有效性分析、样本基本描述、数据具体分析(这周只够数据有效性分析)。
- 数据有效性分析:信度检验、验证性因子分析、共同方法偏差检验。
- 样本基础描述:描述性分析、相关分析。
- 数据具体分析:回归分析、bootstrap法、简单斜率分析(涉及调节时使用)。
注:以上为至少要完成的操作,面对特殊情况的额外操作,这里未提及。如无特殊情况,完成上述操作即可。
信度分析
【步骤目标】
得到内部一致性系数,又称克伦巴赫α系数。通常报告于变量测量部分。

来源:参考文献[1]
【步骤目的】
官方定义:检验测量样本回答结果的可靠性。
萜妹理解:信度分析可以被理解为检验各题项测的是不是同一个东西。如果信度不高,则测的并非一个东西。
- 一个不一定恰当的比喻:你以为发出去的卷子都是数学题,通过卷子能知道别人的数学水平。结果卷子里,有的是文学题、有的是英语题。聚在一起不伦不类,最后得分没有任何意义。
【具体操作】
使用软件:SPSS
①【分析(A)】-【度量(S)】-【可靠性分析(R)】;
②模型选择:【α】➔将目标题项从左侧拖入右侧项目框➔点击【确定】,得结果。
【数据解读】
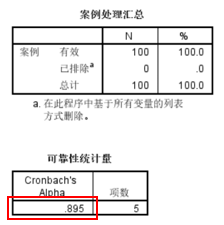
红框内数据为结果,α数值越高,信度越好。
【判断标准】
0.8以上较好,0.7勉强接受。
验证性因子分析(CFA)
研究过程中,如果涉及量表开发,则需要提前进行探索性因子分析。如果各变量使用的均是成熟量表,则可仅进行验证性因子分析。第二种情况更为常见,所以这里萜妹仅介绍验证性因子分析。
【步骤目标】
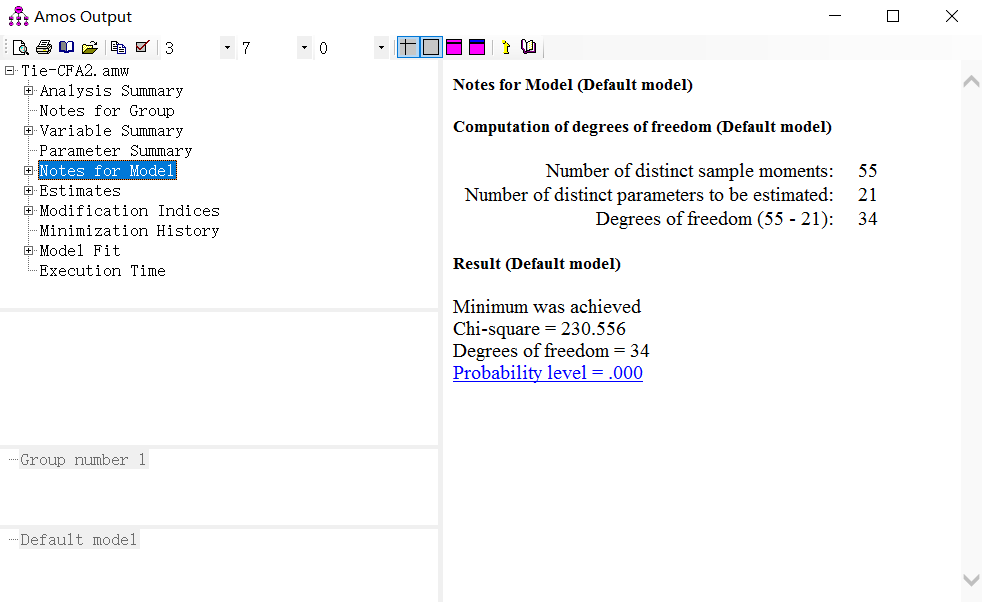
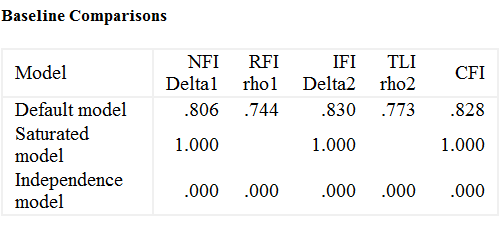
计算出χ2 、df、χ2 /df、CFI、RMSEA等值,绘制出下表,或使用文字描述。
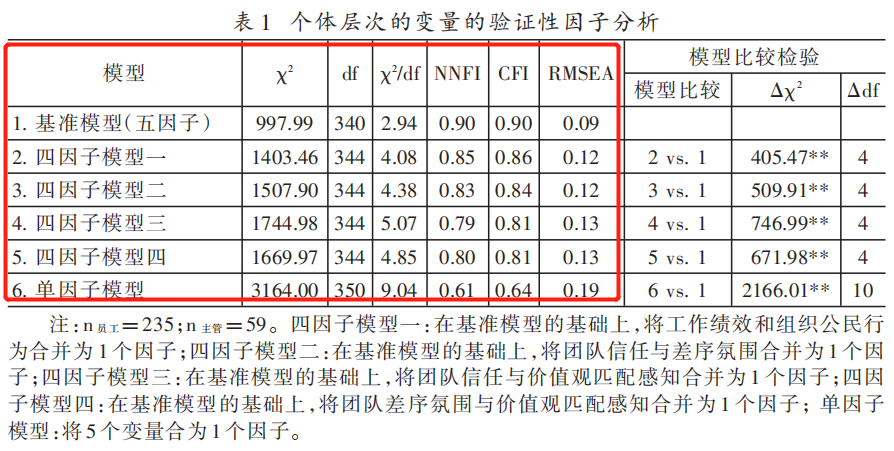
注:红框内为必要部分,使用mplus时,NNFI可替换为TLI。
来源:参考文献[2]

来源:参考文献[1]
【步骤目的】
官方定义:验证因子与测量项之间的对应关系。
萜妹理解:这里则是既检验各题项是否测的真的是一个变量(通过看基准模型的结果),又检验变量之间是否真的不同(通过比较各模型间的变化)。
- 一个不一定恰当的比喻:假设你发了10道题目出去,分别为3题数学题、3题文学题和4题英语题,想得到别人的数学、文学和英语水平。
- 你先要检验每个题目是不是真的测的是预期的能力,即3道数学题是不是测的一个东西(A)、3道文学题是不是测的一个东西(B)、4道英语题是不是测的一个东西(C)。如果做不出这个结果,则和信度低一样,说明测的东西没有意义。
- 又要检验测出了三个东西各不相同,即A跟B是不一样的。如果二者一样,则说明6道题测的是一个东西,那么后续验证出A能影响B也是无意义的。
【具体操作】
方法一:使用软件:Mplus
关于mplus的语句说明,萜妹有专门写过一次推送,可在文末往期推送中查阅。要先有mplus的基础,才能理解下面的语句。
基准模型语句:
TITLE: CFA
DATA: FILE IS 1.dat;
VARIABLE: NAMES ARE id a1-a3 b1-b3 c1-c4;
Usevariables are a1-a3 b1-b3 c1-c4;
MODEL:
a by a1-a3;
b by b1-b3;
c by c1-c4;
OUTPUT: Standardized;
双因子模型语句:
TITLE: CFA
DATA: FILE IS 1.dat;
VARIABLE: NAMES ARE id a1-a3 b1-b3 c1-c4;
Usevariables are a1-a3 b1-b3 c1-c4;
MODEL:
a by a1-a3 b1-b3;
c by c1-c4;
OUTPUT: Standardized;
注:蓝字部分为变化部分。
我们只用在基准模型的基础上,不断修改、合并,即可得到各因子模型,最后把结果进行比较即可。
此处萜妹建议大家每次更改语句后都保存成一个新的input文件,否则只能保存住最后一次语句的输出结果。
方法二:使用软件:Amos
萜妹昨天晚上才在B站上学的Amos,所以Amos的基础介绍还没来得及写。不过都说Amos比Mplus简单,上手还是非常容易的。考虑到篇幅原因,我这里也只给出对应的模型,其他的基本操作还需要小可爱们自学或者等我的推送介绍。
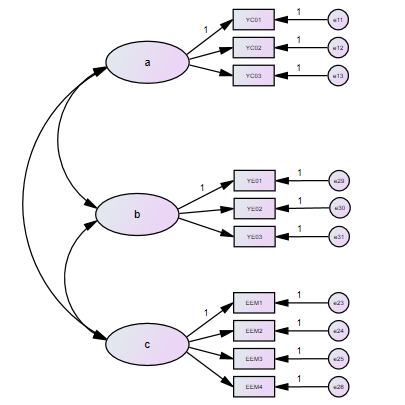
基准模型
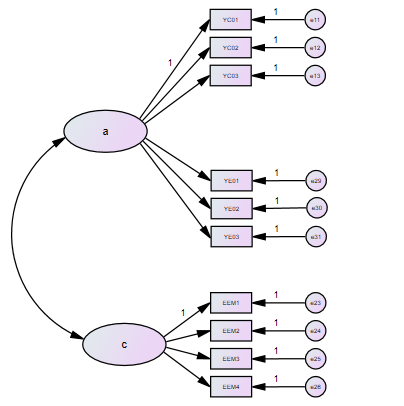
双因子模型
【数据解读】
方法一:使用软件:Mplus
MODEL FIT INFORMATION 部分

方法二:使用软件:Amos
Notes for Model 部分
MODEL FIT 部分
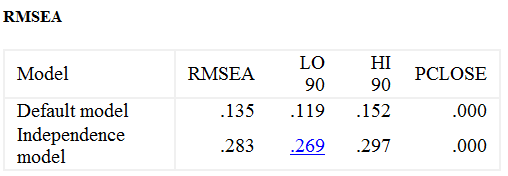
【判断标准】
- 卡方/自由度:小一点更好,最好在2~5以内;
- CFI/TLI:大于0.9;
- RMSEA:小于0.08。
共同方法偏差检验
【步骤目标】
计算出相应的指标,在文中进行描述:是否存在共同方法偏差。


注:此处采用了两种检验方法,仅用一种方法时,目前通常使用第二种。
来源:参考文献[3]
【步骤目的】
官方定义:检验是否因为同样的数据来源或评分者、同样的测量环境、项目语境以及项目本身特征所造成的预测变量与效标变量之间人为的共变。
萜妹理解:其实官方定义挺明白的,我就用例子介绍的更通俗一点。
- 比如:如果所有的测量都是通过问卷进行的,那么问卷这种方式对你的结果会不会有影响?
- 再比如:如果所有的问题都是员工自我报告的,那么这会不会又产生影响?
【具体操作 / 数据解读 / 判断标准】
方法一:单因子检验
(一)使用软件:SPSS
这是最简单的方法,以前的文章用这种方法的比较多,现在感觉用的少了。如果选用这种方法,文章撰写时参考文献可写:周浩, 龙立荣. 共同方法偏差的统计检验与控制方法[J]. 心理科学进展, 2004, 12(6):942-942.
①【分析(A)】-【降维】-【因子分析(F)】;
②将所有题项从左侧拖入右侧变量框➔点击【确定】,得结果。
结果:
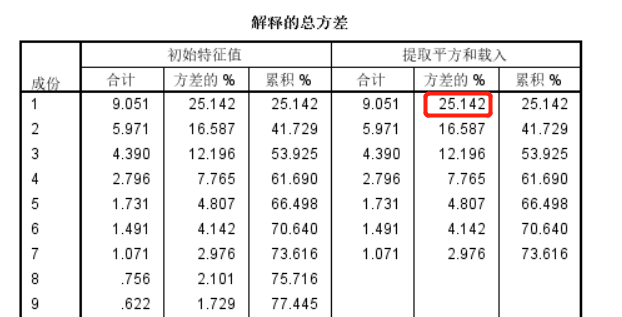
红框部分小于40,说明不存在严重的共同方法偏差。
(二)使用软件:Mplus
单因子检验语句:
TITLE: CFA
DATA: FILE IS 1.dat;
VARIABLE: NAMES ARE id a1-a3 b1-b3 c1-c4;
Usevariables are a1-a3 b1-b3 c1-c4;
MODEL:
a by a1-a3 b1-b3 c1-c4;
OUTPUT: Standardized;
模型结果依旧是看χ2 、df、χ2 /df、CFI、RMSEA等值。模型拟合不好,则说明没有共同方法偏差。
(三)使用软件:Amos
基准模型
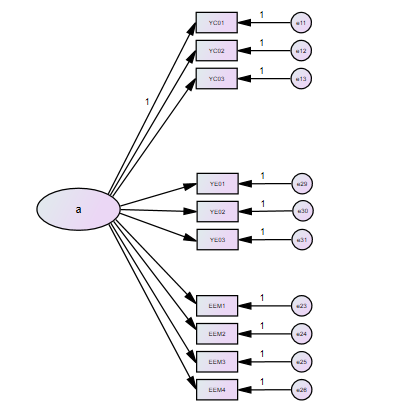
单因子模型
模型结果解读同上。χ2 、df、χ2 /df、CFI、RMSEA等值不好,则说明没有共同方法偏差。
方法二:加入方法因子-使用软件:Amos
如果选用这种方法,文章撰写时参考文献可写:Podsakoff P M , Mackenzie S B , Lee J Y , et al. Common method biases in behavioral research: A critical review of the literature and recommended remedies.[J]. Journal of Applied Psychology, 2003, 88(5):879-903.
这里想说明一下,加入方法因子在Mplus中,虽然可以写出语句,但是运算结果容易报错(我不知道是偶然还是必然),所以稳妥起见还是用Amos比较好,这也是我为什么突然去学了Amos的原因。
基准模型
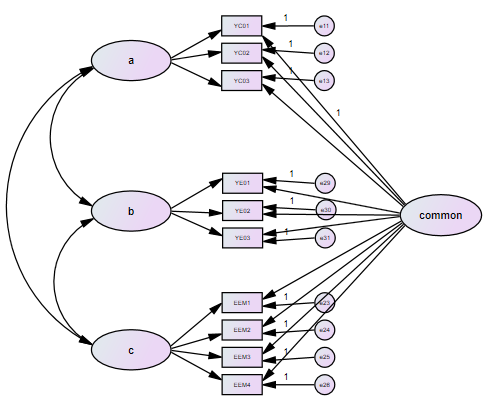
加入方法因子模型
模型结果仍是是看χ2 、df、χ2 /df、CFI、RMSEA等值。但是此时数据肯定会比基准模型要好。不过如果模型各指标改善程度均在0.02以内就可以被认为不存在严重的共同方法偏差。
0.02是萜妹看过的优质文章中,变化最大的值,至于能不能更大,这萜妹就无法确定了。
啦啦啦,这又是一篇耗时5小时的推送,所以数据分析的分篇是必然啦。至于视频,由于整个数据分析过程中会有很多重复性、或者相似度较高的操作,所以我准备全写完再一起示范呀,这篇就不单独录了~
这篇推送和之前的操作示例相比,萜妹认为最大的差别在于,我在这里想让没有基础的小可爱们真正的去理解,每一步的意义和目的,而不仅仅是一个工具人。希望这真的能对小可爱们有所帮助。如果有什么建议或者问题,也可以留言跟萜妹反馈哦~
另外,萜妹用的是SPSS20的版本,有些说法可能和现在的版本不一样。但是位置一般没变,小可爱们可以对照位置查看。
最后再提一嘴,今年毕业急着想看后续处理步骤的小可爱们,可以先在往期推送里,看萜妹以前的经验吼~
小可爱们,我们下周见吧~
参考文献:
[1]马君,闫嘉妮.正面反馈的盛名综合症效应:正向激励何以加剧绩效报酬对创造力的抑制?[J].管理世界,2020,36(01):105-121+237.
[2]沈伊默,诸彦含,周婉茹,张昱城,刘军.团队差序氛围如何影响团队成员的工作表现?——一个有调节的中介作用模型的构建与检验[J].管理世界,2019,35(12):104-115+136+215.
[3]王震,许灏颖,宋萌.“说话算话”的领导让下属更效忠:中国传统“报”文化视角下的领导言行一致与下属忠诚[J].管理评论,2018,30(04):106-119
往期推送
原文链接: