数据分析丨跨层模型检验
我们接着上期的内容,这期主要是完整介绍跨层模型分析的全过程,以及可以借助的各种软件~
跨层模型与单层模型有所不同,其中会涉及到一些特有的指标,比如ICC、Rwg。此外,假设检验部分的语句和操作也会略有差异。
接下来,萜妹会按照操作顺序,给大家依次介绍。
跨层的必要性分析
拿到嵌套数据后,我们首先要进行必要性分析,证明嵌套的数据它有做跨层的必要。该步骤的常见指标为:ICC(1)、ICC(2)、Rwg,多以文字形式汇报。

来源:见参考文献
Intra-class Correlation(ICC)
ICC通常被分为了ICC(1)、ICC(2)。公式分别为:
- ICC(1)=(MSB-MSW)/{MSB+[(K+1)×MSW]};
- ICC(2)=(MSB-MSW)/MSB。
【数据操作 / 数据解读】
使用软件:SPSS
①【分析】-【比较均值】-【单因素ANOVA】;
②将【跨层变量】从左侧拖入右侧因变量中➔将【分组变量】拖入【因子】中➔点击【确定】;
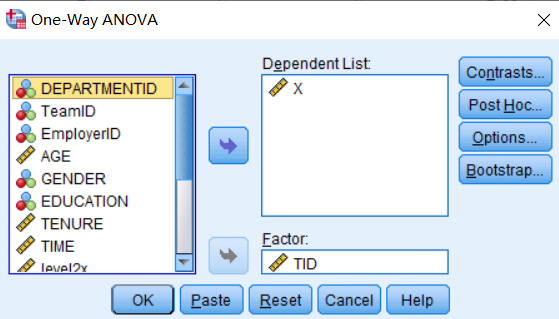
③此时,可得到如下结果:
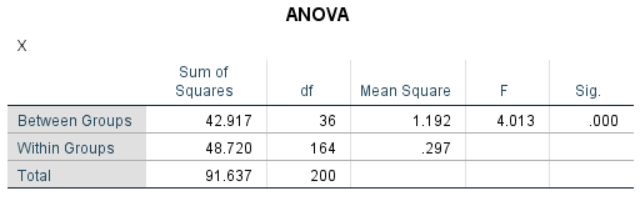
④将结果复制至Excel模板➔输入【总人数/团队数】
此时,Excel会自动得出结果,如下图:
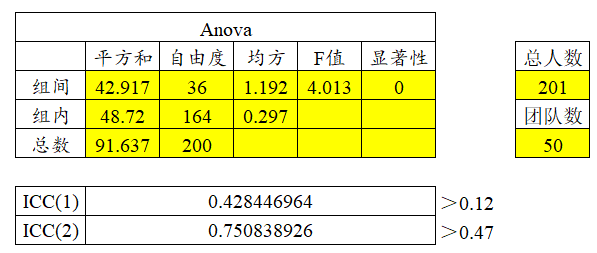
【判断标准】
判断标准其实有挺多的,萜妹这里给出的标准是ICC(1)需要大于0.12,ICC(2)需要大于0.47。跨层模型的ICC是很好满足的。
Rwg
【数据操作 / 数据解读】
使用软件:SPSS
①打开SPSS的数据文件;
②【文件】-【新建】-【语法】;
③输入如下语句➔点击运行;
AGGREGATE
/outfile='C:\Users\tie\Desktop\rwg.sav'
/break=TID
/sdx1=sd(x1).
execute.
其中,红字部分需替换。
- 第二行,替换为自己想要输出的文件名及位置,萜妹这里是将新文件生成到了桌面;
- 第三行,替换为自己的分组变量;
- 第四行,替换为自己的跨层题项。需注意的是:量表有多少个题项都要计算,本示例为一条目,即仅计算x1的组内标准差。
此时,会有一个新的rwg.sav文件在指定位置生成。
④打开【rwg】文件➔【文件】-【新建】-【语法】;
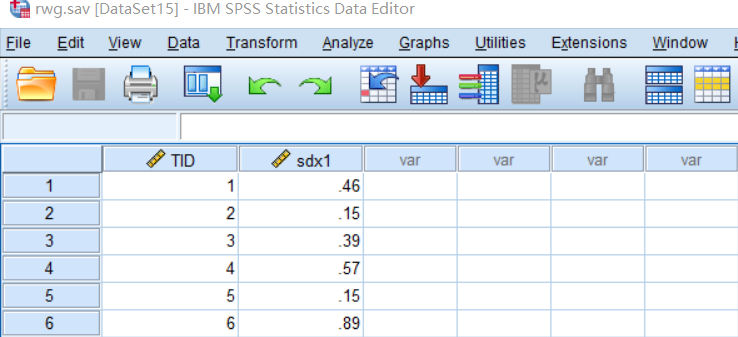
⑤输入如下语句➔点击运行;
compute varx1=sdx1×sdx1.
compute mvar=mean(varx1).
compute nvar=1.
compute rwg=nvar×(1-(mvar/2))/(nvar×(1-(mvar/2))+mvar/2).
execute.
其中,nvar代表题项数,最后一行的2则是根据量表等级决定的。公式为(X×X-1)/12
- 5点量表该值为2;
- 6点量表该值为2.92;
- 7点量表该值为4;
此时,文件中会新生成几个变量,如图:
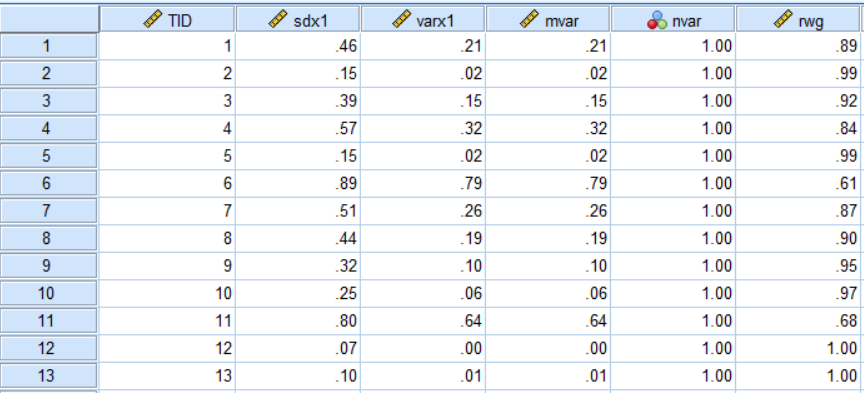
⑥计算Rwg的中位数与平均值;
这里注意,原始Rwg小于0时取0,大于1时取1。
【判断标准】
Rwg>0.7。
基础分析
这里指的是验证性因子分析和相关性分析。
验证性因子分析
有些文章里会在进行完单层分析后再补充跨层的验证性因子分析。

来源:见参考文献
【数据操作 / 数据解读】
使用软件:Mplus
语句(极简版):
TITLE :Multilevel CFA;
DATA: FILE IS 1.dat;
VARIABLE: NAMES ARE id x1-x6;
USEVARIABLES = id x1-x6;
CLUSTER = id;
ANALYSIS: TYPE = TWOLEVEL ;
MODEL:
%Within%
wx by x1 x2 x3 x4 x5 x6;
%Between%
bx by x1 x2 x3 x4 x5 x6;
Output:
Standardized CINTERVAL;
相关分析
做两层相关分析后可画出下表,也可以将团队层相关系数填至个人层面的右上角空白处。
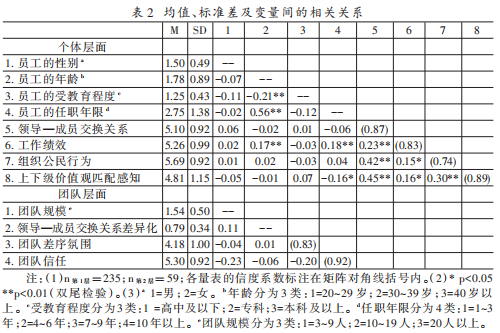
来源:见参考文献
【数据操作 / 数据解读】
使用软件:Mplus
跨层相关分析不用额外写语句,就在跨层验证性因子分析的时候,在output中补充输出:TECH4即可。
假设检验
和单层假设检验的汇报形式其实没太大差异,这个部分就不额外说明。我们主要来说说看具体怎么验证。
这里介绍两种方法,一种是mplus+R,另一种是新出的spss的mlmed宏插件。
Mplus+R
Mplus语句及操作
mplus还是根据模型写语句。萜妹就介绍上篇推送中用的最多三个模型的对应语句。没有太多好展开说明的,我们直接上语句。
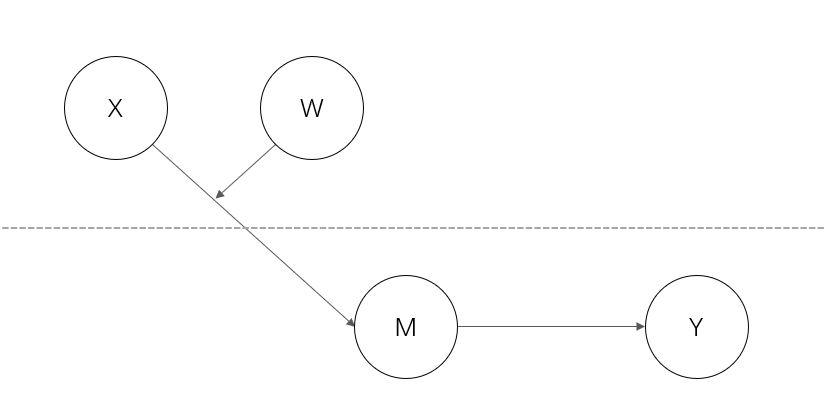
类型 I 被中介的调节语句:
TITLE: A two-level Type I MeMo model,
DATA: FILE IS example.txt;
DEFINE:
xw = (x -3.0) * (w - 4.0) ;
CENTER x w (GRANDMEAN) ;
VARIABLE: NAMES ARE x m w y cluster;
USEVAR1ABLES ARE x m w y xw;
CLUSTER = cluster;
BETWEEN = x w xw;
ANALYSIS: TYPE = TWOLEVEL;
MODEL:
%WITHIN%
y on m (bw)
%BETWEEN%
m on x w
xw (a) ;
y on m (bb)
x w xw;
MODEL CONSTRAINT;
NEW (ind) ;
ind = a * bb;
OUTPUT:
SAMPSTAT;
CINTERVAL;
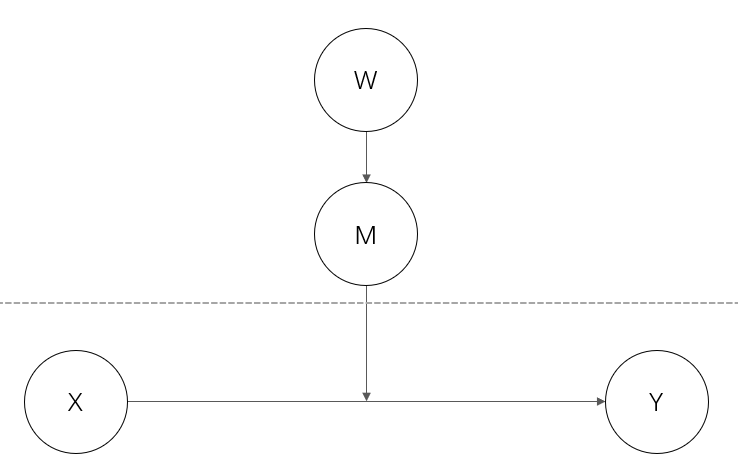
类型 II 被中介的调节语句:
TITLE : A two-level Type II MeMo;
DATA: FILE IS example.txt;
CENTER w m (GRANDMEAN) ;
CENTER x (GROUPMEAN) ;
VARIABLE: NAMES ARE x m w y cluster;
USEVARIABLES ARE x m w y;
CLUSTER = cluster;
WITHIN = x;
BETWEEN = w m;
ANALYSIS:
TYPE =TWOLEVEL RANDOM;
%WITHIN%
S | y on x;
%BETWEEN%
m on w (a) ;
S on m (b)
w;
y on m w;
y with S;!设立相关提高模型拟合度
MODEL CONSTRAINT;
NEW (ind) ;
ind = a * b;
OUTPUT;
SAMPSTAT;
CINTERVAL;
第一阶段被调节的中介语句:
TITLE: A two-level first-stage MoMe;
DATA; FILE IS example.txt;
CENTER w (GRANDMEAN) ;
CENTER x (GROUPMEAN) ;
VARIABLE: NAMES ARE x m w y cluster;
USE VARIABLES ARE x m w y;
CLUSTER = cluster;
WITHIN = x;
BETWEEN = w;! x、w是外生变量,需要自己定义;m、y是因变量,又是内生变量,会自动拆分。
ANALYSIS:TYPE=TWOLEYEL RANDOM;
MODEL:
%WITHIN%
S | m on x;
y on m (b2)
x;
%BETWEEN%
S on w (a1) ;! γ11
[ S ] ( a0 ) ;! γ10
m on w;
m with S;
y with m;
y with S;
y with w;! 相关
MODEL CONSTRAINT:
NEW (ind_h ind_l) ;
ind_h=(a0+a1*(.85))*b2; ! 根据自己的值修改
ind_l=(a0+a1*(-.85))*b2; ! 根据自己的值修改
NEW (diff) ;
Diff = ind_h - ind_l;! γ11
OUTPUT:
SAMPSTAT;
CINTERVAL;
R的补充Monte Caro分析
细心的小可爱可能会发现,上述都没有进行bootstrap检验。因为跨层数据是无法在mplus中进行这一步的,所以我们还需要借助R来补充分析。
有大佬做了个网站,我们可以直接在网站中输入数字得到结果,而不需要专门去学R。
网址:http://quantpsy.org/medmc/medmc.htm
1-1-1模型:http://quantpsy.org/medmc/medmc111.htm
1-1-1模型界面:
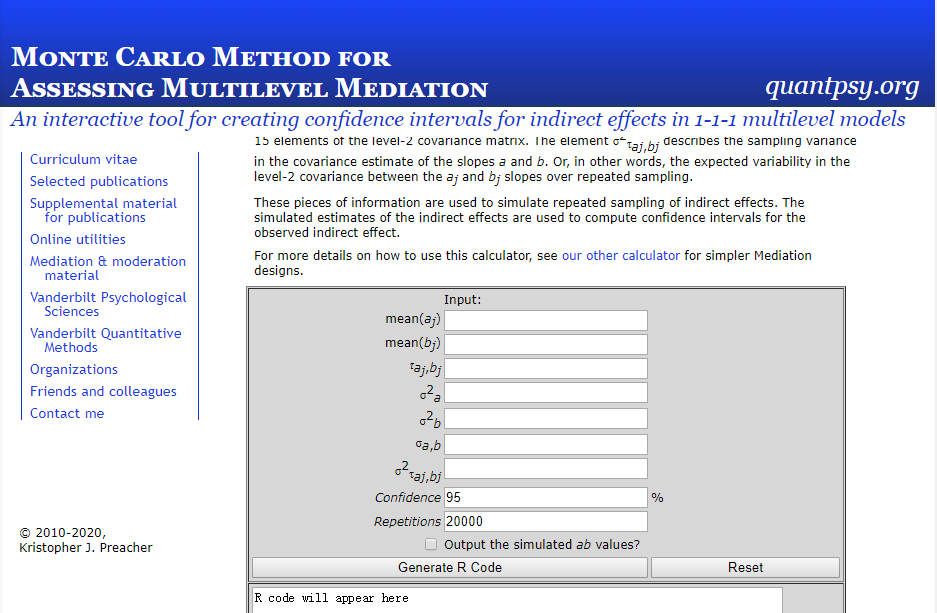
以上的数据都可以在mplus的TECH3中得到,具体怎么看,萜妹觉得可能还是视频讲的更清楚,这里就不详细截图了。
SPSS的Mlmed程序
前期准备
①在官网下载该宏程序;另外,萜妹建议使用手册也下下来,使用手册真的非常的有用。

下好后,应该长这样。
②检查SPSS版本,最好是22及以上,在21以下的版本是不能用MLmed插件的。
③安装Mlmed宏程序。
第一种方式,就直接点击打开第一个文件,它就会询问你是否要安装。但是这种方式,有可能安装不上,比如萜妹的SPSS这样就失败了。
所以我找到了第二种方式:【扩展】-【安装本地扩展束】,这样就可以确保能安装啦。
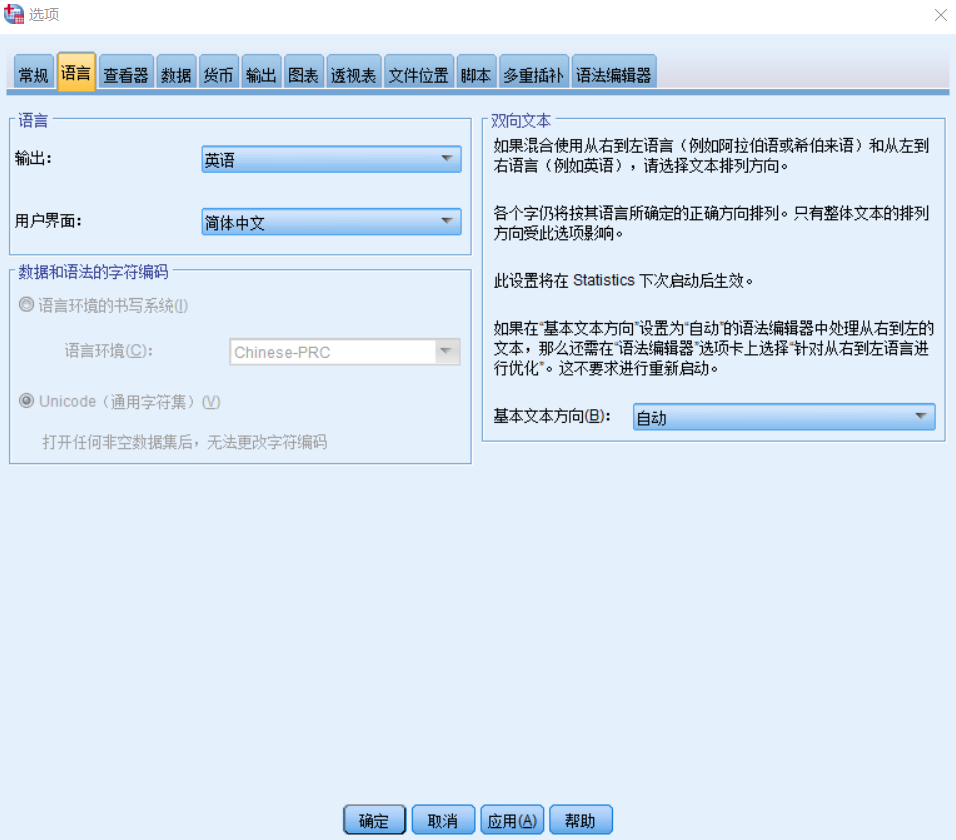
④调整SPSS的输出语言!!!
Mlmed的使用手册中说了,它目前只能在输出语言为英文时使用。如果是其他语言就会报错!
而在国内SPSS一般是默认编辑语言和输出语言为中文的,所以我们先要手动调整。
【编辑】-【选项】-【语言】,就可以调整。
具体分析
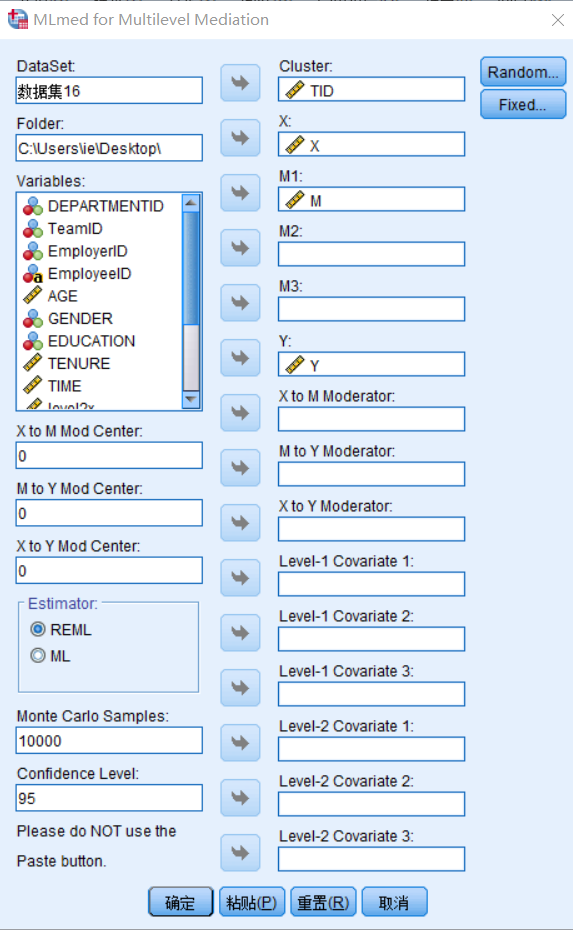
①【分析(A)】-【混合模型】-【Mlmed……】;
②按下图所示进行填写;
- 【DataSet】填数据对应的名字,通常是【数据集*】,注意这里是数据集的名字,不是你给这个文件的命名啊!
- 【Folder】填文件所在位置,注意最后要以斜杠结尾;其中,Windows是\,mac是/。
- 右侧就按照你的模型进行填充就好。
- 右上角的【Random】和【Fix】也是可以根据你的模型对应的调整。
注意:Mlmed只能处理M和Y在level1的模型。
【数据解读】
【判断标准】
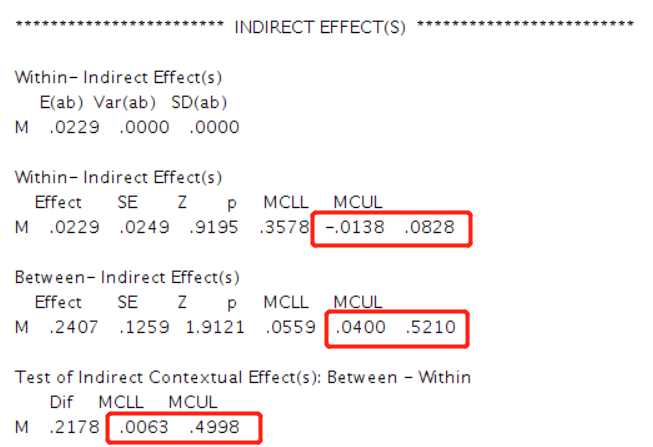
做出来的结果包括了模型拟合、固定效应、随机效应、直接效应和上述截图的间接效应。
红框部分表示,M的中介在level1不成立,但是在level2是成立的。
最后一个红框则是Monte Caro置信区间,所以这里就不需要再使用R去计算了。
啦啦啦,终于写完啦。这篇就是纯操作说明,而不涉及原理。因为再加上部分的原理说明,萜妹怕自己驾驭不了,另外也是我觉得这篇内容已经足够多了。
关于Mlmed的介绍,上述主要是提到了很多前期准备上的东西。因为萜妹自己的使用感受是,软件操作还是很简单,模型结果也很容易看,但是按教程做却老是报错,一直报错真的很让人崩溃,所以就来让帮大家解决这个问题吧。
另外,当我把Mlmed插件研究透之后,关于Mlmed的具体介绍,可能还会有一期专门的推送,不过应该不是最近了。
下一期大概会回顾这个月的各种数据分析,之后通过录视频教程的方式更细致的带着小可爱们做一遍吧。
那小可爱们,我们下周见吧~
参考文献:
沈伊默, 诸彦含, 周婉茹,等. 团队差序氛围如何影响团队成员的工作表现?——一个有调节的中介作用模型的构建与检验[J]. 管理世界, 2019(12).104-115+136+215
相关资源:
①回复“Mlmed”,即可获得Mlmed插件安装包;
②回复“ICC计算”,即可获得Excel模板。
往期推送
原文链接: