SPSS丨批量化操作
熟悉萜妹的小可爱应该知道,萜妹是Office的狂热粉丝,能用Excel解决的就绝对不会用SPSS,因为Excel可以用公式实现自动化,SPSS每次却要自己点。
但是,在了解了SPSS的语法后,萜妹再一次感叹,没有不好用的软件,只有笨笨的自己。所以这次也给大家安利,如何用SPSS的语法实现批量化操作。
这篇推送主要包含三个部分内容:如何生成语法+常用语法分享+如何使用语法。
如何生成语法
首先给小可爱们介绍最简单的方法。
大家每次常规操作完,是不是直接点【确定】,但是其实边上还有个【粘贴】键(我之前也从没有留意过)。
类似,这样(PS:宏插件的语法不能点粘贴哈):
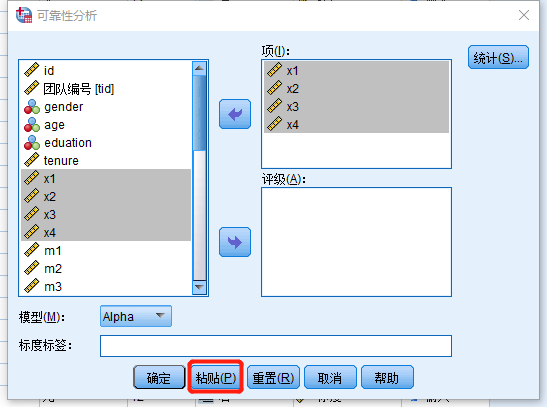
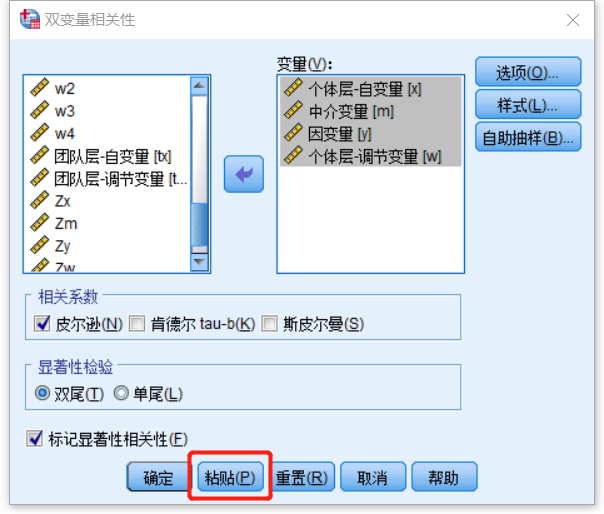
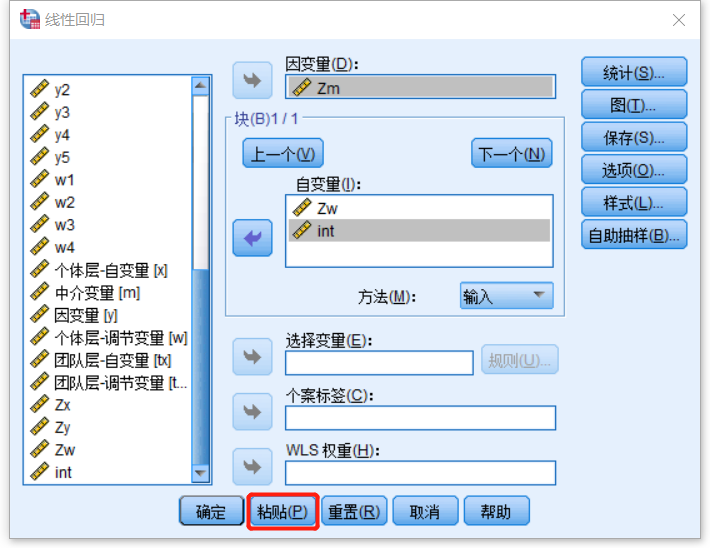
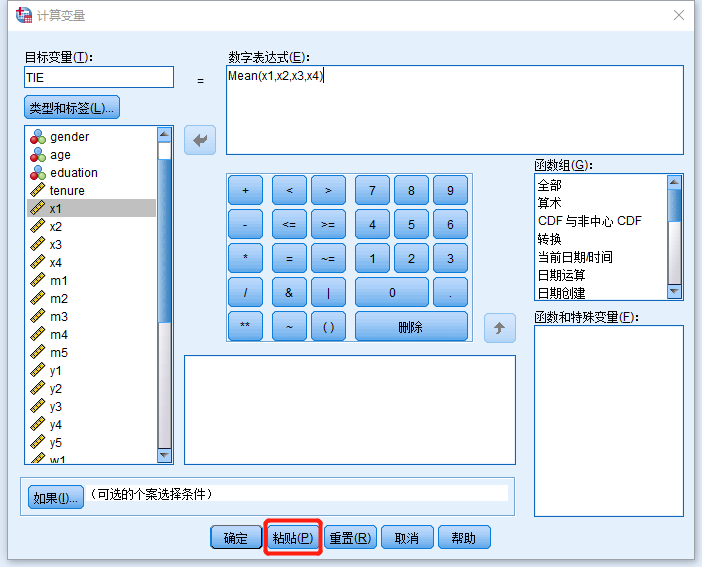
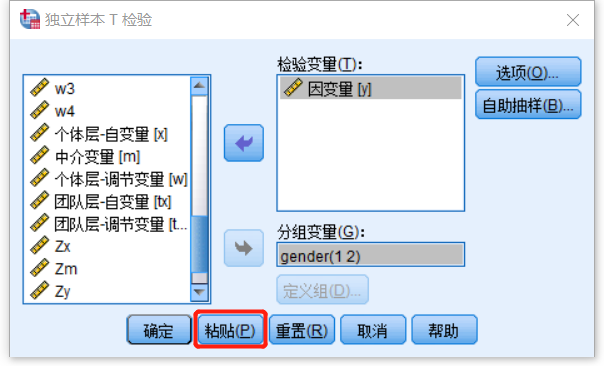
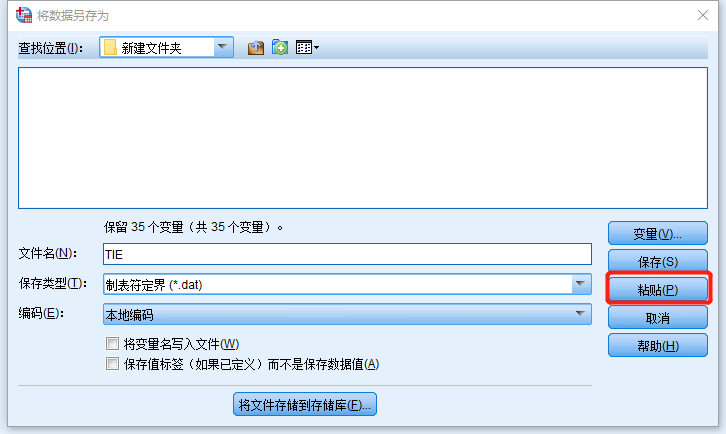
示例
只要点击【粘贴】,语法就会粘贴到一个语法文件之中。如果没有打开语法文件,软件也会自己新建一个,不用担心。
(此时语法粘贴,但并没有运行哈!!!)
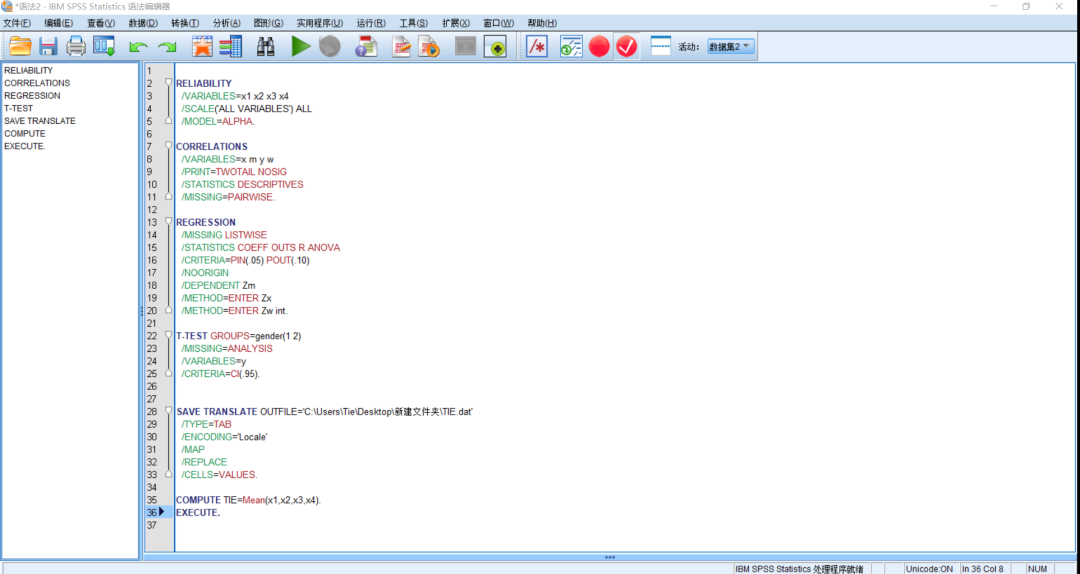
可以将常用操作都生成语法并保存,以后就直接修改语法,不用再一个个点啦。
那么,萜妹给小可爱们分享些常用语法
常用语法
黑字为固定部分,红字为应修改部分。
计算变量
COMPUTE TIE=Mean(x1,x2,x3,x4).
EXECUTE.
比如我们要把整个问卷变量化,就可以不断替换语法里的x,然后一次性完成(用Word替换或者手动替换都可以)。
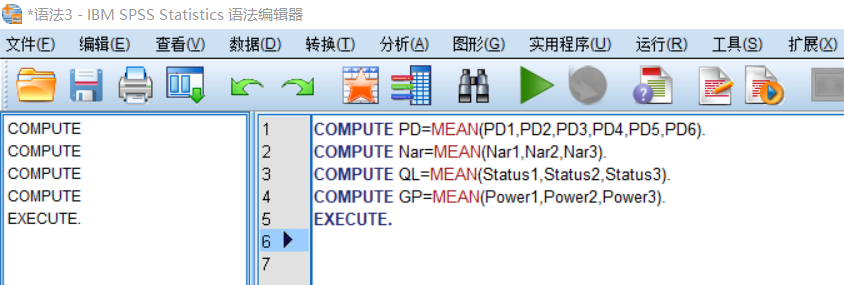
信度计算
RELIABILITY
/VARIABLES=x1 x2 x3 x4
/SCALE('ALL VARIABLES') ALL
/MODEL=ALPHA.
需多次计算时,将语句复制多遍进行修改即可。

相关分析
CORRELATIONS
/VARIABLES=x m y w
/PRINT=TWOTAIL NOSIG
/STATISTICS DESCRIPTIVES
/MISSING=PAIRWISE.
回归分析
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Zm
/METHOD=ENTER Zx.
/DEPENDENT 后接因变量,可以放入多个。
/METHOD=ENTER 后接自变量,每一行即为进行一次回归。
当要进行多次回归时,可直接在其后新增 /METHOD=ENTER

独立样本T检验
T-TEST GROUPS=gender(0 1)
/MISSING=ANALYSIS
/VARIABLES=y
/CRITERIA=CI(.95).
/VARIABLES= 后也可跟多个结果变量。
单因素方差分析
ONEWAY y BY edu
/STATISTICS DESCRIPTIVES
/MISSING ANALYSIS
/POSTHOC=LSD ALPHA(0.05).
此处y也可替换为多个结果变量。
生成.dat文件
SAVE TRANSLATE OUTFILE='F:\TIE.dat'
/TYPE=TAB
/ENCODING='Locale'
/MAP
/REPLACE
/CELLS=VALUES.
以上只是部分示例,小可爱们有其他的语法需求可以自行使用【粘贴】生成,或者百度。
亲测,SPSS的语法和Excel的公式在网上都能一搜一大把,萜妹不懂的时候也是靠百度。
如何使用语法
在获得所需语法之后,我们还需知道如何使用,这也非常简单。
第一步,新建一个语法文件。
点击【文件】-【新建】-【语法】即可得到。
其实我们也可以直接在语法模板里运行,但是萜妹会更习惯建个新的文件再修改和运行。
第二步,粘贴并修改待用的语法。
这是批量化操作的关键。如何修改已在上个部分介绍,如果有时候不知道怎么修改可以手动操作再【粘贴】,了解其中语法。
不过大部分情况(除了宏插件)下,语法的功能会比手动点击更为方便,甚至会得到一些手动点击无法得到的效果。
第三步,运行语法。
选中想要运行的语法,点击【绿色三角形】。

然后稍等片刻,就能得到所有语法的结果。
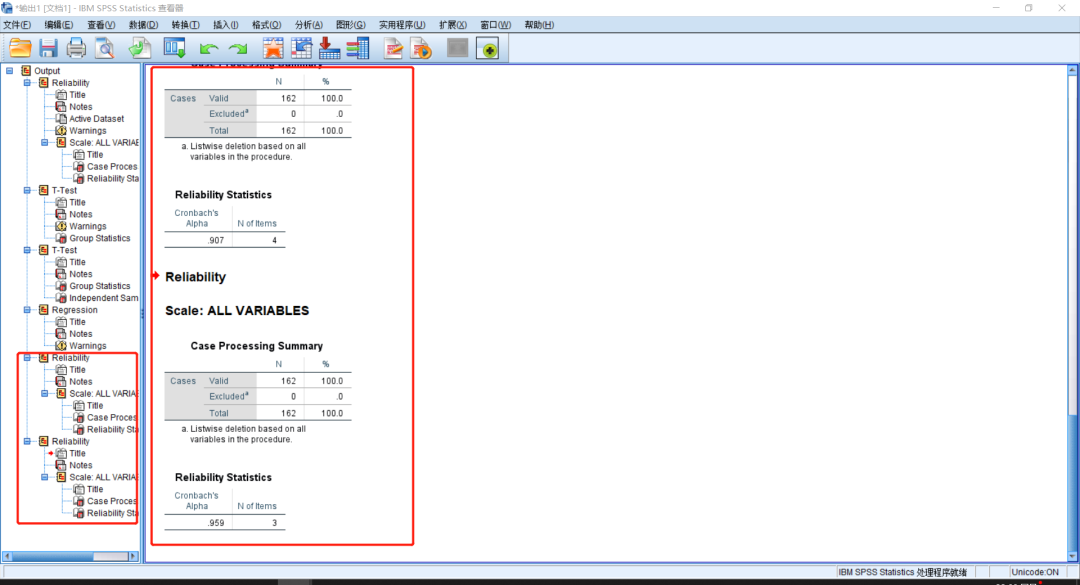
如果有多个数据文件,需要先点击想要计算的数据文件,再运行语法,或者也可以在前面输入:
DATASET ACTIVATE 数据集3.
以上就是萜妹的一些个人经验啦。我以前只会用SPSS的固定语法模板,算协方差系数或者其他指数。但了解到【粘贴】功能后,简直打开了新世界的大门。打开文件可以用它,数据分析可以用它,保存文件也可以用它,目前看来除了Process,它都能解决,就非常方便。
希望这篇推送也能帮助小可爱们提高数据分析效率,能在重复性操作上少花时间呀。
最后,下周大概率是范文分享,目前有几篇备选。有篇逻辑严谨的让我想全文背诵,有篇在研究设计部分做的比较严谨,还有几篇最新录用是我自己比较感兴趣的内容,最终分享哪篇容我再纠结纠结,小可爱们也可以提提建议。
那我们下周见啦~
往期推送
原文推送: