基于R的实验检验
Bain, K., Kreps, T. A., Meikle, N. L., & Tenney, E. R. (2021). Amplifying Voice in Organizations. Academy of Management Journal, 64(4), 1288-1312. https://doi.org/10.5465/amj.2018.0621
小可爱们好,这次又是一个新的系列,主要目的是带大家一起复现顶刊文章中的数据结果。
一方面,受益于Open science,我们现在有机会获得顶刊研究中的材料、数据和语句,这是一个非常好的练手机会。
另一方面,萜妹正在学习R。按照我个人的学习习惯,我一直认为针对方法,要先知其然,再去研究所以然。复现文章结果能帮我们快速的知其然。
于是,我又开新系列了!
温馨提醒:本次推送内容较多,建议先码后看,边看边操作~
整体介绍
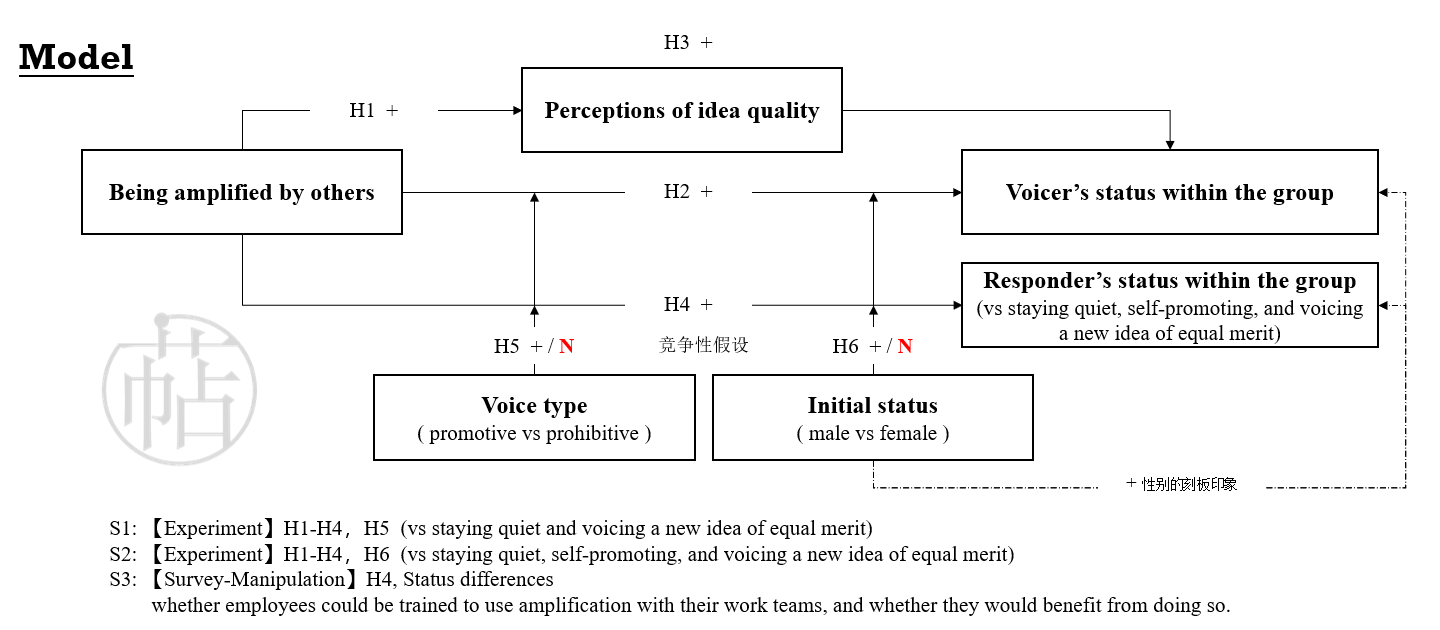
这篇文章想要研究:员工如何帮助同事通过建言来提升地位,同时也提高自己的地位?
因为假设有点复杂,所以文章中没有画模型图。萜妹自己画了一个,方便小可爱们理解。(如有兴趣或者有疑问,可以回原文查看)
公开数据
萜妹这次不关注它的假设和论述部分,主要来看看作者的研究过程。
获取地址:https://osf.io/v6abf
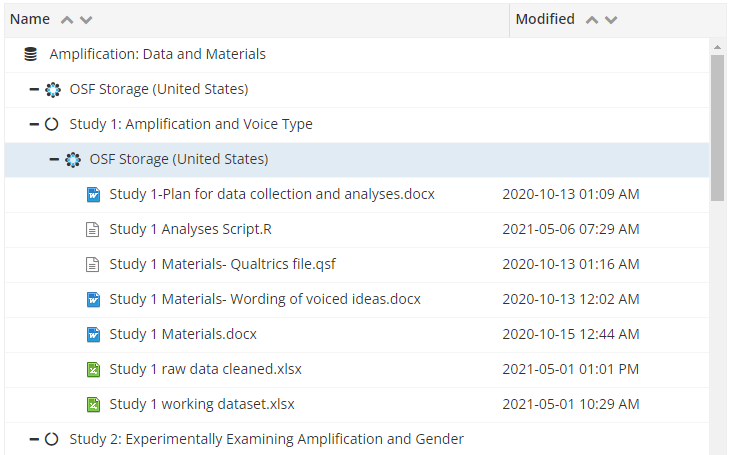
作者超级nice,他们把原始问卷(Qualtrics版/Word版)、实验材料、原始数据、最终数据、预注册内容全部公开了。
本次仅以Study 1为例。
原始问卷
做数据分析之前,需要清楚的了解数据结构,我们先来看看问卷。
虽然作者良心的给了Qualtrics版问卷,但萜妹尝试了一下,我们并没有使用权限,所以还是看看word版本吧。
知情同意

规范的调研,第一页必是知情同意书吖!小可爱们做实验的时候也要注意这一点吼。
实验背景
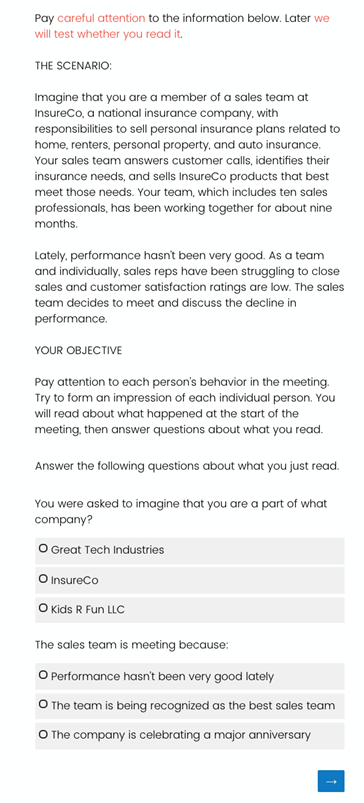
“想象你是国家保险公司InsureCo销售团队的一名成员……
最近,绩效不是很好……
销售团队决定开会讨论业绩下降的问题……”
很聪明的是,作者在这里加了两个注意力检验,如果没有通过就不会进入后面的问答。
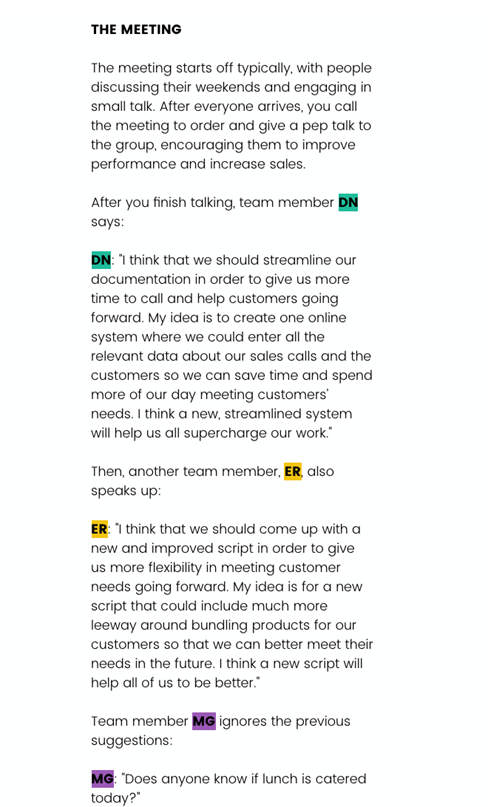
“会议以人们讨论周末和闲聊开始。在每个人到达之后,你召集会议,并给小组成员打气,鼓励他们提高业绩和增加销售。
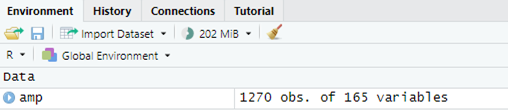
在你说完之后,团队成员DN提出了一个建议……
然后,另一个团队成员ER也提出了一个建议……
MG忽视了前面的建议,并询问午饭。”
【实验操纵】
“这时,你接到一个电话,必须退出会议。
用你自己的话,写下会议中提出的想法。”
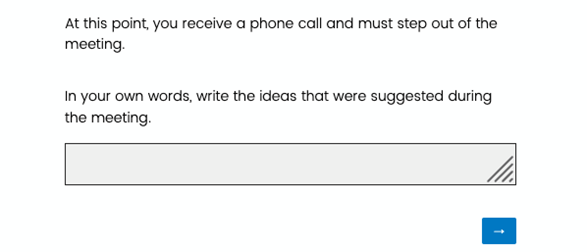
实验操纵
作者的实验做的非常细,首先,作者进行了预研究,通过两种检验方式,证明了实验材料中涉及的3种解决方案都是高质量且无差别的。
Voice type: promotive vs. prohibitive

每种建言,作者都给出了对应的四种版本。
Response: amplification vs. additional voice vs. staying quiet
-
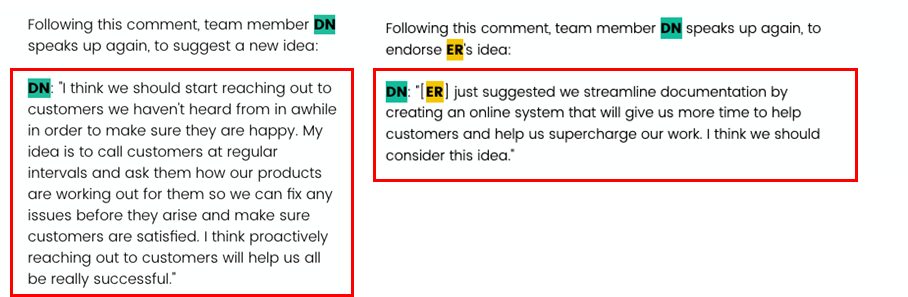
Amplification:DN重申ER的想法;

-
Additional voice:DN提出新想法;
-
Staying quiet:DN什么都没说。

操纵检验

后续测量
后续作者依次测量了DN、ER、MG的地位、控制变量(集体性、代理性)。

DN、ER的第一次建言质量。
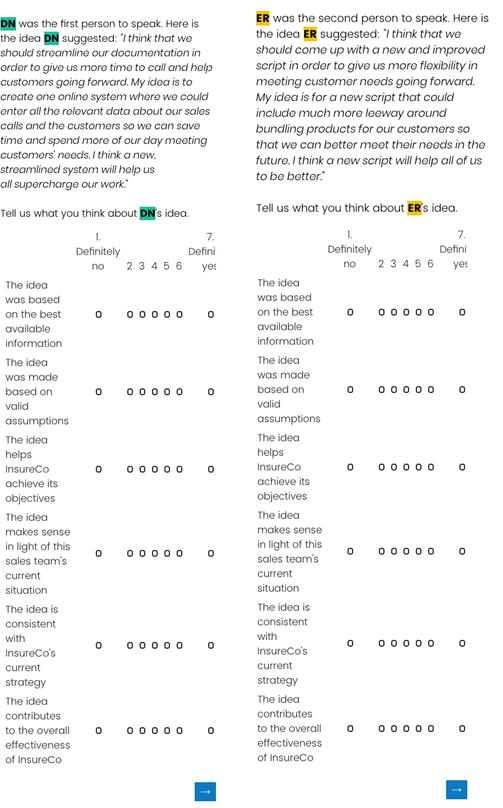
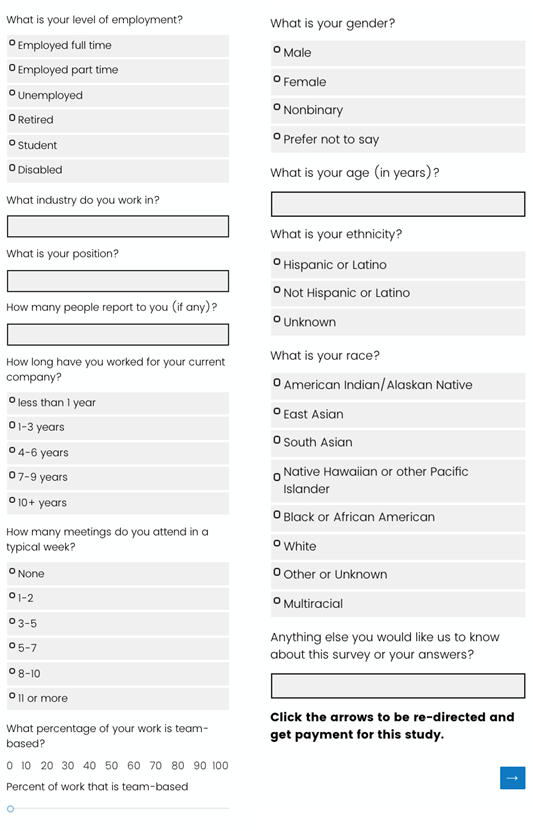
以及被试的人口统计学等控制变量。
数据分析
我们终于进入正题啦!
作者直接给了R文件,这样我就能知道作者用了哪些包。如果是用Rstudio打开,软件还会提示有包未安装,然后我们就可以让软件自动安装啦。
数据处理
导入原始数据
amp <- Study_1_raw_data_with_duplicate_variables
不过作者的公开数据里Excel命名为:Study 1 raw data cleaned.xlsx。另外,我直接运行这三行也不行,所以萜妹导入原始数据是用的以下语句:
install.packages("readxl")
library(readxl)
amp<-read_excel("Study 1 raw data cleaned.xlsx")
#如果显示没有路径,可以把文件路径写全。
#注意原始路径中的“\”要替换为“/”。
amp<-read_excel("C:/Users/Tie/Amplifying Voice in Organizations/Study 1 raw data cleaned.xlsx)
代码含义是:将同一文件夹下的Study 1 raw data cleaned.xlsx导入,并命名为amp。
运行后可以在Environment里看到amp。
清理重复与未完成
作者在Excel里进行了前期处理,比如识别并标注了重复IP、ID、未完成等。
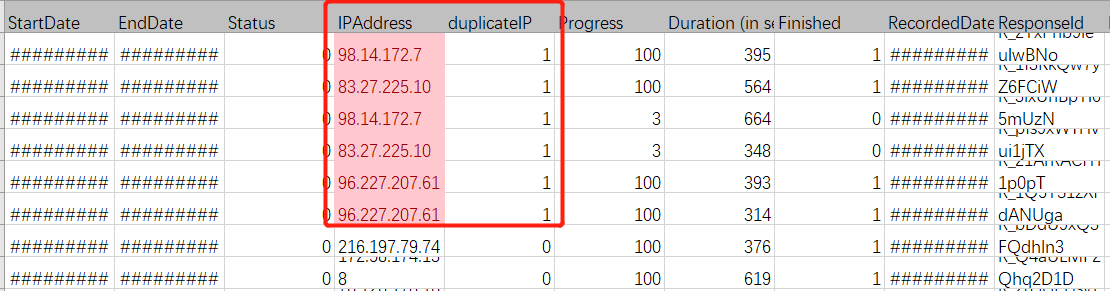
amp= subset(amp, amp$Finished==1)
amp= subset(amp, amp$duplicateIP==0)
amp= subset(amp, amp$duplicateID==0)
这里是不断在原来的amp中筛选出子集。比如,amp= subset(amp, amp$Finished==1)意味着只选中完成的被试。
注意力检验
amp=subset(amp, amp$attnchk1==1)
amp=subset(amp, amp$attnchk2==1)
清理完成后,还剩下1189个被试,这就是Study 1 working dataset.xlsx的原始版。
最终数据文件
amp <- Study_1_working_dataset
amp= subset(amp, amp$irrelevant==0)
作者导出Study 1 working dataset.xlsx后对题项进行了重命名并变量化。最终数据中还删除了不相关数据。同样,萜妹改为了:
amp<-read_excel("Study 1 working dataset.xlsx",na = "NA")
amp= subset(amp, amp$irrelevant==0)
前期数据检验
加载R包
如果以前没安装过,也是需要先利用install.packages(" “)语句安装的哦。
library(psych)
library(plyr)
library(dplyr)
人口统计学分析
#* Gender ####
amp$gender<-as.character(amp$gender)
amp$gender<-revalue(amp$gender,
c("1"="male", "2"="female", "3"="nonbinary", "4"="notsay"))
amp$gender<-as.factor(amp$gender)
table(amp$gender)
#* Age ####
describeBy(amp$age)
#* Race ####
amp$race<-as.character(amp$race)
amp$race<-revalue(amp$race,
c("1"="American Indian", "2"="East Asian", "3"="South Asian", "4"="Pacific Islander","5"="Black", "6"="White","7"="oth_unknnw", "8"="Multiracial"))
amp$race<-as.factor(amp$race)
table(amp$race)
# * Number of Reports ####
describeBy(amp$reports)
# * Tenure
amp$tenure<-as.character(amp$tenure)
amp$tenure<-revalue(amp$tenure,
c("14"="Less 1yr", "15"="1 to 3yrs", "19"="4 to 6yrs", "16"="7 to 9yrs","17"="10+yrs"))
table(amp$tenure)
上面的语句用来分析被试的人口统计学分布。性别、种族、任职年限的标签也替换了。(PS,作者分析的语句里漏了amp$race<-as.character(amp$race),小可爱们复现时记得自己加上。)
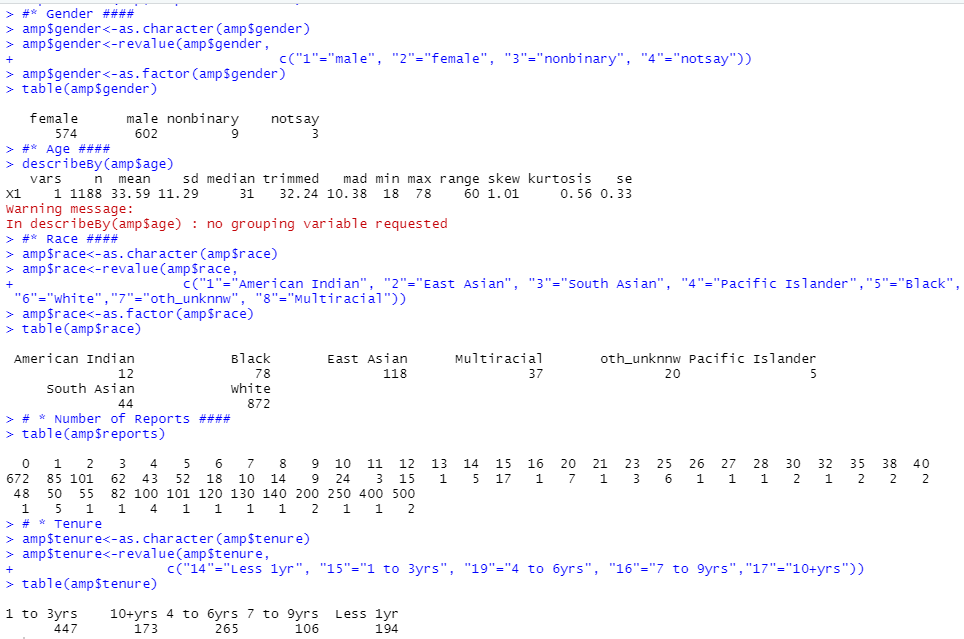

文章是这样汇报的,作者另外算了百分比。萜妹个人感觉这不是最优的R语句,应该是可以一步到位的。
操纵检验
# MANIPULATION CHECK: 1=yes someone endorse someone's idea; 2= no endorse ####
df=subset(amp, amp$ampcond=="amp")
table(df$ampchk)
df=subset(amp, amp$ampcond!="amp")
table(df$ampchk)
第一行:取amp中,ampcond这一项为“amp”的行,形成新数据集df。这其实就是Amplification实验组。
第二行,显示df中,ampchk这一列的分布。
第三行:取amp中,ampcond这一项不为“amp”的行,形成新数据集df。这是另外两个控制组。
第四行,显示df中,ampchk这一列的分布。
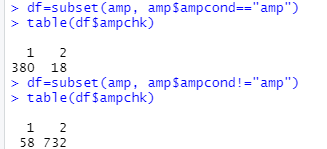
作者文章中并没有汇报操纵检验的结果,如果在SPSS中是会计算t值和显著性的。不过作者这里肯定还是通过了的。
特别提醒,即使有18+58个被试汇报结果与操纵不一致,但也是不能删除他们的!!!
检验信度
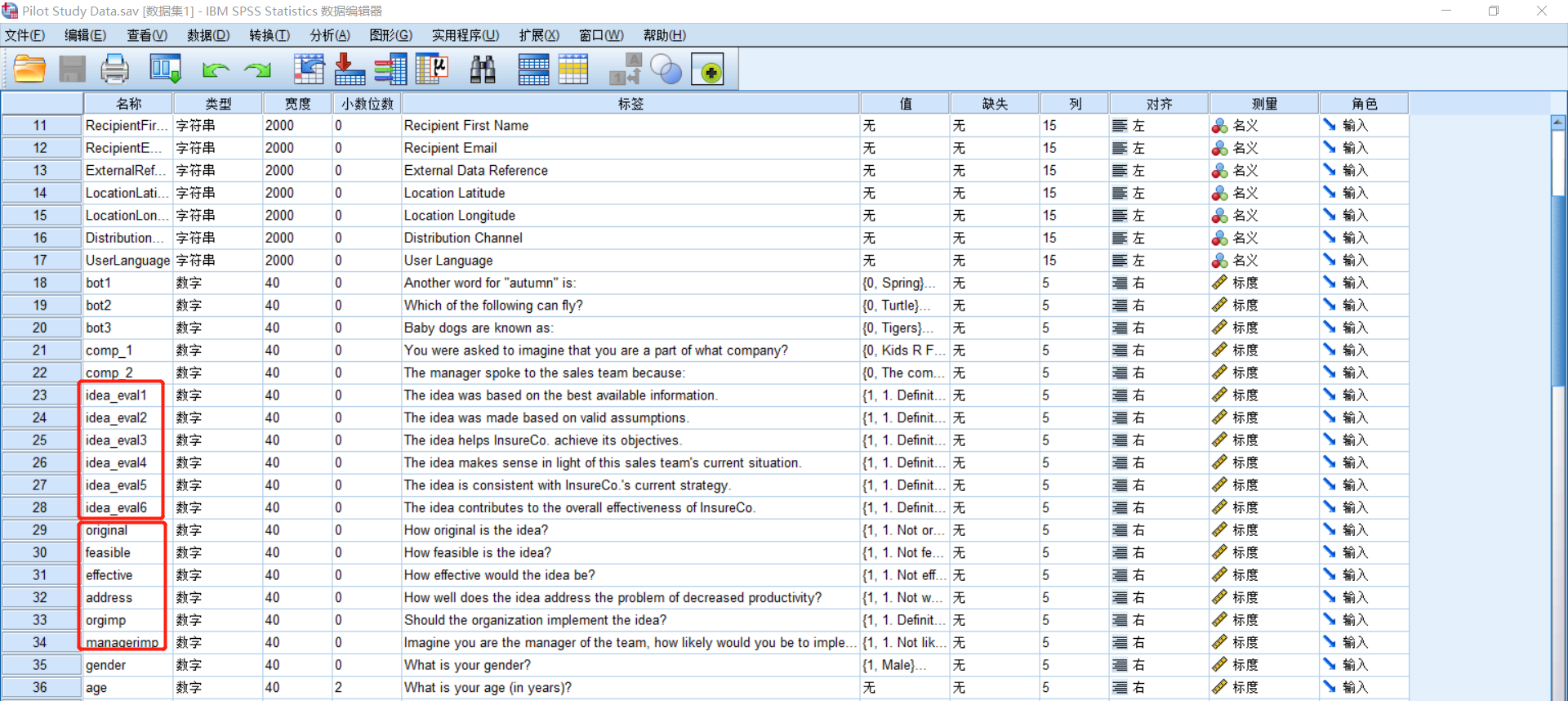
#* Idea Quality####
quality <- data.frame(amp[,c(210:215)])#voicer: idea quality (promotive & prohibitive)
alpha(quality)
第一行:取amp中第210-215列,形成新数据集quality。
第二行,计算quality的信度。
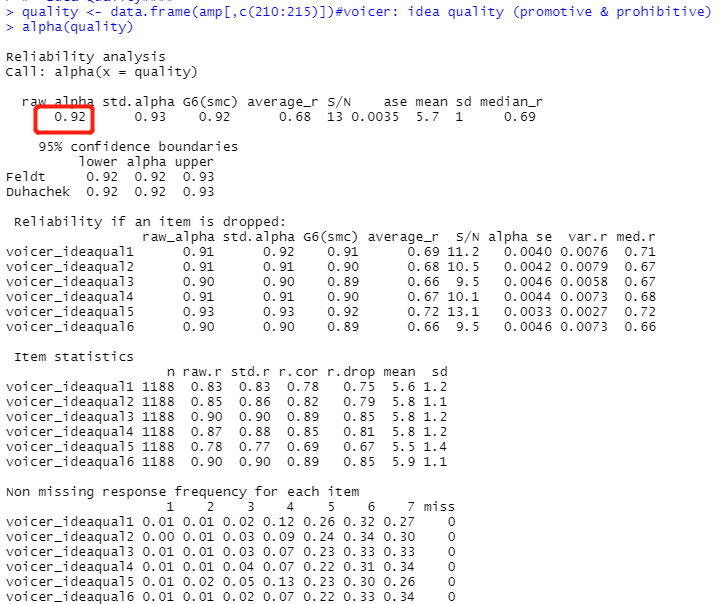
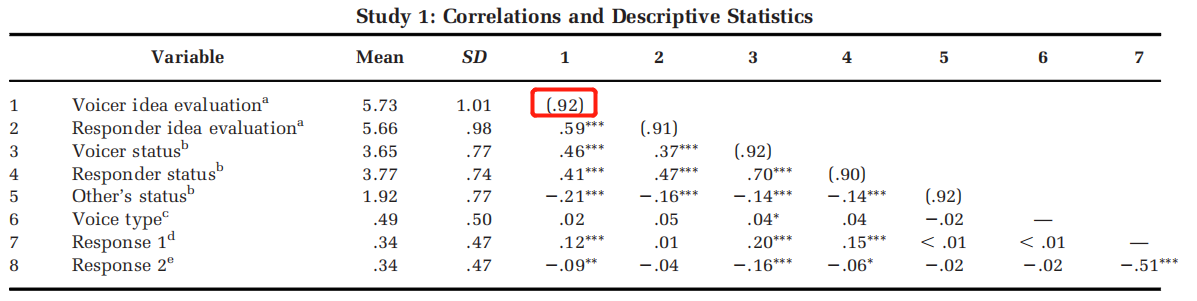
相关分析
amp$voicetype <-revalue(amp$type, c("prohibitive" ="0", "promotive"="1"))
amp$voicetype <- as.numeric(amp$voicetype)
amp$response1 <-revalue(amp$ampcond, c("additional" ="0", "silent"="0", "amp"="1"))
amp$response1 <- as.numeric(amp$response1)
amp$response2 <-revalue(amp$ampcond, c("additional" ="1", "silent"="0", "amp"="0"))
amp$response2 <- as.numeric(amp$response2)
针对操纵形成3个虚拟变量。作者这里是将voicetype设为促进性建言;将response1设为声援;将response2设为提出新想法。
amp$c_voiceridea <- amp$voicer_ideaqual
amp$c_responderidea<-amp$resp_ideaqual
amp$c_voicerstatus <- amp$status_voicer
amp$c_respstatus <- amp$status_resp
amp$c_othstatus<-amp$status_other
amp$c_voicetype<-amp$voicetype
amp$c_response1 <- amp$response1
amp$c_response2 <- amp$response2
在数据集amp中形成新的变量。
library(Hmisc)
library(car)
amp_corr<-amp[,c(268:275)]
amp_corr$c_voicetype<-recode(amp_corr$c_voicetype, "2=1;1=0")
amp_corr$c_response1<-recode(amp_corr$c_response1, "2=0; 1=1")
amp_corr$c_response2<-recode(amp_corr$c_response2, "2=1; 1=0")
第三行,取数据集amp中的268-275列为新数据集amp_corr。
第四-六行,对三个虚拟变量重新编码。萜妹猜测,因为c_response1和c_response2是一对互斥的虚拟变量,所以作者才在相关时对c_response1进行了反向。

假设检验
检验主效应和调节效应
amp$ampcond<-as.factor(amp$ampcond)
amp$ampcond <- relevel(amp$ampcond, ref = "amp")##Using amplification as baseline
amp$type<-as.factor(amp$type)
library(DescTools)
ampcond是操纵的response;type是操纵的建言类型。
第二行意为,将amp设为基准模型。
#* * Voicer Idea ####
res.aov_qual<-aov(voicer_ideaqual~ampcond*type, data=amp)
summary(res.aov_qual)
EtaSq(res.aov_qual, type = 2, anova = FALSE)
# Planned comparisons
TukeyHSD(res.aov_qual, which = "ampcond")
第一行,用数据集amp,做ampcond、type对voicer_ideaqual的方差分析,并将结果储存为res.aov_qual。
第二行,显示上述结果,比如自由度、F值、概率等。
第三行,得Eta的平方。
第四行,做主效应的比较,证明amp与其他两种情况确实有显著差异。
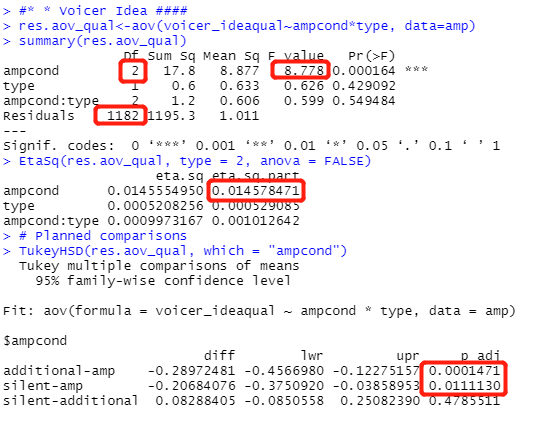

检验中介效应
#** AMP vs. Voices
df <- subset(amp, amp$ampcond!="silent")
mm<-lm(voicer_ideaqual~ampcond,df)
dv<-lm(status_voicer~voicer_ideaqual+ampcond,df)
summary(mediate(mm, dv, boot=TRUE, treat = "ampcond",mediator = "voicer_ideaqual", sims=5000))
第一行,取amp中,ampcond这一项不为“silent”的行,形成新数据集df。
第二行,用数据集df做ampcond对voicer_ideaqual的线性回归,并将结果储存为mm。
第三行,用数据集df做ampcond、voicer_ideaqual对status_voicer的线性回归,并将结果储存为dv。
第四行,根据mm、dv的结果做中介检验。


对因变量的描述性分析
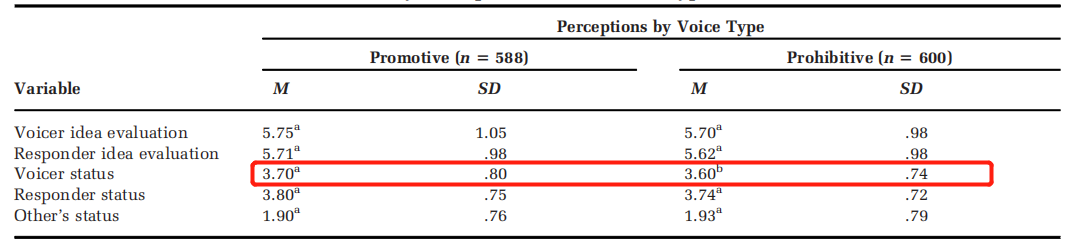
#* VOICE TYPE ####
describeBy(amp$voicer_ideaqual,amp$type)
describeBy(amp$resp_ideaqual,amp$type)
describeBy(amp$status_voicer,amp$type)
describeBy(amp$status_resp,amp$type)
describeBy(amp$status_other,amp$type)
这里就是按建言类型分组对不同的因变量进行描述性统计。
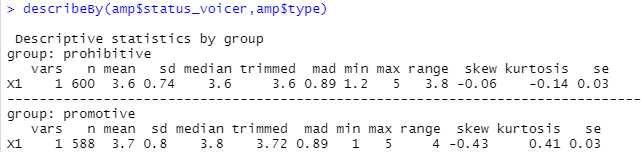
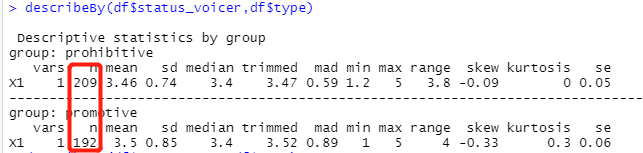
#* VOICE TYPE x RESPONSE CONDITION ####
df=subset(amp, amp$ampcond=='amp')
describeBy(df$voicer_ideaqual,df$type)
describeBy(df$resp_ideaqual,df$type)
describeBy(df$status_voicer,df$type)
describeBy(df$status_resp,df$type)
describeBy(df$status_other,df$type)
df=subset(amp, amp$ampcond=='silent')
describeBy(df$voicer_ideaqual,df$type)
describeBy(df$resp_ideaqual,df$type)
describeBy(df$status_voicer,df$type)
describeBy(df$status_resp,df$type)
describeBy(df$status_other,df$type)
df=subset(amp, amp$ampcond=='additional')
describeBy(df$voicer_ideaqual,df$type)
describeBy(df$resp_ideaqual,df$type)
describeBy(df$status_voicer,df$type)
describeBy(df$status_resp,df$type)
describeBy(df$status_other,df$type)
2*3的分组描述性统计是先把amp分为了三组数据,再分别分组做描述性统计。作者给的语句省略简化了,萜妹扩充了。
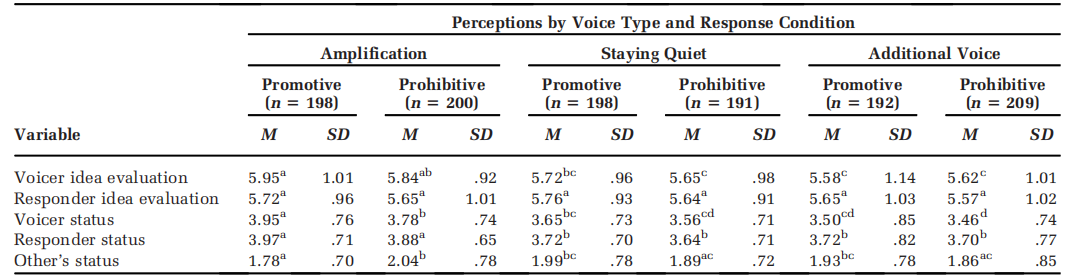
Study 2 & 3
study 2 和study 1 在操作上大同小异,萜妹这里就不讲啦。
小可爱有兴趣的话,还可以尝试在Study 1语句的基础上改编Study 2的语句,如果最后和文章结果一致,就能说明是真的掌握啦,hhh。
Study 3是一个现场干预实验,作者检验了Amplification能否被培训,员工是否会从中受益。
实验做的非常好,就是太复杂了,萜妹看完已经无力输出,所以小可爱们有兴趣自行查阅吼。
今天的推送就到这里啦。其实这篇文章不用R,用SPSS也能很轻松地得到结果。但是萜妹准备学R嘛,我们就从简单的一步步开始。
萜妹的R正在起步阶段。在写这篇推送之前,上述的语句,我几乎都没用过。但是仿完这次后,起码上面的语句我都会用了。所以对R感兴趣的小可爱们一起动起来吖。
然后,《复现》这个系列第一期想做其实的是多项式回归,毕竟后台有小可爱想要示范操作。但是我翻了好几个顶刊,最近都没有这方面的公开数据TAT,所以如果有留意到这方面信息的小可爱可以联系我。
另外,如果有其他有意思的公开数据也可以和萜妹分享吖。想和小可爱们,一起学习,共同进步~
原文链接: