类别变量的三阶交互
Kundro, T. G., & Rothbard, N. P. (2022). Does Power Protect Female Moral Objectors? How and When Moral Objectors’ Gender, Power, and Use of Organizational Frames Influence Perceived Self-Control and Experienced Retaliation. Academy of Management Journal. https://doi.org/10.5465/amj.2019.1383
小可爱们好,本期又是一次使用R的复现,文章涉及类别变量(性别)的交互效应。
整体介绍
这篇文章想要研究:在道德反对的情况下,权力是否会以同样的方式保护女性?
换言之:在发生道德反对的前提下,结构权力、性别和道德反对框架如何影响感知自我控制,进而影响对道德反叛的报复。
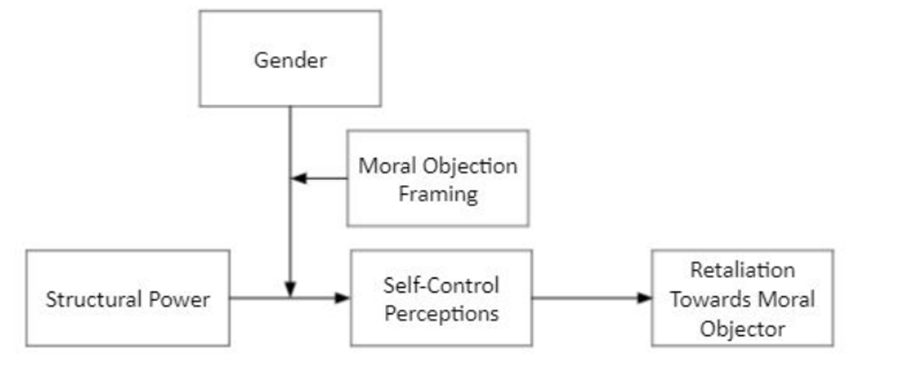
四个假设分别为 ① X对Y主效应、② 二阶交互、③ 三阶交互和 ④ 有中介的调节效应。
各研究分别为:
- 研究1 : 使用档案数据检验H1、H2;
- 补充研究 :在类似的数据集中重复检验H1、H2;
- 研究2 : 从TurkPrime招募被试,通过关键事件法,以报复者角度,检验H1、H2;
- 研究3 : 通过2×2×2在线情境实验检验H1-H4;
- 研究4 : 通过2×2×2在线行为实验检验H1-H4。
考虑到研究间的相似性,本次推送仅以Study 1和Study 3 为例。
公开数据
获取地址:https://osf.io/rju8b

这篇文章的作者分享的是.html 而不是直接的RMarkdown,我们想要复现需要自己在R里写语句。
Study 1
数据准备
导入原始数据
作者的提供的原始语句里没有这一步,我们需要自己先导入原始数据。
最方便的方式是在RStudio里找到文件点击【Import Dataset】,
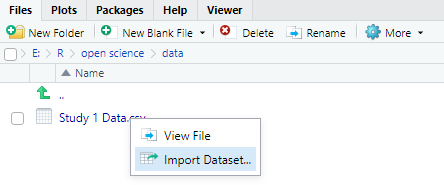
点击【Import】
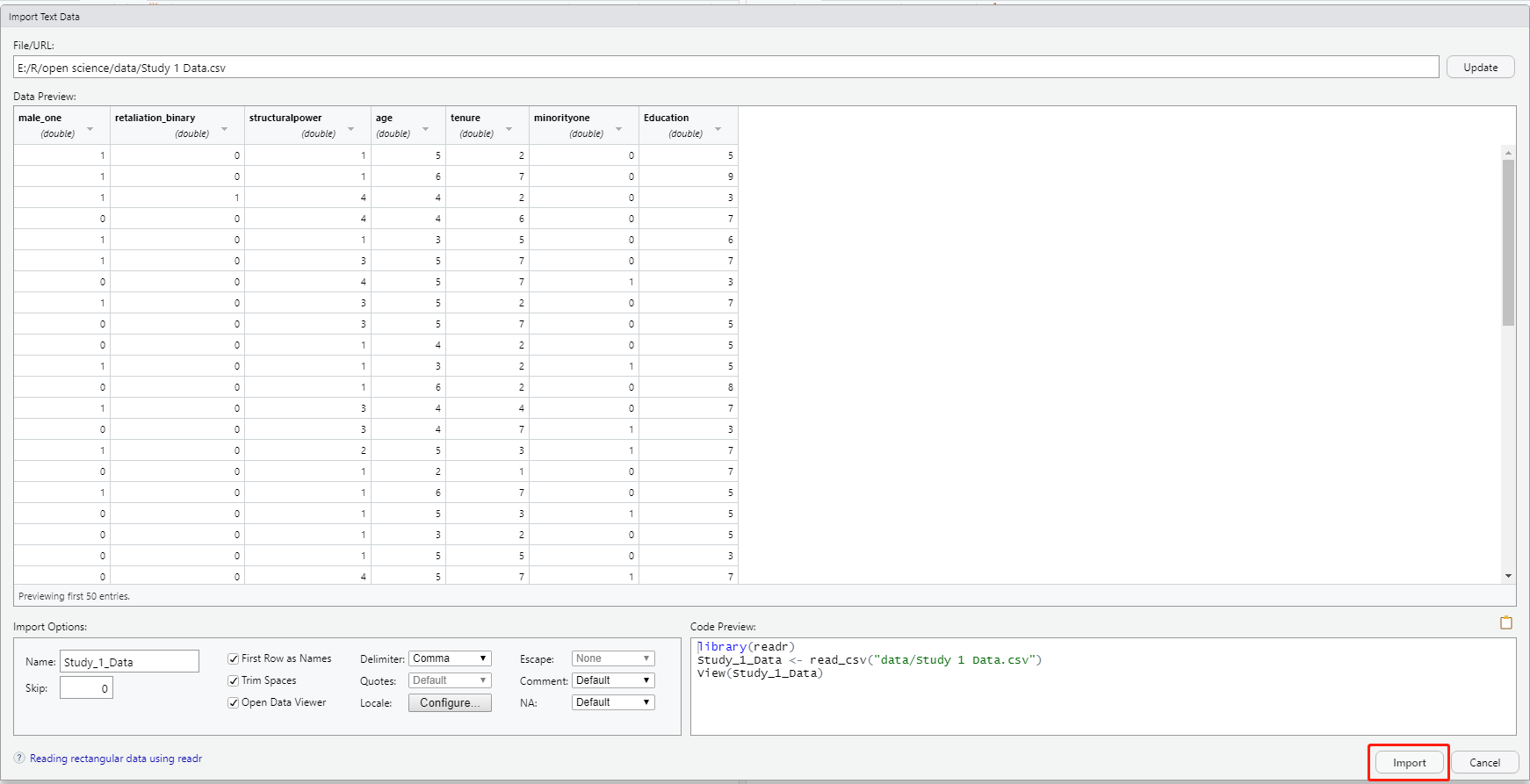
不过这样导入的数据名是原始的,所以我们可以在import options里进行修改,或者直接写语法。
library(readr)
data <- read_csv("data/Study 1 Data.csv")
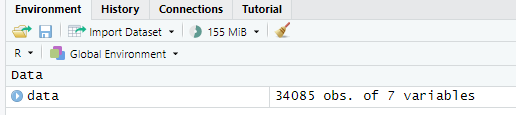
运行后可以在Environment里看到data。
数据清洗

可以看到原始数据里有些缺失值,所以我们得先删除。
###filtering down to complete data
data <-data %>% filter(structuralpower > -1)
data <-data %>% filter(male_one > -1)
data <-data %>% filter(Education > -1)
data <-data %>% filter(minorityone > -1)
data <-data %>% filter(tenure > -1)
data <-data %>% filter(age > -1)
数据量从34085变为了33715。

然后,有时候我们一组数据里会涉及多个模型和变量,比较复杂,可以生成一个单独的子集,方便后续处理。
library(dplyr)
subset <- data %>% select(structuralpower, male_one, tenure, age,minorityone, Education,retaliation_binary)
第一行意味着加载dplyr包,这不是Rstudio自动加载的包,所以第一次使用时,我们要手动加载一下。
第二行的意思是从data数据中,提取structuralpower, male_one, tenure等列,再单独成为一个Subset数据文件。
不过由于作者最后上传的数据就是最终的,所以我们做这步时后,数据结果是没有变化的。
相关分析
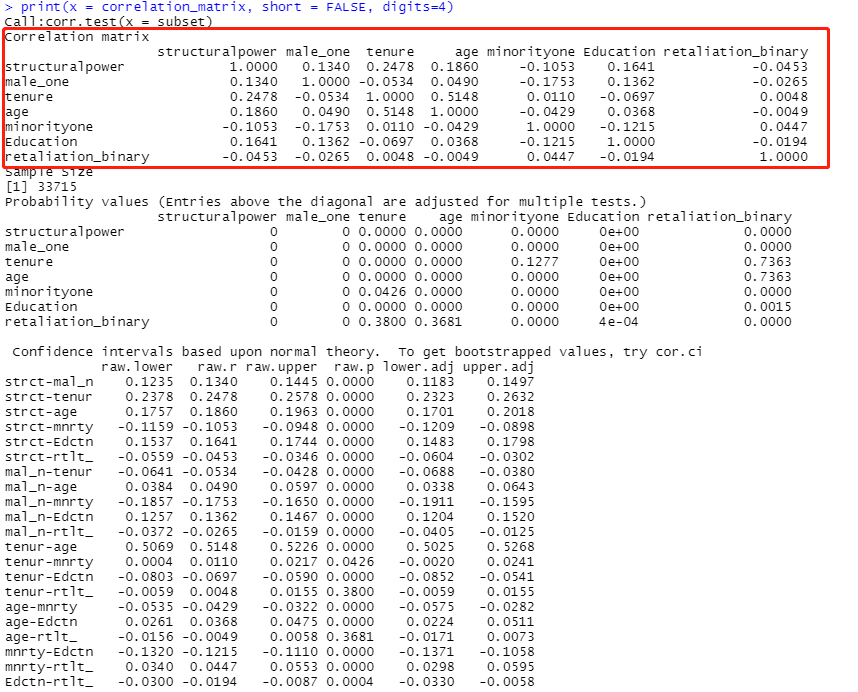
library(psych)
correlation_matrix<-corr.test(x=subset)
print(x = correlation_matrix, short = FALSE, digits=4)
第一行,加载Psych包;
第二行,算subset数据的相关,结果命名为correlation_matrix;
第三行,打印相关结果。Short意为控制打印内容数量,Digits意为打印时的小数位数。
描述性统计
psych::describe(subset)

假设检验
文中最后是进行了三次回归分析,生成了下表。
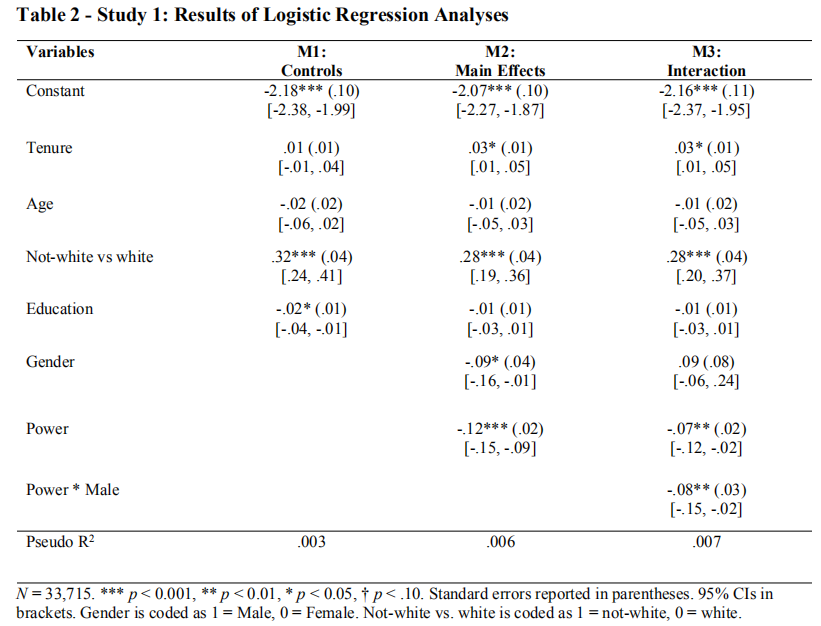
M1:控制组
系数与标准差
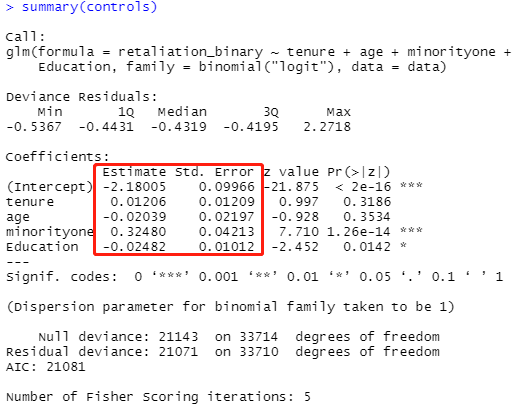
controls <- glm(retaliation_binary ~ tenure + age + minorityone + Education,data=data, family = binomial("logit"))
summary(controls)
第一行,建立广义线性模型,将结果名为controls。
- 结果变量-retaliation_binary
- 预测变量-tenure、age、minorityone和Education
- 数据来源-data
- 模型使用的误差分布和链接函数-binomial(“logit”)
第二行,显示controls。
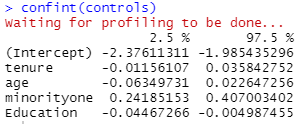
置信区间
confint(controls)
pseudo-r2
install.packages('pscl')
library(pscl)
pR2(controls)
这里使用的是pscl包,它不在Rstudio自带包中,所以在加载前先要安装。

M2:主效应
h1<-glm(retaliation_binary~ tenure + age + minorityone + Education + male_one + structuralpower,data=data, family = binomial("logit"))
summary(h1)
confint(h1)
pR2(h1)
计算主效应时,预测变量新增了structuralpower。
exp(coef(h1))
新增了比例值的计算


M3:交互效应
h2<-glm(retaliation_binary~ tenure + age + minorityone + Education + male_one * structuralpower , data=data, family = binomial("logit"))
summary(h2)
confint(h2)
pR2(h2)
exp(coef(h2))
计算交互效应时,预测变量又新增了 交互项。
注意这里是直接用*表示的,即male_one * structuralpower意味着预测变量中包含male_one和structuralpower以及二者交互项。
install.packages('interactions')
library(interactions)
sim_slopes(h2, pred = structuralpower, modx = male_one, johnson_neyman = FALSE)
交互效应需要计算简单斜率,这里使用的是interactions包,它也不在Rstudio包中,要先要安装。

稳健性分析
去除控制变量
就是在做回归时不纳入控制变量,语句原理没有改变。我这里就不重复了。
将X视为类别变量
这个部分也不算重点,所以有兴趣的小可爱们可以去自行尝试。
Study 3
数据准备
导入原始数据
library(readr)
data <- read_csv("data/Study 3 data.csv")
前期分析
描述性统计
subset <- data %>% dplyr::select(p_gender, p_age, p_white, p_work_exp)
psych::describe(subset)
对人口统计学变量进行描述性统计。

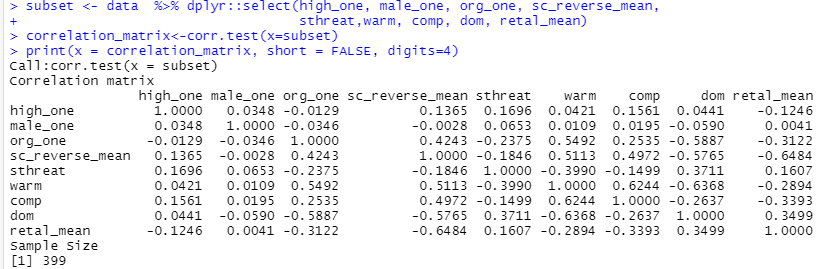
subset <- data %>% dplyr::select(high_one, male_one, org_one, sc_reverse_mean,sthreat,warm, comp, dom, retal_mean)
correlation_matrix<-corr.test(x=subset)
print(x = correlation_matrix, short = FALSE, digits=4)
这里没纳入人口统计学变量了。
psych::describe(subset)
再进行核心变量的描述性统计,就不截图了。
计算各组对Y的均值、系数等
data %>% group_by(high_one, male_one, org_one) %>%
summarise(retal_mean= mean(retal_mean))
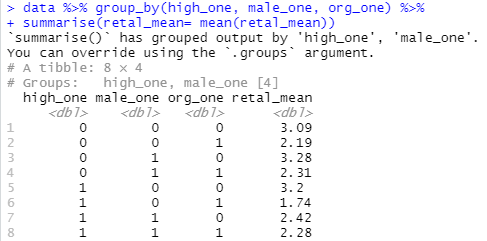
根据均值结果可制作出如下柱状图。
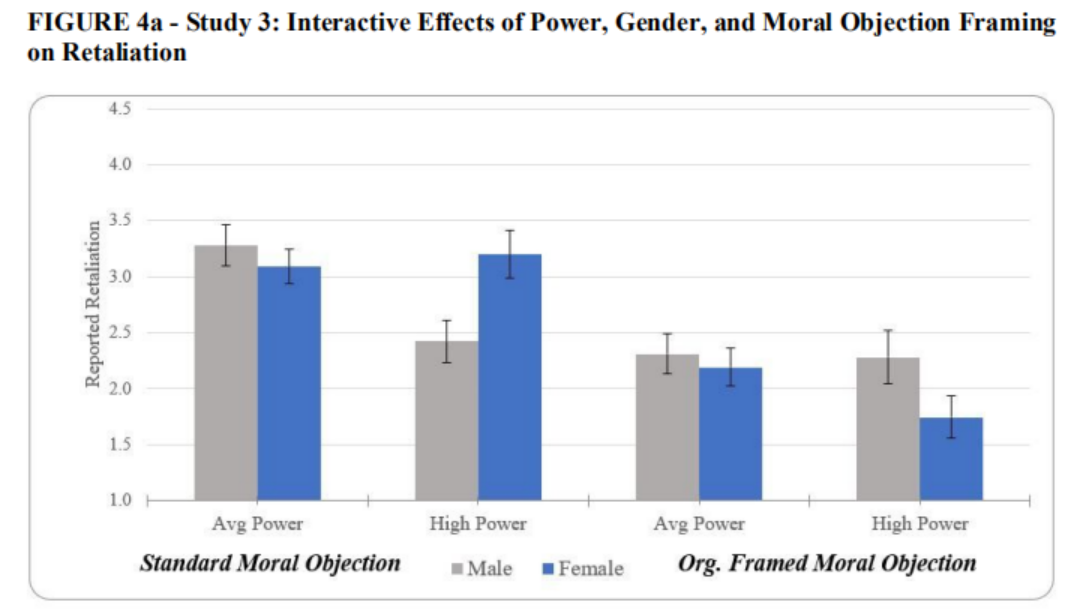
modeld <-lm (retal_mean~high_one* male_one*org_one, data = data)
install.packages('emmeans')
library(emmeans)
emmeans(modeld, ~ high_one | male_one | org_one, type="response" )
据此可得各组对Y的系数、标准误及置信区间

检验信度
data %>% dplyr::select(s_c_1:s_c_3) %>% psych::alpha() %>% summary
这里计算了s_c的信度。

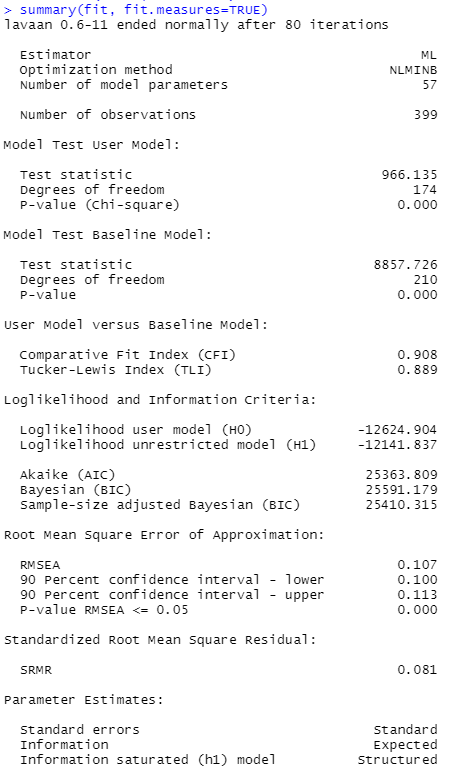
检验CFA
library(lavaan)
model <- 'scx =~ s_c_1 + s_c_2 + s_c_3
warmx =~ warm1 + warm2 + warm3
compx =~ comp1 + comp2 + comp3
domx =~ dom1 + dom2 + dom3
selfthreatx =~ selfthreat1 + selfthreat2 + selfthreat3 + selfthreat4
retalx =~ retal_m1 + retal_m2 + retal_m3 + retal_m4 + retal_m5
'
fit <-cfa(model, data=data)
summary(fit, fit.measures=TRUE)
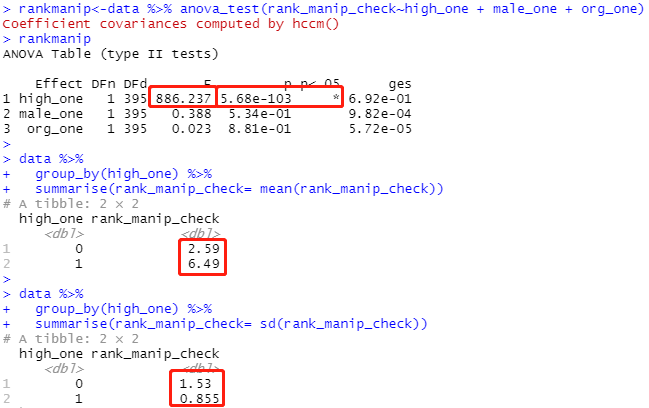
操纵检验
install.packages('rstatix')
library(rstatix)
rankmanip<-data %>% anova_test(rank_manip_check~high_one + male_one + org_one)
rankmanip
data %>%
group_by(high_one) %>%
summarise(rank_manip_check= mean(rank_manip_check))
data %>%
group_by(high_one) %>%
summarise(rank_manip_check= sd(rank_manip_check))

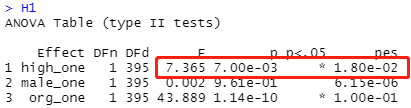
假设检验
H1:主效应
H1<-data %>% anova_test(retal_mean~high_one+ male_one +org_one, effect.size="pes")
H1

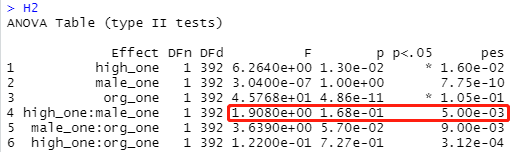
H2:二阶交互
#H2
H2<-data %>% anova_test(retal_mean~high_one*male_one + male_one* org_one +org_one*high_one, effect.size="pes")
H2
H3:三阶交互
H3<-data %>% anova_test(retal_mean~high_one* male_one*org_one,aeffect.size="pes")
H3
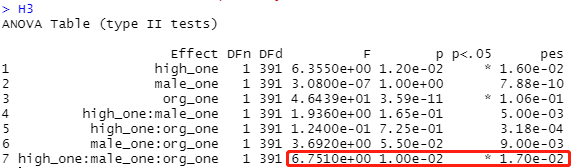

二阶的斜率分析
##first, creating overall model error term
model <-lm (retal_mean~high_one* male_one*org_one, data = data,effect.size="pes")
## probing two-way interactions
data %>% group_by(org_one) %>%
anova_test (retal_mean~ high_one * male_one, error = model, effect.size="pes")
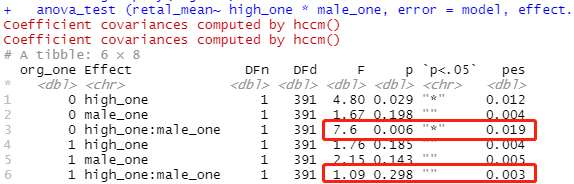

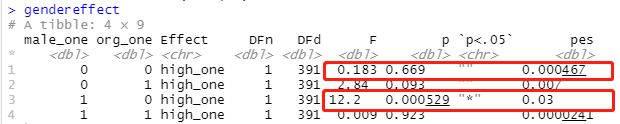
gendereffect <- data %>%
group_by(male_one, org_one) %>%
anova_test(retal_mean ~ high_one, error = model, effect.size="pes")
gendereffect
原始的版本我跑的时候胡报错,所以我修改了下。

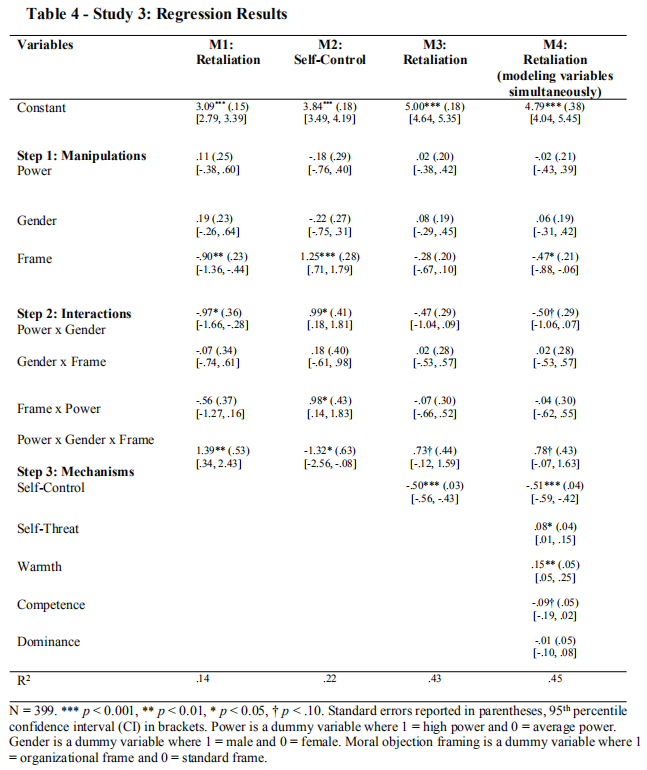
H4:有中介的调节
#building tables with PROCESS for r (beta)
#m1
#process (data=data,y="retal_mean",x="high_one",w="male_one",
# z="org_one",model=3,contrast=1,normal=1,conf=95,save=1)
#m2 and 3
#process (data=data,y="retal_mean",x="high_one",w="male_one",
# z="org_one",m="sc_reverse_mean",model=12,contrast=1,normal=1,conf=95,save=1)
#m4-9
#process (data=data,y="retal_mean",x="high_one",w="male_one",
# z="org_one",m=c("sc_reverse_mean","warm","comp", "dom", "sthreat"),
#model=12,contrast=1,normal=1,conf=95,save=1)
作者没有给出这个部分的结果,我也没复现出来,所以等我下次再专门研究研究吧。
今天的推送就到这里啦。这期和上次的实验复现不同,作者用了很多R包,往往能够一行代码就得到复杂的结果。
但也是因为调用了R包,所以让我这个小白,找R包找得昏天暗地。不过有提高找R包的技能,也算成长了,hhh。
另外,上周有个噩耗,我EndNote同步出现了bug,然后发生了大无语事件,我的分组全无了TAT。
所以我趁此机会,重新分了下组,并整理了些分组思路,下周和小可爱们分享吧。
下期预告:《经验丨EndNote分组参考》
往期推送:
原文链接: