R丨数据分析基础版
小可爱们好,萜妹2022年度Flag中有一条是“熟练运用R进行数据分析”,所以今年我有在这方面进行些学习和尝试,今天来和大家分享、交流吖。
我们先从最基础的数据分析开始,本次仅介绍单层模型(阅读量过3k更新进阶版)。
注:【】内字符为可根据模型与喜好替换。
各部分语法介绍
Step 1:导入原始数据
首先,我自己的习惯是将数据文件和Rproject放在同一个文件夹,这样方便后续调用。

其次,要提醒大家的是,如果第一次使用R包,需要先安装它(系统自带的除外,不知道是不是自带的,你就都安装试试)。
安装R包的语句示例:
install.packages("openxlsx")
后续我就不再强调这个问题了。
最后,数据导入的方式千千万万种,我这里仅介绍几种,掌握一种就行。
xlsx格式
library(openxlsx)
data <- read.xlsx("R.xlsx", )
所用R包:openxlsx。
- 第一行:调用openxlsx包。
- 第二行:将【R.xlsx】读取,并命名为【data】。
csv格式
如果使用csv格式,也可以用readr包。
library(readr)
data <- read_csv("data/Study 1 Data.csv")
所用R包:readr。
- 第一行:调用readr包。
- 第二行:将【data/Study 1 Data.csv】读取,并命名为【data】。
运行后可以在Environment里看到data。
点击版
如果不想写语法,大家还可以在RStudio里找到文件点击Import Dataset。
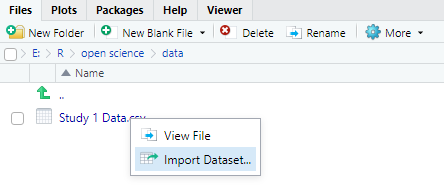
点击Import。
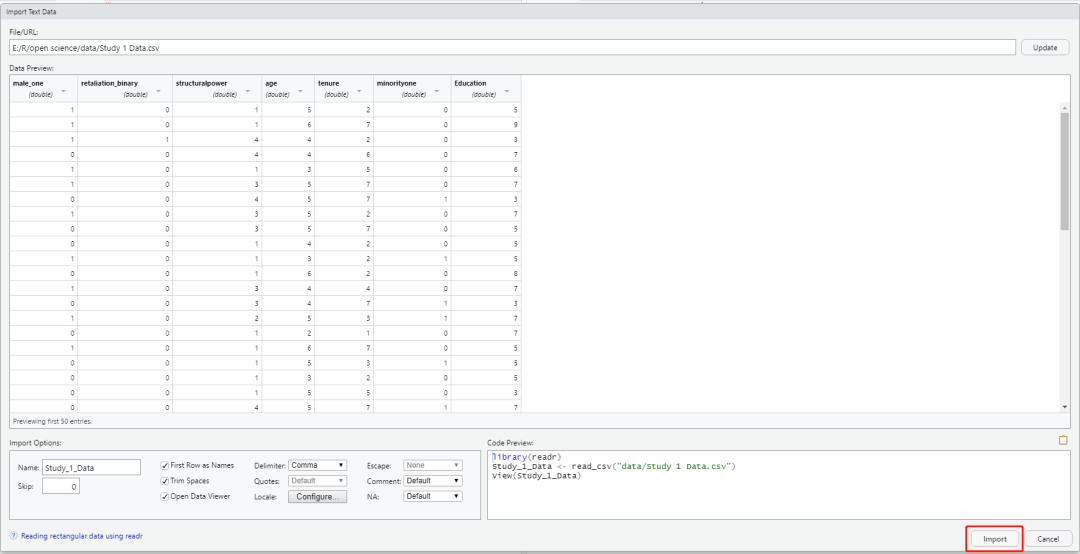
不过这样导入的数据名是原始的,所以我们可以在import options里进行修改。
Step 2:信效度
信度
library(dplyr)
alphaX <- data %>% select(X1:X4)
library(psych)
alpha(alphaX)
所用R包:dplyr、psych。
- 第一行:调用dplyr包。
- 第二行:在【data】中,选择【X1至X4】这几列,其将形成新的数据文件,并命名为【alphaX】。
- 第三行:调用psych包。
- 第四行:计算【alphaX】的信度。
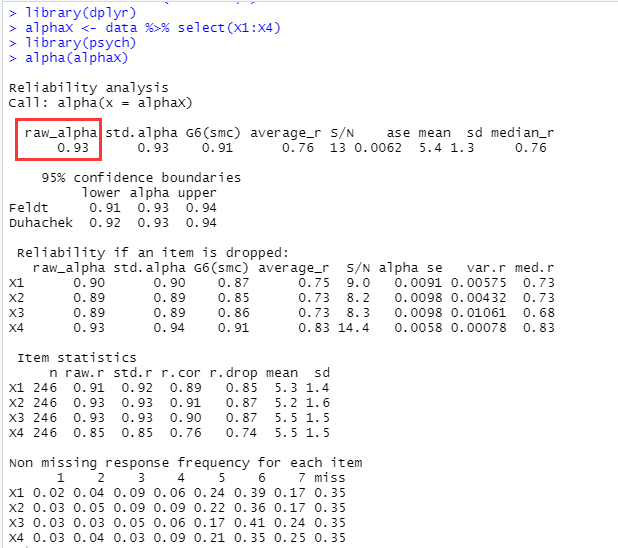
不过,可以看到上面的输出结果很长,并且每次都会新生成一个数据文件。
所以,我们可以改成下面这种形式:
data %>% dplyr::select(X1:X4) %>% psych::alpha() %>% summary
data %>% dplyr::select(M1:M3) %>% psych::alpha() %>% summary
data %>% dplyr::select(Y1:Y5) %>% psych::alpha() %>% summary
data %>% dplyr::select(W1:W3) %>% psych::alpha() %>% summary

效度
library(lavaan)
model4 <- 'CFAX =~ X1 + X2 + X3 + X4
CFAM =~ M1 + M2 + M3
CFAY =~ Y1 + Y2 + Y3 + Y4 + Y5
CFAW =~ W1 + W2 + W3'
fit4 <-cfa(model4, data=data)
summary(fit4, fit.measures=TRUE)
所用R包:lavaan。
- 第一行:调用lavaan包。
- 第二行:构建一个CFA的model,并命名为【model4】。
- 第三行:利用【data】中的数据,计算【model4】的拟合指数,并将结果命名为【fit4】。
- 第四行:汇报【fit4】的各指标。
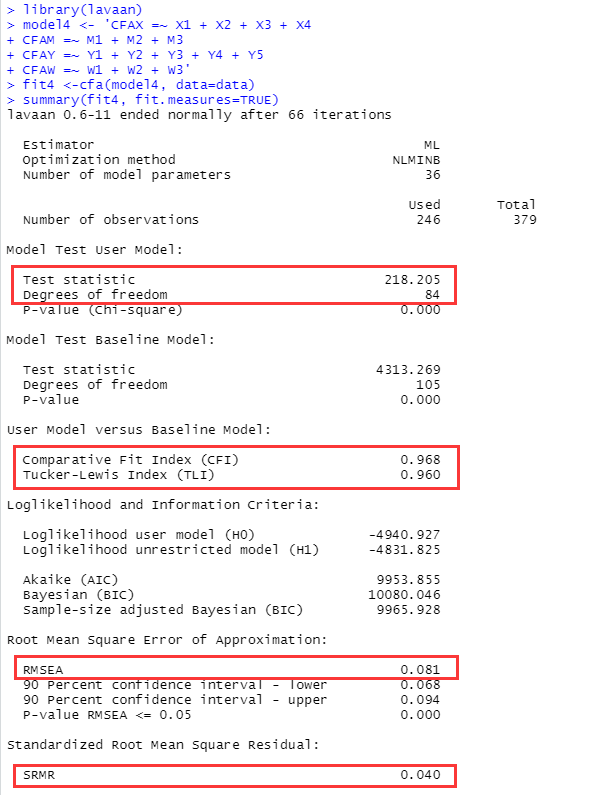
后续大家还要按需来汇报替代模型的CFA结果。
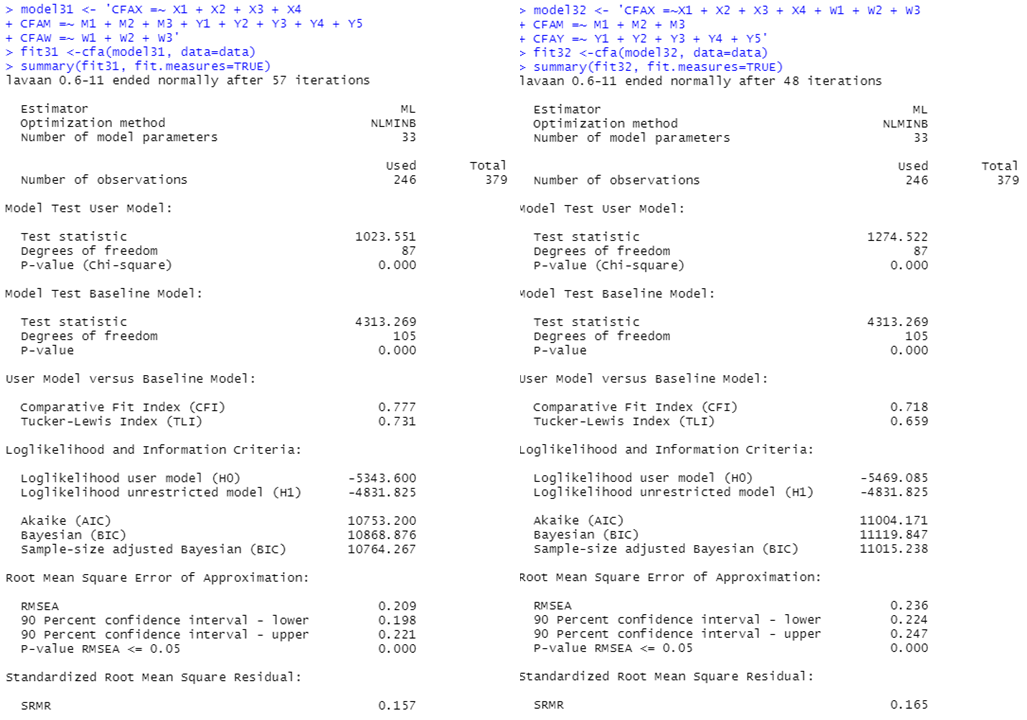
model31 <- 'CFAX =~ X1 + X2 + X3 + X4
CFAM =~ M1 + M2 + M3 + Y1 + Y2 + Y3 + Y4 + Y5
CFAW =~ W1 + W2 + W3'
fit31 <-cfa(model31, data=data)
summary(fit31, fit.measures=TRUE)
model32 <- 'CFAX =~X1 + X2 + X3 + X4 + W1 + W2 + W3
CFAM =~ M1 + M2 + M3
CFAY =~ Y1 + Y2 + Y3 + Y4 + Y5'
fit32 <-cfa(model32, data=data)
summary(fit32, fit.measures=TRUE)
Step 2:描述性统计
均值、标准差
确定信效度都通过检验后,我们再来进行描述性分析和假设检验。
subset <- data %>% select(X:W)
describe(subset)
所用R包:dplyr、psych。
- 第一行:在【data】中,选择【X至W】这几列,其将形成新的数据文件,并命名为【subset】。
- 第二行:汇报【subset】的描述性信息。
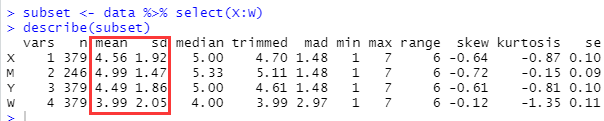
这里也可以一行到位,不过【subset】后续在计算相关时也会用到,所以我们还是不简化了。
相关系数
correlation<-corr.test(x=subset)
print(x = correlation, short = FALSE, digits=3)
所用R包:psych。
- 第一行:计算【subset】的相关矩阵,将其结果命名为【correlation】。
- 第二行:汇报【subset】的描述性信息。
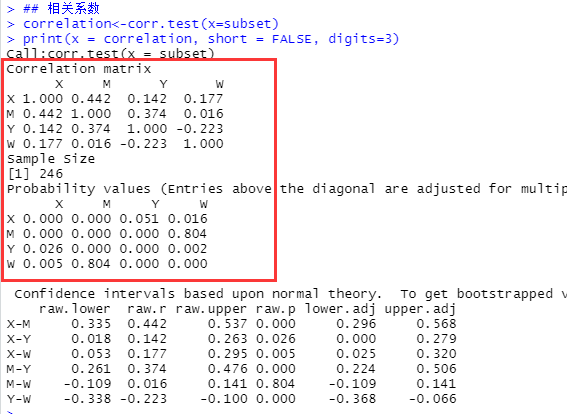
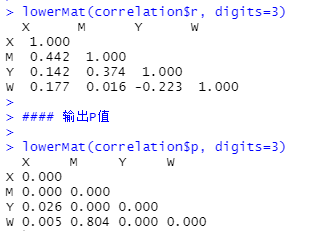
为了便于汇报,我们也可以直接输出对应指标的下三角形。
lowerMat(correlation$r, digits=3)
lowerMat(correlation$p, digits=3)
- digits=3,即为保留3位小数。
Step 4:假设检验
变量标准化
data$ZX=scale(data$X,center = TRUE, scale = TRUE)
data$ZW=scale(data$W,center = TRUE, scale = TRUE)
data$int=data$ZX * data$ZW
- 第一行:将【data】中的【X】标准化,并将其结果储存为【data】中的【ZX】。
- 第二行:将【data】中的【W】标准化,并将其结果储存为【data】中的【ZW】。
- 第三行:将【data】中的【ZX】和【ZW】相乘,并将其结果储存为【data】中的【int】。
路径分析
mome <-'M~ a0* X + W +a1*int
Y ~ b*M + X + W +int
slope_h: = a0+a1*(2.05)
slope_l: = a0-a1*(2.05)
ind_h: = slope_h*b
ind_l: = slope_l*b
ind_d: =ind_h-ind_l'
所用R包:lavaan。
- 第一行:根据假设,构建一个结构方程模型的model,并命名为【mome】。
这里的编写逻辑其实和Mplus中很像,【a0】、【a1】、【b】是指模型估算出的系数,用于后续效应量的计算。【2.05】是我们前文计算出的W的标准差。
自定义重复抽样种子
set.seed(1)
如果不写这一句,每次Bootstrap的结果都可能会不同,所以为了结果可重复性,我个人还是建议加上这句。不过括号中的数字是【1】还是【1234567】,这就无所谓了。
计算bootstrap
mome.fit<-sem(mome,data=data,se="bootstrap", bootstrap=5000)
利用【data】中的数据,计算【mode】,进行Bootstrap【5000】次的结果,并命名为【mome.fit】。
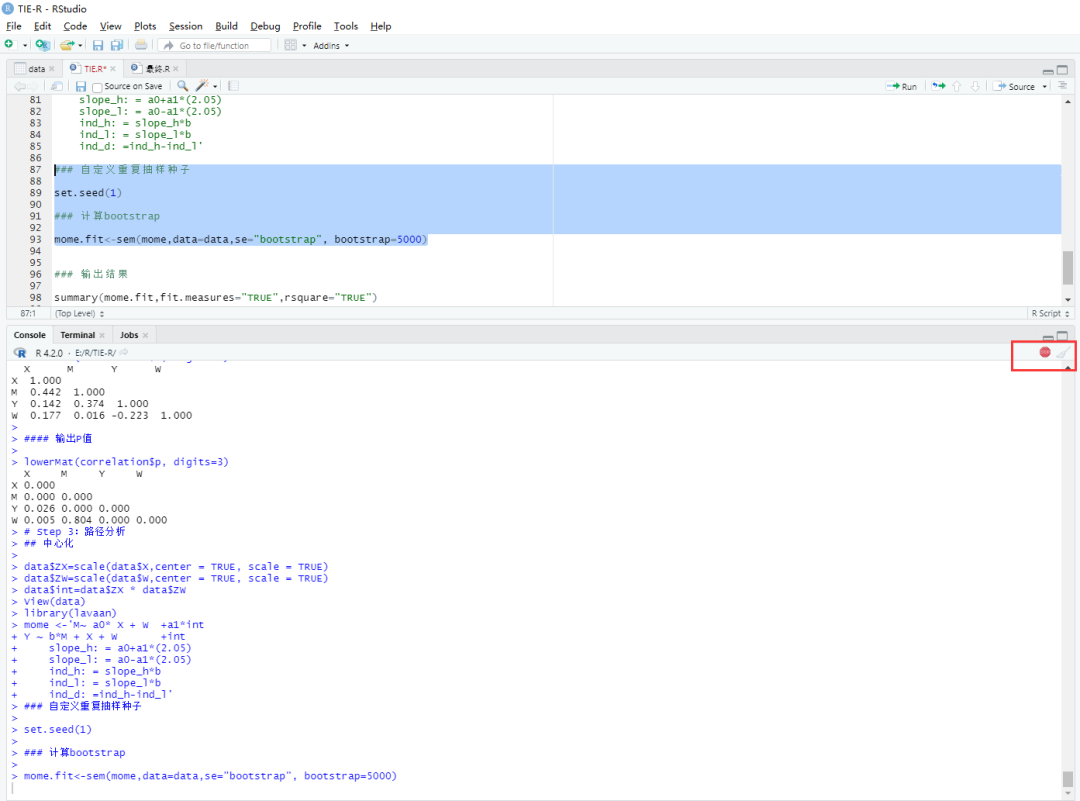
这种方式计算Bootstrap会有些慢。在软件运算时,右上角会显示一个小红点,等红点消失才代表运算完成,大家要耐心等待。
输出结果
summary(mome.fit,fit.measures="TRUE",rsquare="TRUE")
输出【mome.fit】的结果。
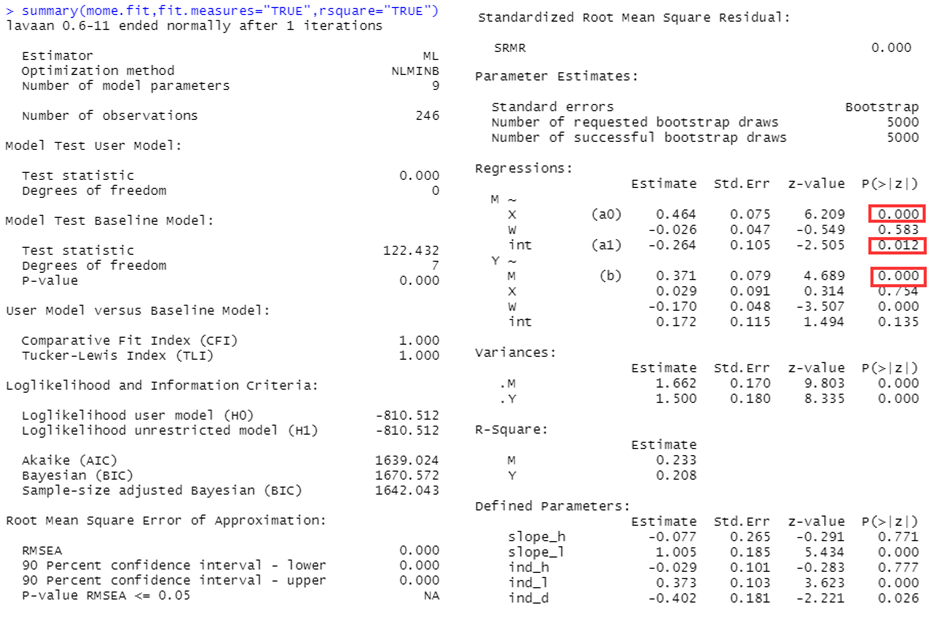
直到这一步,才会在输出区域有显示。
置信区间
parameterestimates(mome.fit,boot.ci.type="perc",standardize=TRUE)
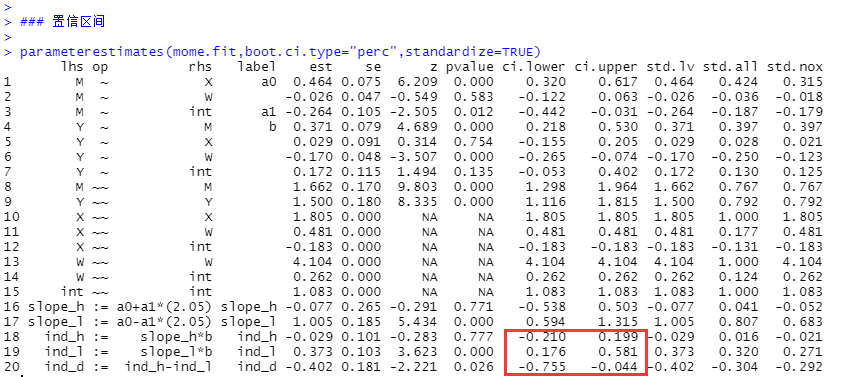
在涉及变量较多时,有时候结果会显示不全。我们在任意位置运行以下语句即可。
options(max.print=1000000)
整体语法汇总
## Step 1:导入原始数据
library(openxlsx)
data <- read.xlsx("R.xlsx", )
## Step 2:信效度+描述性统计
### 信度
library(dplyr)
library(psych)
data %>% dplyr::select(X1:X4) %>% psych::alpha() %>% summary
data %>% dplyr::select(M1:M3) %>% psych::alpha() %>% summary
data %>% dplyr::select(Y1:Y5) %>% psych::alpha() %>% summary
data %>% dplyr::select(W1:W3) %>% psych::alpha() %>% summary
### CFA
library(lavaan)
model4 <- 'CFAX =~ X1 + X2 + X3 + X4
CFAM =~ M1 + M2 + M3
CFAY =~ Y1 + Y2 + Y3 + Y4 + Y5
CFAW =~ W1 + W2 + W3'
fit4 <-cfa(model4, data=data)
summary(fit4, fit.measures=TRUE)
model31 <- 'CFAX =~ X1 + X2 + X3 + X4
CFAM =~ M1 + M2 + M3 + Y1 + Y2 + Y3 + Y4 + Y5
CFAW =~ W1 + W2 + W3'
fit31 <-cfa(model31, data=data)
summary(fit31, fit.measures=TRUE)
model32 <- 'CFAX =~X1 + X2 + X3 + X4 + W1 + W2 + W3
CFAM =~ M1 + M2 + M3
CFAY =~ Y1 + Y2 + Y3 + Y4 + Y5'
fit32 <-cfa(model32, data=data)
summary(fit32, fit.measures=TRUE)
## 均值、标准差
options(max.print=1000000)
subset <- data %>% select(X:W)
describe(subset)
## 相关系数
correlation<-corr.test(x=subset)
print(x = correlation, short = FALSE, digits=3)
#### 输出下三角形
lowerMat(correlation$r, digits=3)
#### 输出P值
lowerMat(correlation$p, digits=3)
# Step 3:路径分析
## 中心化
data$ZX=scale(data$X,center = TRUE, scale = TRUE)
data$ZW=scale(data$W,center = TRUE, scale = TRUE)
data$int=data$ZX * data$ZW
## 路径分析
library(lavaan)
mome <-'M~ a0* X + W +a1*int
Y ~ b*M + X + W +int
slope_h: = a0+a1*(2.05)
slope_l: = a0-a1*(2.05)
ind_h: = slope_h*b
ind_l: = slope_l*b
ind_d: =ind_h-ind_l'
### 自定义重复抽样种子
set.seed(1)
### 计算bootstrap
mome.fit<-sem(mome,data=data,se="bootstrap", bootstrap=5000)
### 输出结果
summary(mome.fit,fit.measures="TRUE",rsquare="TRUE")
### 置信区间
parameterestimates(mome.fit,boot.ci.type="perc",standardize=TRUE)
啦啦啦,这篇推送就到这里啦。
萜妹在学习新方法和新技术的时候,是一个非常目标导向的人,所以我对R数据分析的学习几乎都是依靠复现他人结果。
我在这个过程中,实现了R数据分析的入门,所以我想把经验整理出来,让小可爱们也试试。
我们先成功复现出他人结果,再依葫芦画瓢,去分析自己的模型吧。祝大家都顺利。
最后,如果大家对R数据分析有兴趣,欢迎多多留言分享。等阅读量过3k,我就更新进阶版!
相关资料参考:
部分语法改编于:https://b23.tv/cZt2A0Q
操作数据改编于:Heng & Fehr(2022)中的Study 3A。
Heng, Y. T., & Fehr, R. (2022). When you try your best to help but don’t succeed: How self-compassionate reflection influences reactions to interpersonal helping failures. Organizational Behavior and Human Decision Processes, 171. https://doi.org/10.1016/j.obhdp.2022.104151
往期推送
原文链接: