Mplus丨跨层有调节的中介模型检验
小可爱们好,好久没进行顶刊复现了。今天带大家一起复现Mplus中跨层有调节的中介模型。
Wong, M.-N., Cheng, B. H., Lam, L. W.-Y., & Bamberger, P. A. (2022). Pay Transparency as a Moving Target: A Multi-Step Model of Pay Compression, I-Deals, and Collectivist Shared Values. Academy of Management Journal. https://doi.org/10.5465/amj.2020.1831
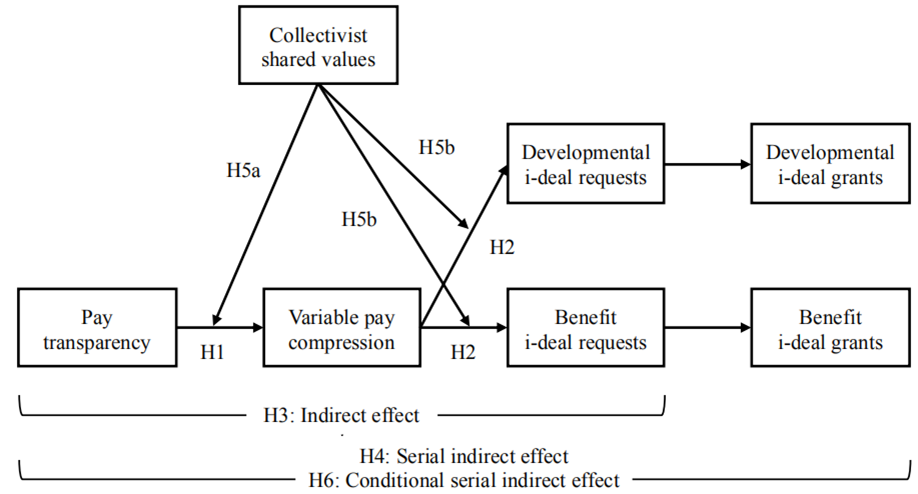
整体介绍
故事的大致逻辑是:薪酬透明度可能会揭示具有相似工作级别的员工之间的薪酬差异,这将被视为异常现象。为了避免上述情况,领导会使员工彼此间的薪酬更加相似(即可变薪酬压缩)。员工进而会将薪酬调整的请求转移到不易观察到的形式(即特殊交易,尤其是非货币特殊交易,如额外的假期、额外的培训)。这些请求也更有可能会被允许。在鼓励个人密切观察和监督其同伴的集体主义共同价值观下,越有可能发生上述的隐藏性请求。
简而言之,公司层面的薪酬透明度,会导致可变薪酬压缩,进而导致员工特殊交易请求率与通过率的提高;上述间接效应将在以集体主义共同价值观为特征的企业中被放大。
公开数据
获取地址: https://osf.io/nuvge/.

各研究分别为:
- 研究1:采用实验,检验假设1和5a;
- 研究2:采用问卷,检验所有假设。
本次主要分享跨层模型在Mplus中的处理方式,仅以Study 2 为例。
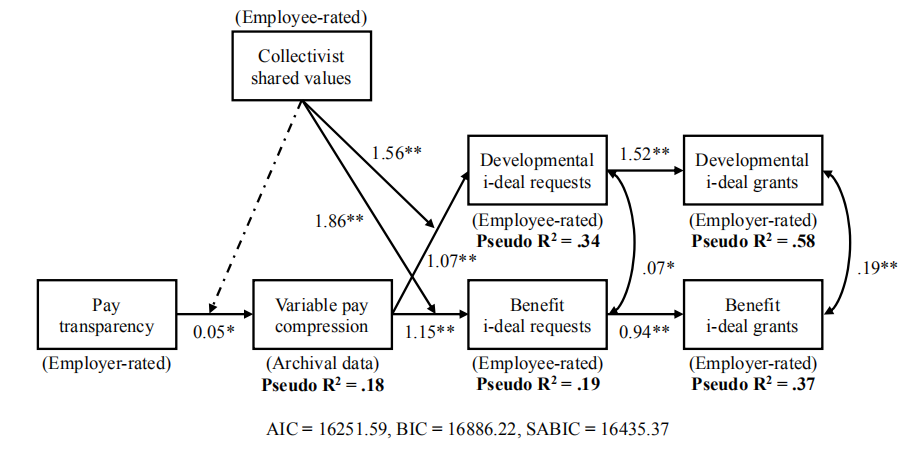
结果复现
语法解读
数据导入
DATA:
FILE = "Data_Study_2.dat";
意为后续分析数据为同文件夹下的Data_Study_2.dat。
变量命名
VARIABLE:
NAMES = cid
num_emp revenue oten_sd age_sd edu_sd gen_div
oten_mc oten_mc2 bp_gini bp_cv
pt_p1 pt_p2 pt_p3 pt_p4
pt_o1 pt_o2 pt_o3 pt_o4
pt_c1 pt_c2 pt_c3 pt_c4
colval1 colval2R colval3
vp_gini vp_cv
idr_d1 idr_d2 idr_d3 idr_d4 idr_b idr_f
idg_d1 idg_d2 idg_d3 idg_d4 idg_b idg_f;
Mplus的数据文件中不包含标题行,因此我们需要在Mplus中对每列数据命名,以便后续分析时调用。
作者这里的各变量命名及含义为:
企业序号
团队规模 企业年销售收入 团队任职年限异质性 团队年龄异质性 团队教育程度异质性 团队性别异质性
团队平均任职年限 团队平均任职年限的平方 基本薪酬基尼系数 基本薪酬变异系数
薪酬流程透明度1 薪酬流程透明度2 薪酬流程透明度3 薪酬流程透明度4
薪酬结果透明度1 薪酬结果透明度2 薪酬结果透明度3 薪酬结果透明度4
薪酬沟通透明度1 薪酬沟通透明度2 薪酬沟通透明度3 薪酬沟通透明度4
集体主义共同价值观1 集体主义共同价值观2R 集体主义共同价值观3
可变薪酬压缩-基尼系数 可变薪酬压缩-变异系数
发展型特殊交易请求1 发展型特殊交易请求2 发展型特殊交易请求3 发展型特殊交易请求4 利益型特殊交易请求 特殊交易请求_f
发展型特殊交易通过1 发展型特殊交易通过2 发展型特殊交易通过3 发展型特殊交易通过4 利益型特殊交易通过 特殊交易通过_f;
变量调用
USEVARIABLES = cid
num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2
bp_gini vp_gini
pt_c1 pt_c2 pt_c3 pt_c4
pt_p1 pt_p2 pt_p3 pt_p4
pt_o1 pt_o2 pt_o3 pt_o4
idr_d1 idr_d2 idr_d3 idr_d4
idr_b
idg_d1 idg_d2 idg_d3 idg_d4
idg_b;
上一步骤是对所有数据列进行命名,而我们在具体分析时并不会都用到,所以这里需要告诉软件,我们会用到哪些列。
作者这里省略了bp_cv、vp_cv、idr_f 等无关列。
变量层级
CLUSTER = cid;
WITHIN = ;
BETWEEN = num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2
bp_gini vp_gini
pt_c1 pt_c2 pt_c3 pt_c4
pt_p1 pt_p2 pt_p3 pt_p4
pt_o1 pt_o2 pt_o3 pt_o4
idg_d1 idg_d2 idg_d3 idg_d4
idg_b;
因此是跨层模型,所以还需要告诉软件,以哪个变量划分组织、组内?又有哪些变量是组间层次?哪些变量是组内层次?
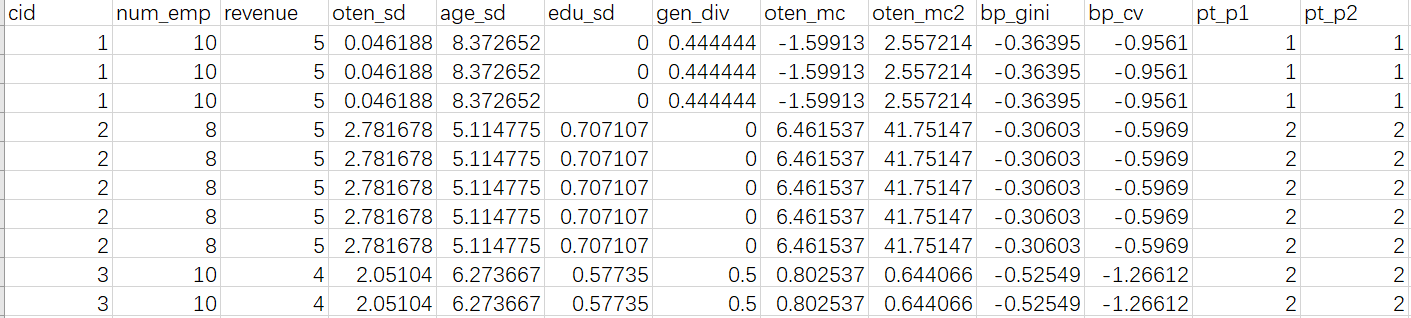
作者这里定义了组间变量,未在组间层次出现的变量即可分解为组间变量也可分解为组内变量。
分析设置
ANALYSIS:
TYPE = twolevel random;
ALGORITHM=INTEGRATION;
Integration=montecarlo;
Processor = 8;
第一行指定了分析数据的类型为两层随机效应模型,即在不同层次之间存在随机变异。
第二行指定了分析所使用的算法为积分法(Integration),即对模型的似然函数进行积分计算,得出相应的参数估计值和标准误。
第三行指定了对于积分法的具体实现方法,这里采用蒙特卡罗模拟(Monte Carlo)方法进行计算。
第二、三行涉及针对调节效应的计算。
第四行指定了所使用的处理器数量为8,这是指定Mplus在计算过程中可使用的最大处理器数量。这可以提高计算速度和效率,特别是对于较大的数据集和复杂的模型。
Processor参数可以设置为任何大于1的正整数,以指定Mplus在计算过程中可使用的最大处理器数量。具体来说,Processor参数可以设置为计算机的实际处理器核心数量,以最大化计算速度和效率。
测量模型
MODEL:
%BETWEEN%
pt_pd by pt_c1 pt_c2 pt_c3 pt_c4;
pt_od by pt_p1 pt_p2 pt_p3 pt_p4;
pt_cd by pt_o1 pt_o2 pt_o3 pt_o4;
pt by pt_pd pt_od pt_cd;
薪酬透明度由于是一个多维变量,所以进行了两次潜变量的生成。
作者先根据12道题得分(观测变量)生成了3个子维度得分(潜变量),再由这3个子维度得分生成了最终得分(潜变量)。
colvalb by colval1 colval3;
colval1@0 colval3@0;
idr_db by idr_d1 idr_d2 idr_d3 idr_d4 ;
idr_bb by idr_b;
idr_d1@0 idr_d2@0 idr_d3@0 idr_d4@0 ;
idr_b@0;
idg_db by idg_d1 idg_d2 idg_d3 idg_d4;
idg_bb by idg_b;
idg_b@0;
在Between层生成其他的潜变量。
idr_b@0意为将idr_b的方差固定为0
[vp_gini idr_db idr_bb idg_db idg_bb];
[idr_d1@0 idr_d2@0 idr_d3@0 idr_d4@0 idr_b@0];
[idg_d1@0 idg_d2@0 idg_d3@0 idg_d4@0 idg_b@0];
[vp_gini idr_db idr_bb idg_db idg_bb]是指估计这些变量的截距。
int2 | colvalb xwith vp_gini;
该句含义为,将colvalb与vp_gini的交互项定义为int2。
colvalb (w);
该句含义为,将colvalb的方差定义为w,后续计算效应量时会用到。
%WITHIN%
idr_dw by idr_d1 idr_d2 idr_d3 idr_d4 ;
idr_bw by idr_b ;
idr_b@0;
在组内层次估计由员工汇报的变量,后续结构模型的分析中不会用到。
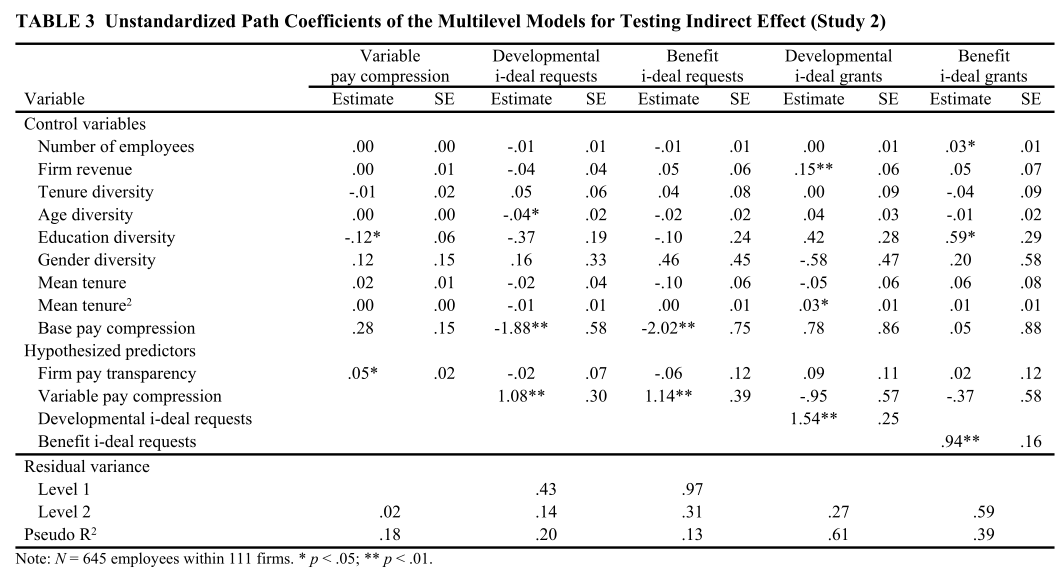
结构模型
MODEL:
%BETWEEN%
vp_gini on num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2 bp_gini
pt(a);
idr_db on num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2 bp_gini
pt
vp_gini (b1_1)
colvalb
int2 (b1_3);
idr_bb ononnum_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2 bp_gini
pt
vp_gini (b2_1)
colvalb
int2 (b2_3);
idg_db on num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2 bp_gini
pt vp_gini idr_db (c1);
idg_bb on num_emp revenue oten_sd age_sd edu_sd gen_div oten_mc oten_mc2 bp_gini
pt vp_gini idr_db (c2);
idr_bb with idr_db;
idg_bb with idg_db;
这里跟着Between部分的测量模型之后,萜妹为了表达清晰才重写了次“MODEL: %BETWEEN%”,实际上是不需要重复的。
作者利用on语句,根据模型定义了多个回归关系,并对部分回归参数命名。
如将pt对vp_gini的回归系数命名为了a。
MODEL CONSTRAINT:
NEW(id_d_h, id_d_l, id_d_diff,
id_b_h, id_b_l, id_b_diff,
ss_d_h, ss_d_l, ss_d_diff,
ss_b_h, ss_b_l, ss_b_diff);
id_d_h=a*(b1_1+b1_3*sqrt(w))*c1;
id_d_l=a*(b1_1-b1_3*sqrt(w))*c1;
id_d_diff=id_d_h-id_d_l;
id_b_h=a*(b2_1+b2_3*sqrt(w))*c2;
id_b_l=a*(b2_1-b2_3*sqrt(w))*c2;
id_b_diff=id_b_h-id_b_l;
ss_d_h=b1_1+b1_3*sqrt(w);
ss_d_l=b1_1-b1_3*sqrt(w);
ss_d_diff=ss_d_l-ss_d_h;
ss_b_h=b2_1+b2_3*sqrt(w);
ss_b_l=b2_1-b2_3*sqrt(w);
ss_b_diff=ss_b_l-ss_b_h;
在model constraint部分,新生成了一些变量。具体的数据关系在下面根据等式定义。
注意这里的sqrt(w),就是我们常说的调节变量的标准差。
输出结果
OUTPUT:
CINTERVAL tech1 tech3 tech5 tech8;
结果解读
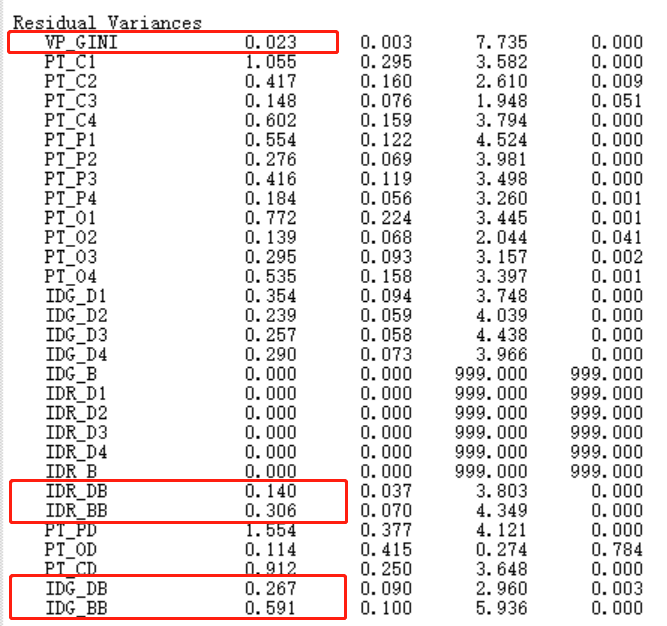
组内残差

回归系数
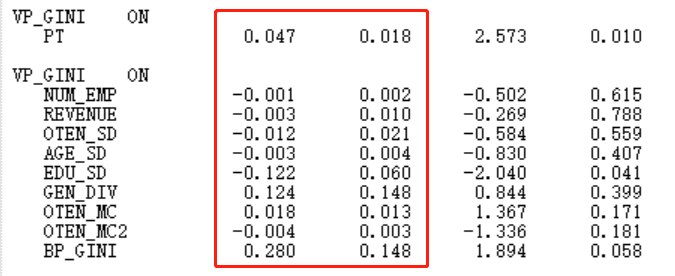
组间残差
Pseudo R2

Pseudo R2没办法直接得出,还需要进一步计算。作者文中给出了参考文献,但萜妹还没来得及溯源,所以这里就不展开。有兴趣的小可爱可以先自行研究。
Snijders, T. A. B. & Bosker, R. J. 1994. Modeled variance in two-level models. Sociological Methods & Research, 22(3): 342-363
Bootstrap置信区间

跨层Bootstrap没有办法在Mplus中实现,作者还是借助了R软件进行。
这篇推送的分析就到这里啦。因为作者只提供了Mplus部分结果,所以萜妹的复现也仅局限在Mplus之中。我这里的结果看起来比较简单,但作者在文章中其实还进行了很多补充分析,大家可以利用作者的数据与语法进行深度地复现。
另外想谈谈我为什么选择复现这篇。第一个的原因是我想找一篇公开了语法、数据的跨层文章,我在AMJ上按时间顺序找最新录用,这篇是时间最新的文章(也已经是半年之前了);第二个原因,虽然我们常常用Mplus做结构方程模型检验,但也常有不规范的地方,比如只写结构部分的语法,这篇文章纳入了测量部分才是比较规范的做法。
最后,我应该还会尝试继续找公开数据的跨层模型,尤其是用R分析的。小可爱们如果有看到合适的,也可以分享给我吖。
往期推送:
原文链接: