MplusAutomation:在R中调用Mplus
今天给小可爱们介绍一个R包:MplusAutomation,它帮助我实现了数据分析的 all in R。
简介
MplusAutomation 是 R 的一个软件包,可以帮助我们在 R 中调用 Mplus 自动进行潜在变量模型的估计和解释。具体来说,MplusAutomation 提供了用于创建相关模型组、运行批量模型以及提取模型参数和拟合统计数据并将其制成表格的例程。
需注意:MplusAutomation 并不等同于 Mplus,所有的模型估计还是在 Mplus 中进行。而 MplusAutomation 只是提供了方便的函数,用于与 R 中的 Mplus 进行交互,并使用熟悉的 R 数据结构处理模型输出。
事实上,MplusAutomation的大部分底层代码使用文本提取方法将 Mplus 的 Output 转换为 R 兼容的数据结构(如 data.frame 对象)。
因此,电脑中需要安装 Mplus,才能调用 MplusAutomation 中的 runModels() 或 mplusModeler() 函数来估计潜在变量模型。 Mplus 的软件下载参见:statmodel.com。
操作示例
安装与加载 R 包
install.packages("MplusAutomation")
加载是使用 install.packages() 语句完成的,仅需完成一次。
library(MplusAutomation)
加载是使用 library() 语句完成的,每次重新启动都需要重新加载。
运行编写好的 inp 文件
在进行 Mplus 分析时,最关键的两个内容为数据与输入语法。
如果我们已经编写好了数据与语法,可以直接在 MplusAutomation 中调用 runModels() 函数。
runModels("cfa_example.inp")
文件夹内会自动生成运行好的 .out 结果。
个人建议,将 data、inp 文件都放在这个 R project 的文件夹内,避免因路径不正确而带来的报错。

若想在 R 中调取此结果,可借助 readModels() 函数。
cfares <- readModels("cfa_example.out")
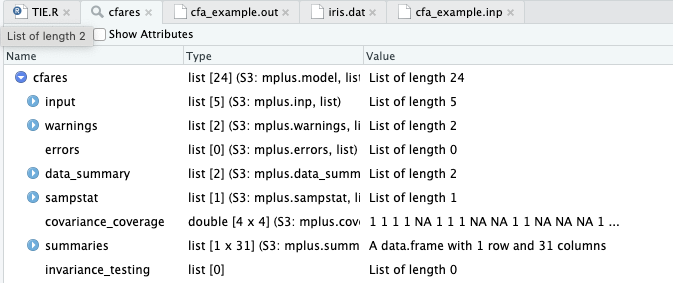
也可以利用 texreg 包优化输出。
install.packages("texreg")
library(texreg)
screenreg(cfares, cis = TRUE, single.row = TRUE, summaries = c("BIC", "CFI", "SRMR"))

将 R 中数据导出到 Mplus
prepareMplusData() 函数可以帮助我们将 R 中的数据存储成可被 Mplus 分析的样式。
Mplus 要求文件没有标题行,并且变量名称在 Mplus 输入语法中指定。
prepareMplusData() 函数可将 R data.frame 对象(在 R 中表示二维数据的典型方法)转换为可被 Mplus 兼容的制表符分隔文件,并将相应的 Mplus 语法打印出来。
然后可以将该语法粘贴到新的 Mplus 输入文件的头部。 以下是使用该命令的基本示例:
prepareMplusData(iris[, 1:4], "iris.dat")

我们也可以对语法进行调整以改变输出内容。
- [, 1:4] 意为仅输出1-4列;
- keepCols 意为输出指定列;
- dropCols 意为输出非指定列;
- 啥也不写 意味着输出所有列。
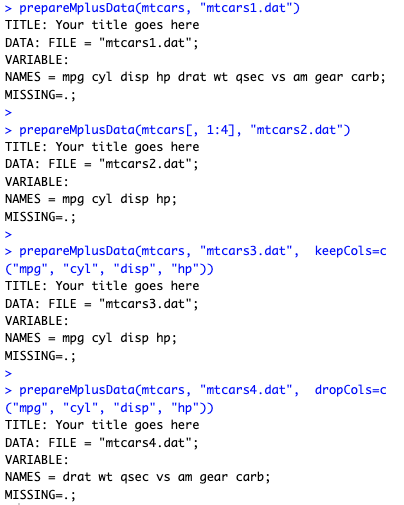
- dummyCode = c(“cyl”, “am”) 意为将变量转化为虚拟变量。

自动生成 inp、data、out 文件
我们也可以在 R 中一步到位。
mplusObject() 函数可以在 R 中创建 Mplus 模型的对象,该对象包含 inp 文件的所用部分。
pathmodel <- mplusObject(
TITLE = "MplusAutomation Example - Path Model;",
!usevariables = mpg disp hp wt;(非必需)
MODEL = "
mpg ON hp;
wt ON disp;",
OUTPUT = "CINTERVAL;",
rdata = mtcars)
fit <- mplusModeler(pathmodel, modelout = "model1.inp", run = 1L)
这就是运行 Mplus 所需的一切!
该语句中并不需要额外对变量进行命名,即不需要撰写 Mplus 中的 NAMES = ……;
MplusAutomation 会找出 R 数据集中的哪些变量在模型中使用(即出现在MODEL、VARIABLE 或 DEFINE 部分),并依此创建适合 Mplus 的数据集,调用 Mplus 在数据集上运行模型,并将其读回到 R 中。
运行结束后会生成如下结果:
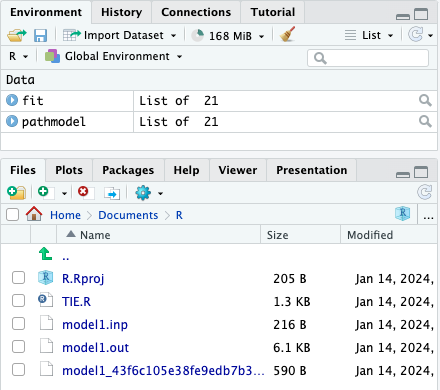
我们依旧可以在 R 中读取它,如:
screenreg(fit, summaries = c("Observations", "CFI", "SRMR"), single.row=TRUE)

还可以添加新的路径更新模型。
pathmodel2 <- update(pathmodel, MODEL = ~ . + "
mpg ON disp;
wt ON hp;")
fit2 <- mplusModeler(pathmodel2, modelout = "model2.inp", run = 1L)

将两次结果一起输出:
screenreg(list(
extract(fit, summaries = c("Observations", "CFI", "SRMR")),
extract(fit2, summaries = c("Observations", "CFI", "SRMR"))),
single.row=TRUE)

在输出中添加置信区间:
screenreg(list(
extract(fit, cis=TRUE, summaries = c("Observations", "CFI", "SRMR")),
extract(fit2, cis=TRUE, summaries = c("Observations", "CFI", "SRMR"))),
single.row=TRUE)

当然除了系数还可以输出其他的内容:

这次的推送就到这里啦。MplusAutomation 的功能和语法远不止于此,但上述的这几个语句已经完全够我们进行数据分析。
如果小可爱们感兴趣,可以在作者的 github 和文献中找到更丰富的介绍:
https://github.com/michaelhallquist/MplusAutomation
Hallquist, M. N., & Wiley, J. F. (2018). MplusAutomation: An R Package for Facilitating Large-Scale Latent Variable Analyses in Mplus. Structural Equation Modeling: A Multidisciplinary Journal, 25(4), 621–638. https://doi.org/10.1080/10705511.2017.1402334