实证研究中控制变量的选择
Hünermund, P., Louw, B., & Rönkkö, M. (2024). The choice of control variables in empirical management research: How causal diagrams can inform the decision. The Leadership Quarterly, 101845. https://doi.org/10.1016/j.leaqua.2024.101845
摘要
《领导力季刊》及更广泛的管理界均将确定因果关系作为指导有效领导力实践的首要任务。尽管已有更精细的因果识别策略可供选择,如工具变量法或自然实验法,但控制变量仍然是领导力研究中的常用策略。目前文献普遍认为,控制变量的选择应基于理论,且这些选择应该透明地报告。然而,文献中对于如何具体识别潜在的控制变量、应使用多少控制变量以及是否应纳入某个潜在控制变量,所提供的指导甚少。因此,目前的实证文献在控制变量的选择上不够透明,可能会因不良控制变量的混入而损害因果推断。因果图(Causal Diagram)为解决这些问题提供了一个透明的框架。本文为领导力和管理研究人员介绍了因果图,并提出了一套寻找合适控制变量的工作流程。
The Leadership Quarterly and the management community more broadly prioritize identifying causal relationships to inform effective leadership practices. Despite the availability of more refined causal identification strategies, such as instrumental variables or natural experiments, control variables remain a common strategy in leadership research. The current literature generally agrees that control variables should be chosen based on theory and that these choices should be reported transparently. However, the literature provides little guidance on how specifically potential controls can be identified, how many control variables should be used, and whether a potential control variable should be included. Consequently, the current empirical literature is not fully transparent on how controls are selected and may be contaminated with bad controls that compromise causal inference. Causal diagrams provide a transparent framework to address these issues. This article introduces causal diagrams for leadership and management researchers and presents a workflow for finding an appropriate set of control variables.
研究内容与研究概述
如摘要所述,在领导力研究中,控制变量是一种常用策略,但当前文献在基于理论的控制变量选择方面提供的指导甚少,因此,控制变量的选择和使用情况很少得到透明报告。
因果图,也称为有向无环图(directed acyclic graphs,DAG),为解决控制变量选择中严谨性和透明度不足的问题提供了宝贵工具。因果图是因果理论的图形化表达,介于理论的叙述表示和统计模型(即将理论表达为一组从数据中估计的统计关联)之间。与代数方法(尤其是参数化结构方程模型)不同,因果图具有完全非参数化的优势,无需对函数形式或分布做出假设。这种灵活性使其在(潜在的非线性的)回归模型的模型规范中尤为有用。图形化表达有时也有助于理解模型及其隐含的约束条件。尽管关于因果图的学术文献已存在多年,但管理和领导力研究人员大多忽视了这些模型。
本文首先概述了各种因果推断策略,以及控制变量和因果图在该领域的地位。之后,我们提出了一种控制变量的分类方法,以加深读者在分析因果图时的直观理解,并帮助区分应使用的高质量控制变量和会损害因果推断的不良控制变量。接着,我们更详细地解释了后门准则,这是使用因果图进行控制变量选择的基石。第三,我们提出了一种可用于构建此类图的工作流程,并通过复制一项关于CEO外貌与公司绩效的研究(Hopp et al., 2023)来演示该工作流程。我们还讨论了敏感性分析,这对于因果图中某些混杂变量不可观测时尤为有用。
控制变量与因果推断
确立因果关系是具有挑战性的,因为因果关系本身是不可见的(Hitchcock, 2010)。在实践中,因果关系是通过三个条件间接推断得出:1)假定原因与结果之间的关联性;2)影响的方向;3)排除其他解释(Antonakis et al., 2010)。排除解释可通过实验或观察性设计两种不同方式解决。在实验和准实验设计中,原因要么是由研究者随机化并操纵的,要么是以自然中类似的方式发生的,从而排除了竞争性的解释。观察性设计则通过抽样或统计建模考虑其他解释,包括条件分析、工具变量分析和建立唯一机制(Durand & Vaara, 2009; Morgan & Winship, 2007, p. 26)。
条件分析,即控制变量法,指的是通过保持条件变量不变消除第三方影响。例如,研究CEO性别对公司盈利能力(ROA)的影响时,需考虑行业造成的虚假效应(如,一些资产密集型行业可能以男性为主导)。对行业进行条件分析,可模拟所有公司处于同一行业的场景,消除虚假相关性。
为了有效,条件分析需要一组适当的控制变量。控制变量太少或太多都可能导致错误结论。计量经济学文献通常更侧重于遗漏变量的情况,对过度控制关注较少(Wooldridge, 2013)。并且,计量经济学文献常将整个模型视为一体,认为单个解释变量与误差项相关会导致所有OLS估计量偏差(Wooldridge, 2013)。这一观点有误,因为遗漏相关变量仅影响部分估计值,我们仍可一致估计感兴趣参数(Hünermund & Louw, 2023)。这一事实常被忽视。
因果图
要进行有效的因果推断并包含控制变量,需要对产生研究数据的因果机制做出理论假设。因果图是一个有用的框架,有助于清晰地传达这些假设(Pearl, 2009, p. 30)。因果图是结构方程模型的非参数版本,因此,它们类似于领导力学者所熟悉的路径图。接下来,我们将介绍因果图的概念,并随后利用它们来选择回归分析中的控制变量。
为了更全面地理解因果图以及因果分析,我们需要从因果识别的概念入手。在计量经济学中,“识别”一词通常指的是因果识别,即“在两个我们研究的变量之间(如果存在的话)能够分离出产生它们之间关系的因果机制”(Shaver, 2020, p. 2)。因此,因果识别不同于估计或统计推断(Morgan & Winship, 2007),它关注的是研究设计和数据是否能够独立于样本大小或数据分析方式,支持因果推断的成立。
如图1所示,因果图由代表原因和结果的圆圈,以及表示它们之间因果关系的箭头组成。
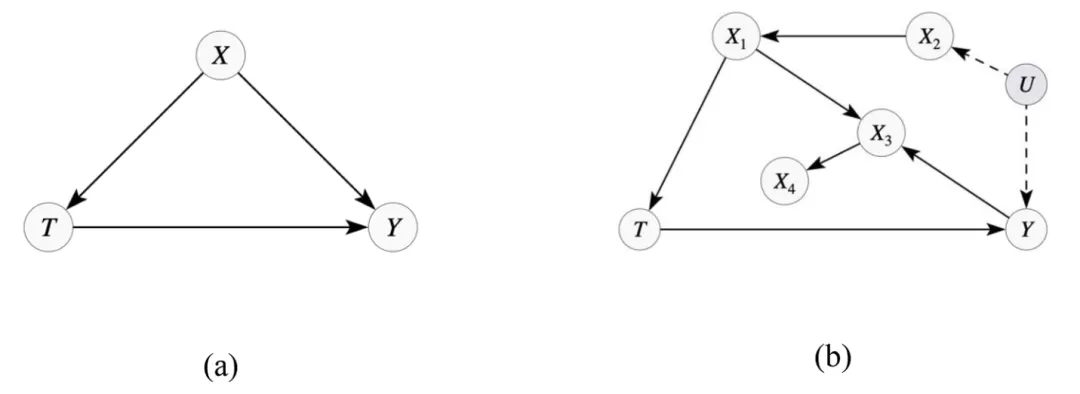 注:Y表示结果,T表示潜在原因,X是协变量
注:Y表示结果,T表示潜在原因,X是协变量
在因果分析文献中,这些圆圈被称为节点,箭头被称为边。边是有方向的,由父节点指向子节点(图1a显示了三条有向边:T→Y、X→Y和X→T)。由于因果关系是不对称的,因果图通常被假定为无环的,这意味着图中不能存在环路。这两个特性使得因果图在文献中也被称为有向无环图。
在因果图中,路径是指连接两个节点的任何一系列边。这些边不需要遵循箭头的方向。如果遵循了箭头的方向,则它们被称为有向路径。在图1a中,T和Y之间存在两条有向路径(T→Y和X→T→Y)和一条无向路径(T←X→Y)。
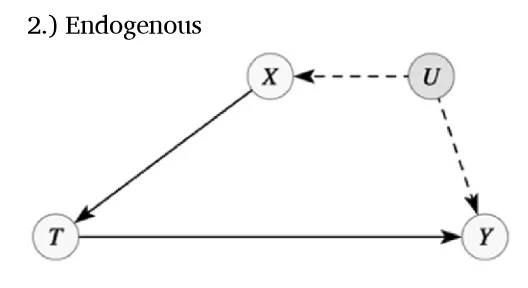
在更复杂的图1b所示的因果图中,T和Y之间有三条路径:T→Y、T←X1←X2↔Y和T←X1→X3←Y。变量U被绘制为带有虚线的阴影节点,以表示该变量未被观察到且宰数据中不可用。虽然未观测变量在大多数分析中无法使用,但应在图中包含它们,以突出可能对因果识别构成潜在威胁的因素。
因果图对于因果推断非常有用,因为它们使我们能够轻松检查变量之间的统计独立性(Kline, 2016, Chapter 8; Pearl, 1988)。为了说明这一点,请考虑图中三个节点可能存在的三种最简单的路径配置:
- 链式(Chain): A→B→C
- 叉式(Fork):A←B→C
- 碰撞式(Collider):A→B←C
在链式和叉式中,A和C统计相关。链式中,A对C有间接因果效应;叉式中,A和C因受同一父节点B影响而统计相关。以B为条件,可打破这两种相关性,使A和C条件独立(表示为:A⊥C|B,读作“在B的条件下,A与C独立”)。
- 链式中,固定B阻断影响机制,A不再影响C。例如,如果战略投资(A)仅通过销售额(B)影响公司业绩(C),那么在所有公司销售额相同的情况下,投资与公司业绩将不相关。
- 叉式中,固定B使A和C的剩余变化独立。例如,行业(B)可作为CEO性别(A)和资产回报率(C)的共同原因。
相比之下,碰撞式中,其行为则完全相反,这对于理解不良控制至关重要。在此模式中,A和C为B的父节点且独立,但固定B会在A和C间产生相关性,因为固定结果会约束原因取值。如学院录取(B)取决于SAT分数(A)和动机评分(C),整个人群中两者独立,但仅考虑被录取学生时,两者负相关。因低SAT分数者需高动机才能被录取,反之亦然。在因果图语言中,我们说以B为条件会解除或打开A和C之间的路径,使它们变得统计相关,从而导致碰撞偏差。当我们以受碰撞点因果影响的变量为条件时,这一点同样成立。中间节点阻断两个变量之间路径(并使它们条件独立)的属性被称为d分离(Pearl, 1988, p. 117)。在更复杂的因果图中也同样适用。
回到图1a中的示例模型,叉式路径T←X→Y可通过控制X来阻断。在图1b中,连接T和Y有三条路径:(1)T←X1←X2⇠U⇢Y,(2)T←X1→X3←Y,和(3)T→Y。第一条路径可以通过控制X1或X2来阻断。第二条路径由于碰撞节点X3而已经被阻断,但如果控制X3,则会变得未阻断。第三条路径才是直接因果路径:T→Y。
额外补充
在利用因果图解决控制变量选择问题之前,我们引入一个额外的概念,以使接下来的讨论更加正式。因果图是潜在结构因果模型的简洁表示。例如,图1a表示以下结构因果模型:
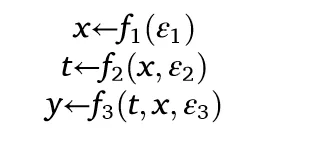
我们遵循统计和因果图文献中的通用符号,其中小写字母表示随机变量所取的具体值,而随机变量本身则用大写字母表示。结构因果模型包含四个组成部分:
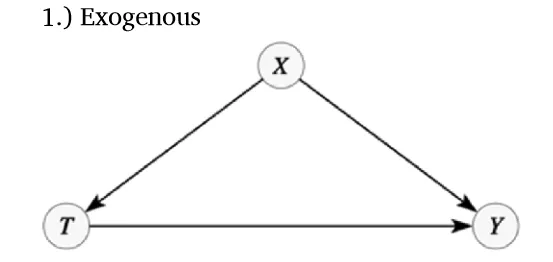
- 内生变量,这些变量是在模型内部确定的(X、T和Y;或一般表示为Vi)
- 外生情境因素,这些因素与每个变量相关联(ε1, …, εn)
- 一组函数,它们以内生变量的父节点和情境因素为参数,为每个内生变量赋值(f1,⋯, fn)
- 根据情境因素定义的概率分布
结构因果模型并非统计模型,而是一种工具,可用于表达统计模型(如结构方程模型、回归模型等)所依赖的因果假设。结构因果模型纯粹是理论性的,无需进一步指定函数fi的具体形式或背景因素εi的分布;它们仅要求对数据中的定性因果关系做出假设。相比之下,统计模型通常会对fi设定函数形式,并对εi设定分布。最常见的是线性形式和多元正态分布。有了这些背景知识,我们现在可以利用因果图来解决控制变量选择问题。在线补充材料(https://osf.io/q29fb)提供了关于因果效应和因果识别(Pearl, 2009)的更精确定义。
控制变量的分类
在提供利用图形因果模型选择控制变量的通用解决方案之前,我们先对控制变量进行分类,以便对因果图的作用机制有一个直观的了解。首先,我们将关注那些能够减少估计偏差的“好”的控制变量。随后,我们将讨论那些在使用时会导致偏差的“坏”的控制变量。基本原则是:1)控制变量应阻断任何非因果路径,同时2)避免通过控制碰撞点来阻断因果路径或开启新的非因果路径。
好的控制变量
 Model 1
Model 1
模型1中有一个完全外生的控制变量X。因为X既影响原因T,也影响结果Y,它是两者的共同父节点,形成了一个叉式结构。因此,X在非因果路径T←X→Y上引起了一个虚假的相关性,这种虚假的相关性污染了X对Y的因果效应。然而,通过在X上进行条件控制,可以阻断这条路径,恢复真正的因果效应。相应的线性因果模型是:

如果不将X作为控制变量纳入Y对T的回归分析,那么综合误差项υ将包含β₂₃x + ε₃,该误差项与T相关,因X能直接影响T。这违反了外生性假设,导致E[υ|t] ≠ 0,从而使OLS估计有偏。
为直观说明,我们设定β的各分量(β01, β02, β12, β03, β13, β23)均为1,并从标准正态分布中抽取随机背景因素εᵢ ~ N(0, 1),样本量为1000。在此设置下,若回归分析Y对T时不包含X,所得估计值有偏(50%左右)。反之,若纳入X作为控制变量,则能接近真实因果效应的估计值(见表第1列)。
 Model 2
Model 2
如果X与T或Y中的任何一个相关,情况亦然。模型2中存在未观测的共同影响因素U,影响X和Y,但X与Y间无其他因果联系。路径T←X⇠U⇢Y是叉和链的组合,可通过控制X来阻断。为此,我们在方程(2)中加入U:
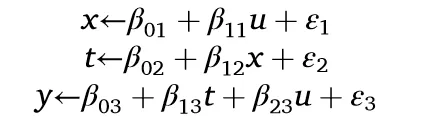
同样设定β各元素为1。若Y对T的回归未考虑X,则估计系数β(Y~T)=1.314,而纳入X将得到更接近真实因果效应的估计值(见表第2列)。
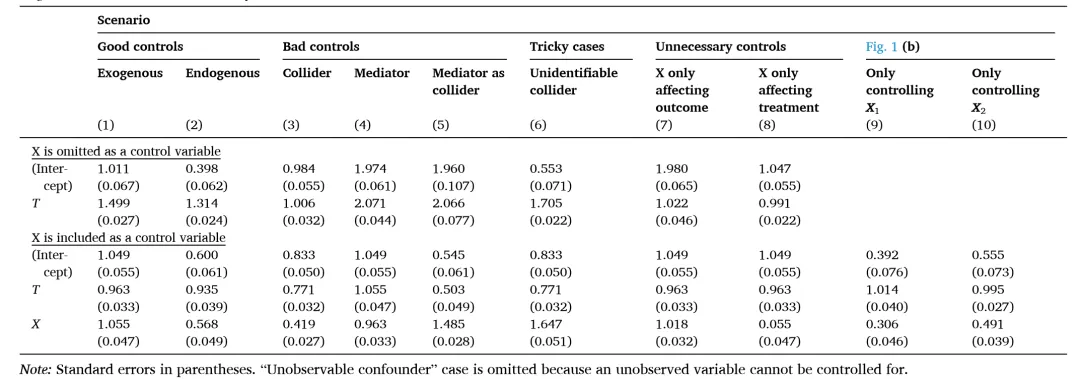
坏的控制变量
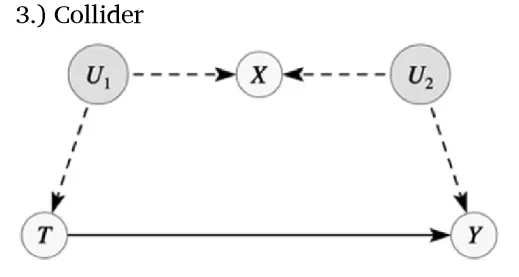 Model 3
Model 3
坏的控制变量可能通过干扰因果路径或引入非因果关联来影响因果推断。模型3展示了X虽然对T和Y均无直接因果作用,但由于存在两个未观测混杂因素U1和U2而与两者相关。由于这两个不可观察的因素都指向X,节点X是路径T⇠U1⇢X⇠U2⇢Y上的一个碰撞节点。根据d分离,X阻断了这条路径,这意味着T和Y之间的关系目前没有被混杂。但若将X作为控制变量纳入回归,则会开启此路径,引入估计偏误。
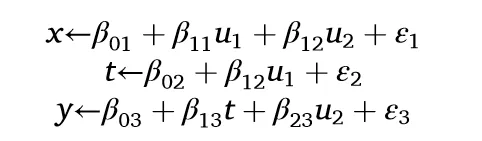
设定所有系数为1时,Y对T的直接回归能准确估计因果效应,而控制X则导致偏误(第3列)。此现象源于U2同时影响X及合并误差项υ,违反OLS的内生性假设,引发偏误估计:
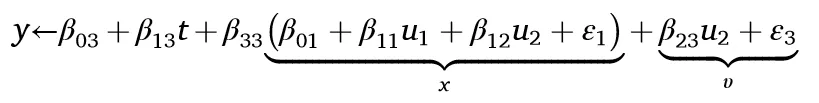
到目前为止,我们假设X是一个前因变量,即其或在T之前发生,或由与T相同的因素决定。现在我们转向模型4关注中介情况。
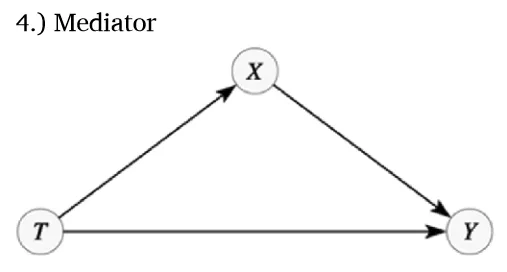 Model 4
Model 4
此时X受T的因果影响,成为结果变量。根据d分离,中介路径T→X→Y构成链,控制X将关闭此路径,阻断T至Y的传递机制,即“控制掉”部分处理效果。
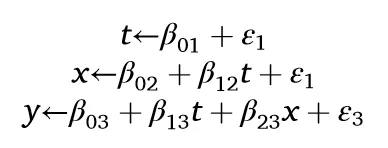
模拟数据显示,Y对T的总因果效应为直接效应与经X的间接效应之和。在我们的模拟中,它等于2(β13 + β12 • β23),且可通过Y对T的直接回归准确估计(第4列)。控制X后,估计效应减至β(Y~T|X)=1.055,仅反映T的直接效应,非总效应。区分此两者至关重要,因为路径T→Y只有在旨在解开不同因果机制的中介分析中才是感兴趣的参数,但如果目标是估计总因果效应,它将是一个错误的参数。
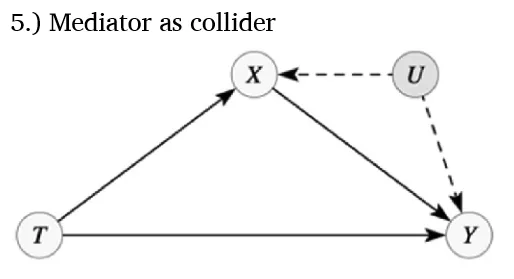 Model 5
Model 5
如果若中介X本身受到未观察变量U的混杂影响,如模型5所示,X成为路径T→X⇠U⇢Y上的碰撞节点。此时控制X将开启路径,引入T与Y间的虚假关联。
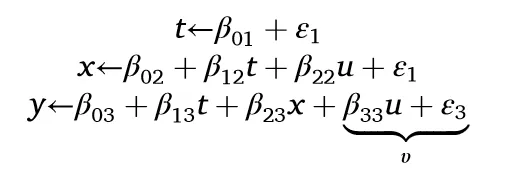
设定βi均为1时,Y对T的直接回归能正确估计总效应(第5列),而控制X则导致错误估计β(Y~T|X)=0.503,这并不对应于T或任何其他因果参数的直接影响,因为X与U相关,使E[υ|X] ≠ 0。总效应也无法通过路径追踪准确判定。因此,控制中介变量需谨慎处理。
棘手的情况
处理坏控制变量的正确方式是将其从分析中剔除。在已描述的坏控制变量案例中,通过仅回归Y和T已识别出(总)因果效应,加入X只会使分析复杂化。然而,现实模型往往更为复杂,因果识别问题难以轻易解决。
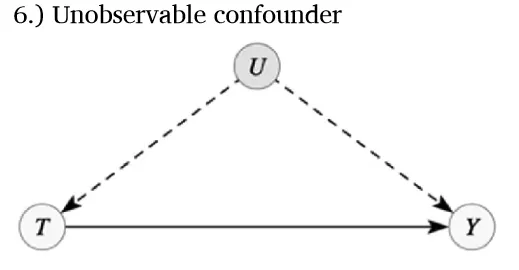 Model 6
Model 6
例如,模型6显示了一个关键混杂因素未被观测到,这在应用实证工作中很常见。此时,控制变量不足以进行因果识别,需借助其他技术,如工具变量、差异中的差异或回归不连续设计,以处理未观测因素。
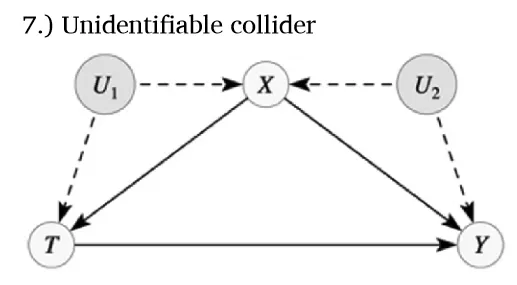 Model 7
Model 7
另一个例子是模型7,其中X既是混杂因素也是碰撞节点,控制X虽能关闭一条混杂路径,却会开启另一条路径,导致碰撞节点偏差,且此问题无解。模拟数据显示,无论是否控制X,估计值均不等于真实因果效应(第6列)。因此,这两个案例均需依赖其他因果识别方法,而非单纯控制变量。
不必要的控制变量
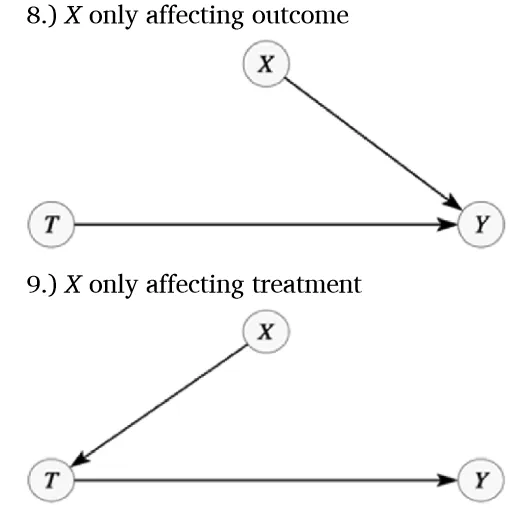 Model 8 & Model 9
Model 8 & Model 9
最后,我们简述两种情况,在这两种情况下,虽不需考虑第三个变量X进行因果识别,但X可能影响估计精确度。模型8和模型9分别显示X仅影响原因或结果,故非混杂因素,无需控制。然而,控制X仍可能对精确度有所影响。在模型8的数据模拟中,将X作为控制变量能提升精确度,表现为标准误差减小(第7列),因为X是Y对T简单回归误差项的一部分,精确度与误差项中未解释方差量相关(Wooldridge, 2013, pp. 50–54)。相反,在模型9中,控制X会导致标准误差增大(第8列),因为X是T的父节点,控制它会降低估计精确度,此即“无关回归量”现象,常见于初级计量经济学文献(Wooldridge, 2013, p. 88)。
*后门准则*
上述模型的分类有助于理解因果模型的基本原则,涵盖了研究人员常遇的情况,但并非全面。因果识别的核心在于阻断虚假路径,同时保持真实因果路径畅通。后门准则(Pearl, 2009, p. 79)正式定义了这一过程:若变量集Z对于前因T和结果Y满足后门准则,那么Z中没有T的后代节点,并且Z阻断了T和Y之间每一条含有指向T的箭头的路径。
用非技术性的话说,我们应该阻断所有指向T的箭头的路径(即,它们通过“后门”进入),保持T出发的因果链畅通。当变量集合Z对后门准则成立时,在多元回归、倾向得分匹配、逆概率加权或任何其他条件技术中控制这些变量,可以一致估计T对Y的因果效应。
给定一个因果图,找到后门可接受的变量集合是直接的。具体而言,首先列出连接T和Y的所有后门路径,然后确定阻断所有这些路径的变量,同时避免不小心打开碰撞路径。
我们使用图1b来演示这一点。T和Y之间通过三条路径连接:直接(因果)路径T→Y和两条后门路径T←X1←X2⇠U⇢Y和T←X1→X3←Y。后者被碰撞节点X3阻断,并不引起虚假相关。然而,控制X3或其后代X4将激活路径,使这两个变量成为坏控制。第一条后门路径没有碰撞节点,因此目前是开放的。这条路径可以通过控制X1或X2来阻断,这就是为什么这两个变量都满足后门准则。
后门准则引出三大控制变量原则:
- 首先,不同研究因变量对不同,后门可接受的控制变量集也不同。
- 其次,该集合无需包含所有协变量,避免引入碰撞偏差。在图1b中,控制坏控制X3和X4是一个错误;这样做会引入碰撞偏差。此外,尽管X1和X2都满足后门准则,但分析中不必全部包含,只控制一个即可提高统计精度,并允许节省数据收集成本(Witte et al., 2020)。
- 第三,回归中控制变量的系数不一定具有因果解释(Hünermund & Louw, 2023)。这是因为后门可接受的控制变量集通常不包括Y的所有原因,并且可能包含内生变量(如模型2)。
例如,根据图1b模拟的数据,尽管控制X1或X2可估计因果效应,但X1和X2的系数显著且正,并且它们在因果模型中并不直接影响Y。这表明回归结果需谨慎解释,不应直接视为因果关系(Hünermund & Louw, 2023)。
*操作流程及示例*
系统地应用因果图可以有三个目的:(1)指导控制变量的选择,(2)明确哪些变量不应被控制(即避免不良控制),以及(3)使这些决策的报告更加透明。我们建议通过三个步骤来绘制因果图,包括(1)列出变量的长名单,(2)在短名单中选择最相关的变量,以及(3)指明它们之间的因果关系。我们强调,绘制因果图是一个与数据可用性分离的概念性练习;即使相关的控制变量无法测量,也应该记录下来。这在评估研究的可信度时很重要。这对于敏感性分析和未来可能能够测量相应变量的研究也是有帮助的。为了说明我们的方法,我们复制了Hopp等(2023)发表的一篇文章。
该文章复制了Rule和Ambady(2008)关于CEO外貌与公司绩效关系的研究,他们发现从CEO面孔推断出的人格特质与公司财务绩效正相关。Hopp等人(2023)进行了概念性复制,使用资产回报率(ROA)作为结果变量,并发现CEO外貌与绩效的原始横断面关系在加入固定效应后消失。本文将使用这一背景(特别是Hopp等表3中的模型1-3)作为创建因果图的例子,并探讨先前文献中控制变量可能存在的问题。
基于先前文献列出变量
首先,进行文献综述是开发因果模型的第一步。综述应该关注(1)理论化的因果机制和(2)其他研究者在实证研究现象时考虑的变量。通过综述,我们列出了用于因果模型变量的长名单,并考虑了先前研究中可能存在的弱论证或不良控制变量。尽管这些控制变量可能不必要,但列出它们有助于记录并排除它们。同时,也要意识到先前的文献可能遗漏了重要的控制变量。因此,除了文献中的变量外,还应根据研究者的直觉进行补充。在审查相关性时,需谨慎对待,因为相关性并不等同于因果关系,也不能直接推断因果关系的缺失。然而,如果两个变量之间存在强有力的非平凡相关性证据,它应在因果图中得到考虑。
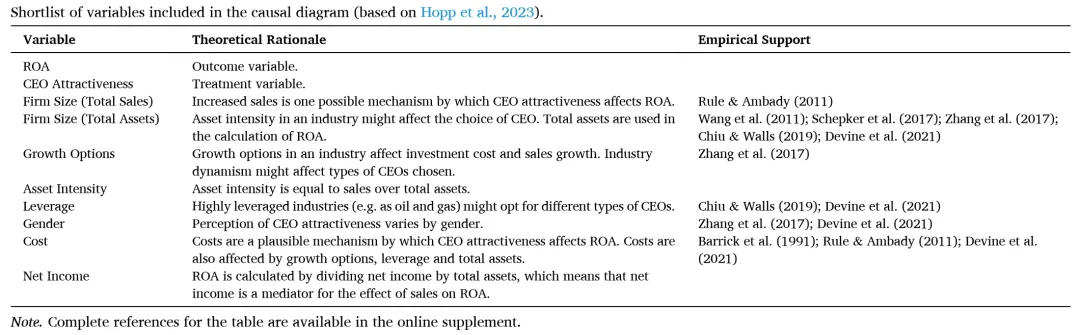
为了提供一个长名单的例子,我们回顾了使用公司绩效(特别是资产回报率或ROA)作为结果变量的战略和领导力文章。我们专注于绩效而非CEO外貌,因为除Hopp等(2023)外,鲜有研究涉及该变量。表3列出了我们的长名单,主要包括审查研究中使用的控制变量,这些变量与CEO外貌通过潜在直接因果机制或选择效应有合理联系。
为纳入模型而筛选变量
接下来,基于长名单筛选变量以形成短名单。基于之前的长名单,研究者需决定哪些变量保留在最终的因果图中,哪些排除。长名单虽包含与前因或结果相关的潜在因素,但仅同时影响两者的变量才应被选中。选择依据包括(1)坚实的理论因果理由和(2)先前文献中的经验证据强度。理论判断自然依赖于研究者的理解和情境分析。
以针对CEO外貌背景的短名单示例,我们将CEO吸引力作为前因变量。其他外貌维度的影响因素相似,故未纳入。在Hopp等(2023)的分析中,我们隐含考虑公司固定效应,仅包含时间变化变量于因果图中。此外,未纳入滞后ROA,原因有二:一是Hopp等人使用滞后变量以控制前一年事件,但这在因果模型中,滞后ROA不被视为当前ROA的直接原因;二是固定效应模型中纳入滞后结果变量易导致动态面板偏差(Dishop & DeShon,2022)。因此,为避免偏差并保持示例简洁,我们未将ROA滞后值列入短名单。
绘制因果图
最后,根据短名单绘制因果图,将变量作为圆圈(节点)绘制,并用箭头(边)连接它们,遵循假设的因果关系。本文的因果图显示了成本、净收入等未观察到的变量,并考虑了未观察到的共同父节点的存在。根据因果图,我们选择了控制变量,并发现Hopp等(2023)控制销售是有问题的,因为销售是ROA影响的中介变量,是一个不良控制。同时,资产强度也是一个不必要的控制,因为它不位于连接CEO外貌和绩效的后门路径上。
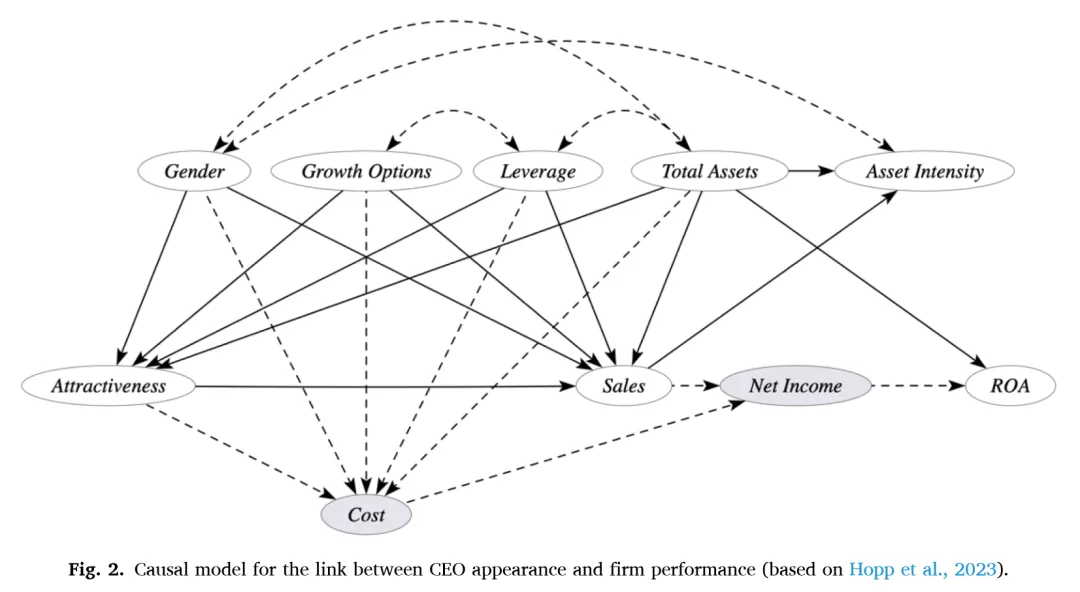
本文的因果图显示了成本、净收入等未观察到的变量,并考虑了未观察到的共同父节点的存在。根据因果图,我们选择了控制变量,并发现Hopp等(2023)控制销售是有问题的,因为销售是ROA影响的中介变量,是一个不良控制。同时,资产强度也是一个不必要的控制,因为它不位于连接CEO外貌和绩效的后门路径上。
后续内容考虑到时间原因就不展开了。
本篇推送就到这里啦,萜妹学到了很多,希望对小可爱们也有所帮助。