LPA+QCA丨两种方法的对比
区别于以变量为中心的研究方法,潜在剖面分析与定性比较分析均是以人或案例为中心的新思路。然而两种方法又有何异同?如何选择?今天分享的文章或许能够解答。
Gabriel, A. S., Campbell, J. T., Djurdjevic, E., Johnson, R. E., & Rosen, C. C. (2018). Fuzzy Profiles: Comparing and Contrasting Latent Profile Analysis and Fuzzy Set Qualitative Comparative Analysis for Person-Centered Research. Organizational Research Methods, 21(4), 877–904. https://doi.org/10.1177/1094428117752466
整体介绍
摘要
以人为中心的研究方法可以为组织学者提供关于如何独特地结合相关构念来预测结果的重要见解。在微观主题中,学者们已经开始采用潜在剖面分析(latent profile analysis, LPA),识别与组织承诺、离职意向、情绪劳动、恢复和幸福感等相关的构念组合。相反,宏观学者采用模糊集定性比较分析(fuzzy set qualitative comparative analysis, fsQCA)来研究许多现象,如并购和商业战略,将其视为与公司层面结果相关的解释性条件的组态。然而,目前尚不清楚的是,当这两种方法应用于同一主题时,它们提供了多少相似或独特的见解。在本文中,作者概述了这两种方法的异同,并通过将LPA和fsQCA应用于研究多维人格构念——核心自我评价(CSE)与工作满意度的关系来提供实证演示。通过这样做,作者为那些正在选择这两种方法之间,或试图以互补、理论构建的方式使用这两种方法的学者提供指导。
Person-centered approaches to organizational scholarship can provide critical insights into how sets of related constructs uniquely combine to predict outcomes. Within micro topics, scholars have begun to embrace the use of latent profile analysis (LPA), identifying constellations of constructs related to organizational commitment, turnover intentions, emotional labor, recovery, and well-being, to name a few. Conversely, macro scholars have utilized fuzzy set qualitative comparative analysis (fsQCA) to examine numerous phenomena, such as acquisitions and business strategies, as configurations of explanatory conditions associated with firm-level outcomes. What remains unclear, however, is the extent to which these two approaches deliver similar versus unique insights when applied to the same topic. In this paper, we offer an overview of the ways these two methods converge and diverge, and provide an empirical demonstration by applying both LPA and fsQCA to examine a multidimensional personality construct—core self-evaluations (CSE)—in relation to job satisfaction. In so doing, we offer guidance for scholars who are either choosing between these two methods, or are seeking to use the two methods in a complementary, theory-building manner.
研究问题
本研究想解决的研究问题是:LPA与fsQCA得出的结论是否相同?学者如何以互补的方式利用 LPA 和 fsQCA?
在两个研究领域中,人们很少了解哪种方法更适合回答特定的研究问题,或者如何结合这些方法。进而衍生出几个新的问题:
- 这两种方法是否遵循相似的基本理论假设(例如,识别亚群体)和分析方法(例如,剖面/组态与关键变量分离)?
- 是否可以用LPA和fsQCA来解决相同的研究问题?
- 如果使用LPA和fsQCA分析相同的数据,研究人员是否会得出相同的结论,即哪些构念的组合或组态对员工和组织产生最优结果?
基本概念
在回答上述问题之前,需要先了解这两种以人/案例为中心的方法。
以人为中心 VS 以变量为中心
与以变量为中心的方法(例如回归、方差分析)相比,以人为中心的分析方法使研究人员能够了解变量如何在个体内协同运作。
以人为中心的方法的目标是识别具有某些特征的个人,并确定这些不同的个人群体中的前因和结果是否以及如何存在差异(Wang & Hanges, 2011)。
这与现实情境更加一致,例如组织在决定雇用或晋升谁时,更多地将候选人作为一个整体考虑,而非孤立地考虑个体特征(De Fruyt, 2002)。
最早期的以人为中心的研究方法是聚类分析,但传统的聚类分析具有两大缺陷:
- 没有正式的标准来帮助研究人员确定最佳拟合解
- 强迫样本中的个体只属于一个聚类
随着研究方法的发展,微观与宏观领域均出现了新的研究方法。
潜在剖面分析
LPA允许研究人员通过对数据中存在的未观察到的异质性建模来确定样本中存在的构念组合(for recent reviews of LPA, see J. P. Meyer & Morin, 2016; Morin, Meyer, Creusier, & Bie´try, 2016; Morin & Wang, 2016; Wang & Hanges, 2011)。
LPA的优点在于:
- 第一,考虑了聚类可能出现的错误。虽然一个人可能有很高的可能性属于一个剖面,但他/她也可能被分配到另一个剖面。
- 第二,可以反映质量上的不同,得到反映了个体在每个指标上的相对地位有所不同的剖面。例如,如果检查了四个构念,一个剖面中人们在一个剖面指标上很高,在其他所有剖面指标上很低;另一个剖面中人们在两个剖面指标上很高,在其他剖面指标上很低。
LPA的应用:
- 【前因】在确定了一个剖面后,研究人员可以检查前因变量如何预测剖面(即,高/低的前因变量是否使人们更有可能属于特定的剖面;Vermunt, 2010)。
- 【结果】学者们还可以研究剖面在感兴趣的标准上的平均差异,或者学者所称的结果变量。
剖面可单独存在:
在LPA中,研究人员不允许前因变量和/或结果变量影响剖面结构。剖面是单独选择的,与其相关的变量无关,这意味着增加相关变量不能改变最终的剖面结构。
模糊集定性比较分析
fsQCA的分析原理:
- 定性比较分析的核心为集合论(Smithson & Verkuilen, 2006),其起源于案例分析,分析单位为案例,这些案例被概念化为集合的理论组态(set theoretic configurations)
- 模糊集定性比较分析在集合论方法中最受欢迎,因为它具有灵活性,允许多个程度的分级。在模糊集分析中,取值范围从0(完全不隶属)到1(完全隶属),中间有多个程度(例如,0.75代表“更多属于隶属”,0.25是“更多不属于隶属”)。
- 这种以非参数方法考察属性组态与结果的关系根植于布尔代数(即AND、OR、NOT运算符)
- 依赖于必要性和充分性分析,使研究人员能够发现导致特定结果或结果缺失的路径。
fsQCA的特点:
- 等效性:结果可能由多条不同的组态引起的
- 非对称性:导致特定结果出现的条件组合通常可能与导致结果相反的条件集合不同
【萜妹的补充】作者在文章中介绍的比较粗浅,更多说明可见: QCA合集
组态不可单独存在:
与 LPA 相比,如果不考虑结果,则不会出现组态。并且与聚类分析和 LPA 相比,与结果或其不存在一致相关的属性组态并不总是出现 。
实例:LPA VS fsQCA
为了比较上述方法的异同,作者将这两种分析技术分别应用到核心自我评价与趋近/回避动机的研究中。通过这样做,有助于可以理解当这些方法应用于相同的数据时,如何产生相似或独特的见解。
研究背景
核心自我评价是一个多维构念,其包括四种人格特征:
- 自尊:个人对自我价值的评估
- 广义自我效能感:个人对自己有效行动能力的评估
- 情绪稳定性:个人对事件反应较少的倾向,类似于低神经质
- 控制力:一个人相信自己能够影响环境以产生期望的结果的程度
尽管元分析的发现表明,这些特质是工作满意度最强的预测因素之一,相关结论已经受到质疑:
- 有学者提出CSE特质并非总能互换
- 有学者建议研究人员更加关注个体CSE特质如何组合
- 有学者认为CSE比以前的概念更广泛,包括反映自我调节能力的构念,如趋近和规避动机
研究问题
为了整合这些构念,作者专注于使用LPA和fsQCA产生的剖面/组态如何预测工作满意度。
针对LPA,作者提出:
- 研究问题1:CSE特征(自尊、广义自我效能感、情绪稳定性和控制力)和趋近、规避动机的剖面是否存在数量(即水平)和质量(即类型)的差异?
- 研究问题2:CSE特征和趋近、规避动机的剖面是否与工作满意度的关系存在差异?
针对fsQCA,作者提出:
- 研究问题3:是否存在导致工作满意度或缺乏工作满意度的必要条件?
- 研究问题4a:哪些CSE特质和趋近、规避动机的组态被认为足以实现工作满意度?
- 研究问题4b:哪些CSE特质和趋近、规避动机的组态被认为足以导致缺乏工作满意度?
样本与测量
略
结果
潜在剖面分析
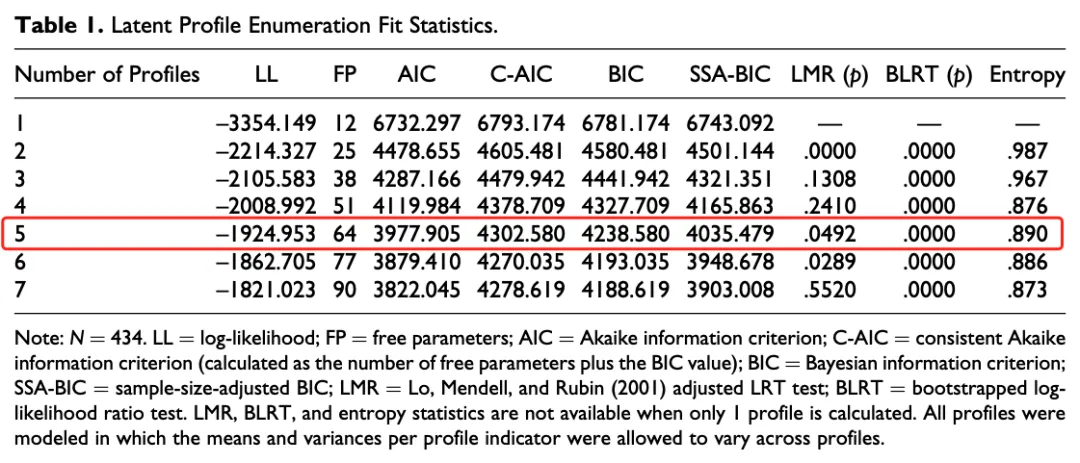
依据表1的各项指标,可以发现分类为5时,拟合最优。AIC、C-AIC、BIC、SSA-BIC均小于分类为2、3、4的相应值,LMR、BLRT的显著性<0.05,熵值大于分类为4、6、7的熵值
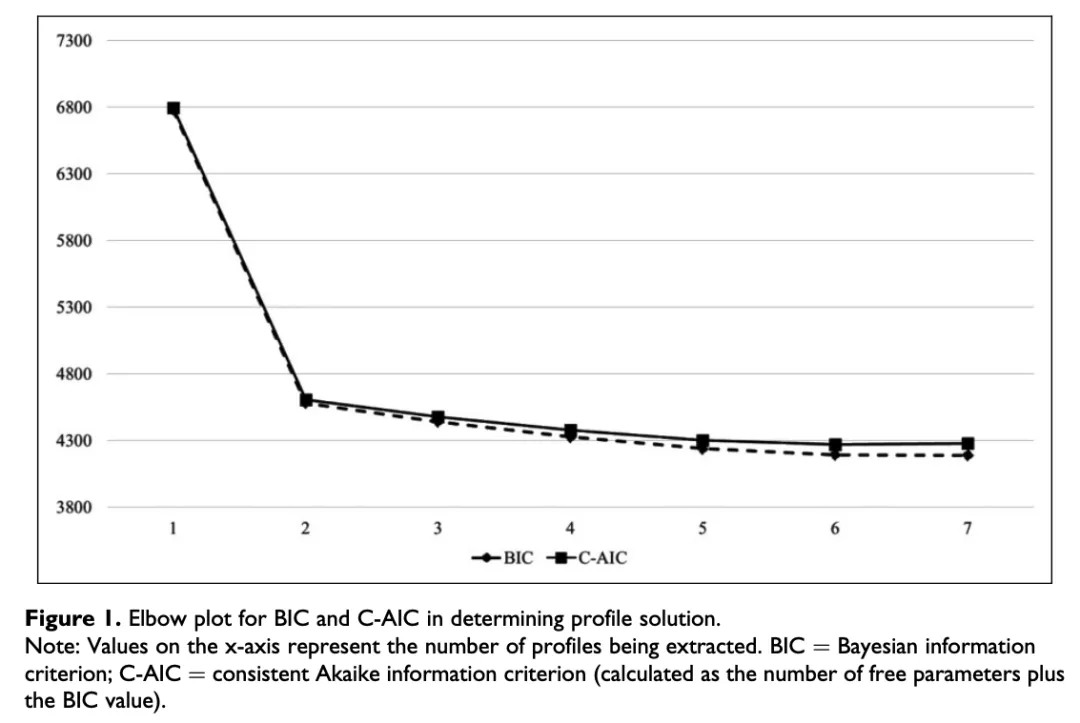
坡度在五剖面线附近逐渐变细,表明模型更适合
计算各类型的描述性信息并命名
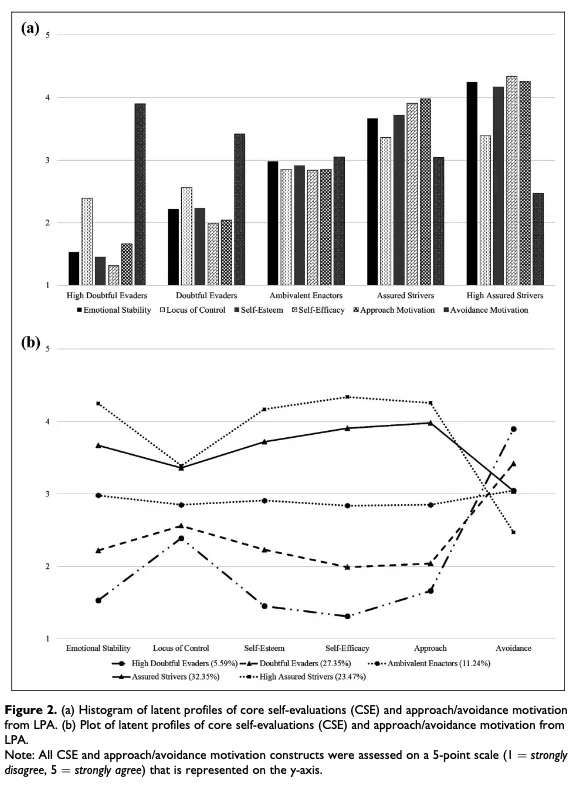
- 研究问题1:CSE特征(自尊、广义自我效能感、情绪稳定性和控制力)和趋近、规避动机的剖面是否存在数量(即水平)和质量(即类型)的差异?
回答:存在差异。
- 研究问题2:CSE特征和趋近、规避动机的剖面是否与工作满意度的关系存在差异?
回答:在潜在剖面中,工作满意度存在显著的平均差异,其中具有更高水平的情绪稳定性、自尊、自我效能感和趋近动机,相对较低的控制力,以及最低水平的规避动机时,工作满意度最高。
模糊集定性比较分析
必要性分析
- 研究问题3:是否存在导致工作满意度或缺乏工作满意度的必要条件?
回答:存在。趋近动机是工作满意结果的必要条件。
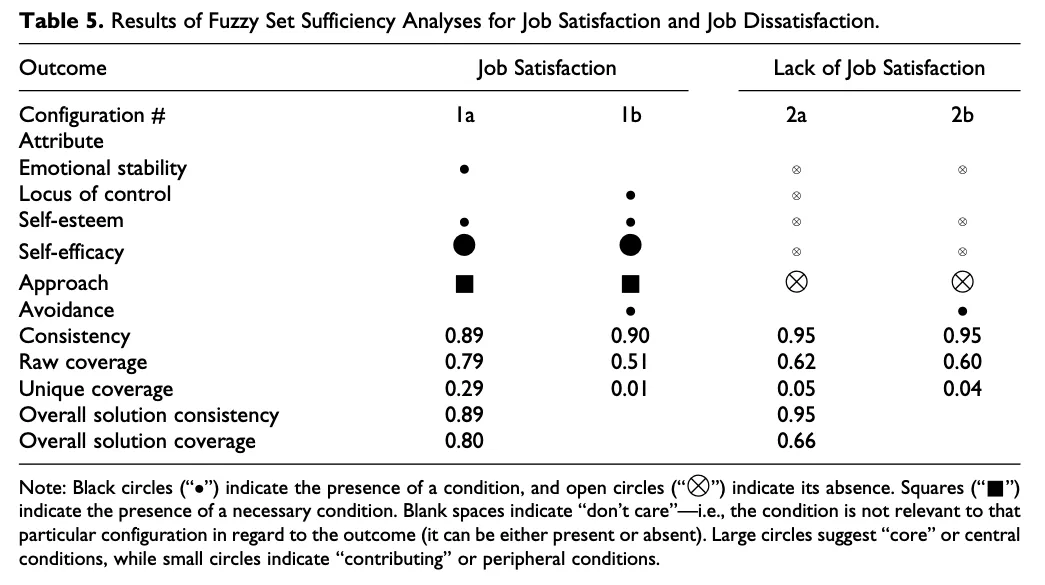
- 研究问题4a:哪些CSE特质和趋近、规避动机的组态被认为足以实现工作满意度?
- 研究问题4b:哪些CSE特质和趋近、规避动机的组态被认为足以导致缺乏工作满意度?
回答:如图所示。
结论对比
在两种分析方法中,“最佳”剖面或组态均包括高水平自尊、自我效能和趋近动机
- 对于LPA结果,剖面E(高情绪稳定性、自尊、自我效能感和趋近动机、较低的控制力,以及最低水平的规避动机)表现出最高的工作满意度。
- 对于fsQCA结果,组态1a(高情绪稳定性、自尊、自我效能和趋近动机),在预测员工的工作满意度水平方面显示出了最高的独特覆盖率。
讨论
两种方法对比
这两种策略之间最明显的区别是对剖面指标或组态中的变量是如何分析处理的:在LPA中,所有剖面指标都在某种程度上包含在内,而在fsQCA中,组态中可能会有条件缺失。
fsQCA的组态1a表现为高自我效能感和趋近动机,情绪稳定性和自尊进一步有助于该组态对工作满意度的预测;控制力和规避动机不相关。
LPA中剖面E包含了所有的指标,包括相当高水平的控制力和较低水平的规避动机。
因此,fsQCA允许我们分离出预测工作满意度的关键条件,这意味着一些特征不再被表示出来,因为它们被认为不具有因果相关性。相反,LPA在最终解决方案的每个剖面中都有所有构念,尽管有些构念具有较低的水平(控 制力、规避动机)。
对应的研究问题
潜在剖面分析(LPA)可以帮助回答的问题
- 是否存在与关注的指标相关的潜在剖面?它们的特征是什么?
- 关注的指标在数量和质量上是否有不同的潜在剖面?
- 某些前因是否可以预测剖面成分?换句话说,某些前因是否会增加属于某一特定潜在剖面的可能性?
- 潜在剖面是否表现出不同程度的远端结果?
模糊集分析(fsQCA)可以帮助回答的问题
- 我们的数据中,理论上可能存在哪些特征(属性或条件)的组态,哪些不存在?
- 哪些组态经常代表我们数据中的案例 (即隶属于一个特定组合的个体数量),哪些组态较少?
- 是否存在使结果发生(或不发生)的因果必要条件?
4a. 哪些条件或条件组合导致结果发生?
4b. 哪些条件或条件组合导致结果不发生?
对比总结
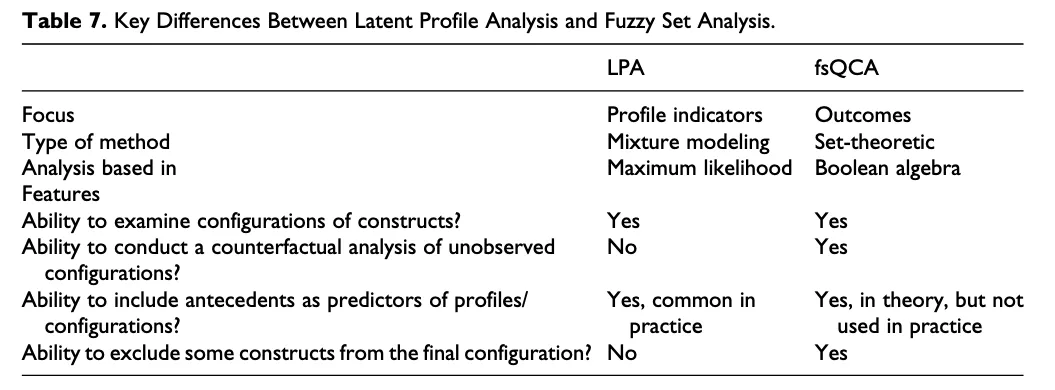
| 潜在剖面分析 | 定性比较分析 | |
|---|---|---|
| 关注点 | 先关注指标组合, 再关注组合的前因或结果 | 先识别结果变量, 再关注存在或不存在时的组合 |
| 分析类型 | 混合建模 (Mixture modeling) | 集合理论化 (Set-theoretic) |
| 分析原理 | 最大似然估计 | 布尔运算 |
| 特征 | ||
| 能否检查变量间的组合? | 可以 | 可以 |
| 能否对未观察到的案例进行反事实分析? | 不可以 | 可以 |
| 能否探讨剖面/组态的前因? | 可以 | 理论上可以,但没有相关实践 |
| 能够从最终配置中排除一些变量 | 不可以 | 可以 |
方法选择依据
两种方法如何选择取决于以下问题:
- 我们是更感兴趣的是检查指标的组合,还是我们更专注于识别一个关键结果,然后确定可能在配置中组合以产生该结果的组态?(前者选LPA,后者选QCA)
- 我们是否关注组合的前因?(关注则选LPA)
- 我们是否希望所有的指标都在组合中出现?(是选LPA,否选QCA)
- 我们是否对潜在的因果不对称感兴趣?(是选QCA,否选LPA)
这篇推送就到这里啦。数据操作部分略过了,有兴趣的小可爱可以看看之前的推送。